标签:trie names nmon RoCE 应用 sso subclass oid lis
前文介绍了Spring中的BeanDefinition的细节,随着Spring的启动流程,这节我们介绍Spring的后续处理过程 — Spring的扩展点:
Spring框架的设计的优异自不用说,使用者应该都深有体会。作为应用开发者,通常需要扩展Spring的处理,但是不必实现ApplicationContext或者扩展其子实现,如:ClassPathXmlApplicationContext。Spring提供了多处容器扩展点,只要实现扩展点将其插入到Spring上下文中即可。开发者只需要关注自己扩展的逻辑,对于如何扩展完全是沙箱,不用关注,非常友好。
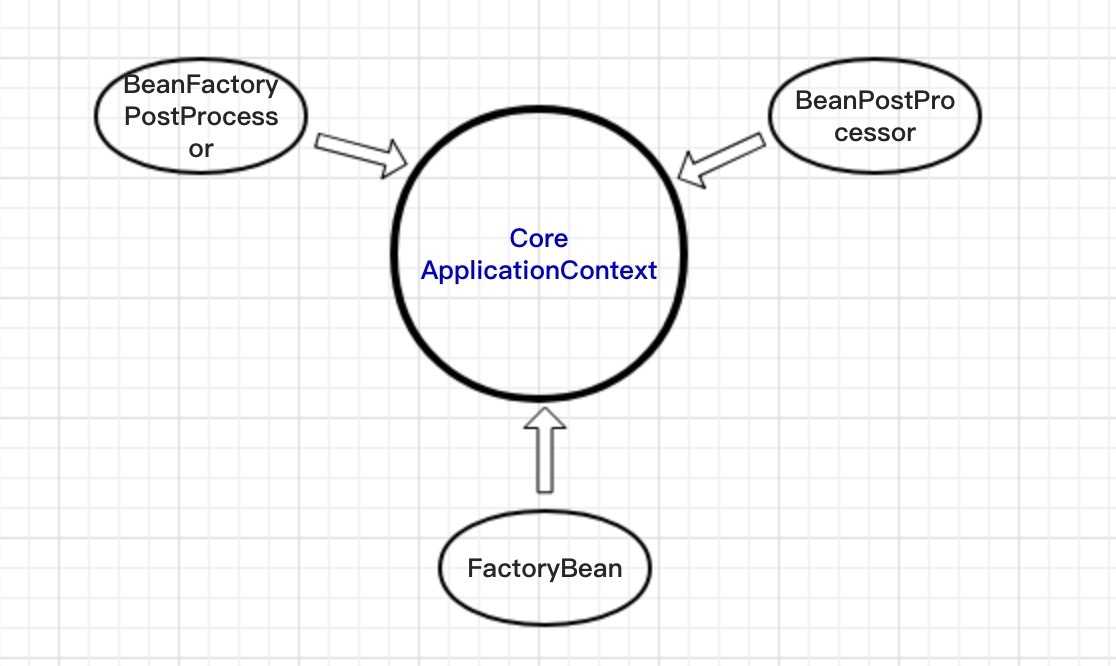
上图展示了Spring的容器扩展体系,符合微内核 + 插件体系的设计。将ApplicationContext上下文作为Spring的内核,开放插件接口,只需要实现相应插件接口即可完成扩展,提升处理能力。
有时看接口有何种作用,具有什么能力的最好方式就是看javadoc:
Allows for custom modification of an application context‘s bean definitions, adapting the bean property values of the context‘s underlying bean factory.
Application contexts can auto-detect BeanFactoryPostProcessor beans in their bean definitions and apply them before any other beans get created.
从javadoc中可以看出,BeanFactoryPostProcessor是用于自定义修改Bean定义,应用上下文可以自动检测上下文中的BeanFactoryPostProcessor,然后将其应用到其他的Bean定义上。
BeanFactoryPostProcessor接口定义的能力:
void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) 以ConfigurableListableBeanFactory作为方法参数,因为ConfigurableListableBeanFactory提供了获取BeanDefintion的能力。这样BeanFactoryPostProcessor的实现就可以自定义修改Bean定义。
BeanFactoryPostProcessor的作用用于修改Bean定义,需要满足两点:
Spring中的实现也正如此,这里承接上文中详解的BeanDefinition,当所有的BeanDefinition载入进BeanFactory后,ApplicationContext上下文将提前实例化BeanDefinition中的BeanFactoryPostProcessor的定义,将其注册为ApplicationContext中的单例,用于后续的其他Bean实例化之前处理Bean定义。整个处理过程如下图:
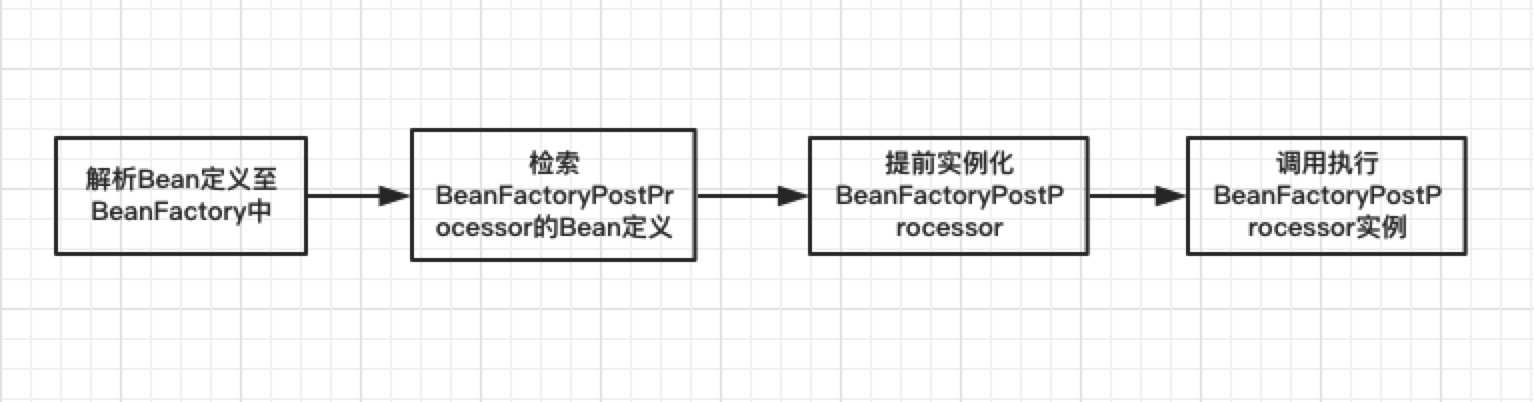
在了解BeanFactoryPostProcessor是什么和处理过程后,接下来再看Spring中如何自动检测并唤醒BeanFactoryPostProcessor。
Note:
关于自动检测的机制非常多,如JAVA提供的SPI机制。但是BeanFactoryPostProcessor并不是使用该机制,因为对Spring上下文而言,一切皆是Bean。
BeanFactoryPostProcessor也需要配置成Bean。
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
prepareRefresh();
// 前文介绍了这里的逻辑,资源的加载、Bean定义的加载
// Tell the subclass to refresh the internal bean factory.
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
prepareBeanFactory(beanFactory);
try {
// 这里是一个扩展点,用于给上下文子类扩展,非应用扩展。上下文子类可以覆盖postProcessBeanFactory
// 用于定制上下文中的BeanFactory
// Allows post-processing of the bean factory in context subclasses.
postProcessBeanFactory(beanFactory);
// 主要负责Spring容器提前注册BeanFacotryPostProcessor并唤醒的逻辑
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
... 省略
}
finally {
... 省略
}
}
}refresh模板方法中的invokeBeanFactoryPostProcessors是本节讲述的重点。invokeBeanFactoryPostProcessors中的处理逻辑也非常单一:实例化BeanFacotryPostProcessor,并调用其实例执行Bean定义的定制逻辑。
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) {
// 调用后置处理器注册委托器唤醒指定的BeanFactoryPostProcessor和BeanFactory中的BeanFactory的Bean定义
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors());
// 以下是处理load时进行aop织入处理,这里忽略
// Detect a LoadTimeWeaver and prepare for weaving, if found in the meantime
// (e.g. through an @Bean method registered by ConfigurationClassPostProcessor)
if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) {
beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory));
beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader()));
}
}PostProcessorRegistrationDelegate中是上下文对于后置处理的委托器,其中既包含BeanFactoryPostProcessor的后置处理,也包含BeanPostProcessor的注册。接下来主要分析invokeBeanFactoryPostProcessors的实现。
Tips:
在Spring中有一系列的排序和优先级接口,用于对于同类事物进行优先级和排序的设定。如:PriorityOrdered和Ordered接口分别定义。Ordered抽象了排序能力,使其实现这具有优先级。而PriorityOrdered比Ordered具有更优先的级别。
public static void invokeBeanFactoryPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) {
// 首先唤醒被给的beanFactoryPostProcessors
// Invoke BeanDefinitionRegistryPostProcessors first, if any.
Set<String> processedBeans = new HashSet<String>();
// 如果是BeanDefinitionRegistry实例
if (beanFactory instanceof BeanDefinitionRegistry) {
BeanDefinitionRegistry registry = (BeanDefinitionRegistry) beanFactory;
List<BeanFactoryPostProcessor> regularPostProcessors = new LinkedList<BeanFactoryPostProcessor>();
List<BeanDefinitionRegistryPostProcessor> registryProcessors = new LinkedList<BeanDefinitionRegistryPostProcessor>();
// 循环遍历每个BeanFactoryPostProcessor,如果是BeanDefinitionRegistryPostProcessor,则调用其后置处理方法
// 如果不是则加入regularPostProcessors中
for (BeanFactoryPostProcessor postProcessor : beanFactoryPostProcessors) {
if (postProcessor instanceof BeanDefinitionRegistryPostProcessor) {
BeanDefinitionRegistryPostProcessor registryProcessor =
(BeanDefinitionRegistryPostProcessor) postProcessor;
registryProcessor.postProcessBeanDefinitionRegistry(registry);
registryProcessors.add(registryProcessor);
}
else {
regularPostProcessors.add(postProcessor);
}
}
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
// Separate between BeanDefinitionRegistryPostProcessors that implement
// PriorityOrdered, Ordered, and the rest.
// 从beanFactory中获取BeanDefinitionRegistryPostProcessor类型且实现PriorityOrdered接口的Bean
List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<BeanDefinitionRegistryPostProcessor>();
// First, invoke the BeanDefinitionRegistryPostProcessors that implement PriorityOrdered.
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
// 加入已处理列表,防止重复执行
processedBeans.add(ppName);
}
}
// 排序currentRegistryProcessors
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
// 唤醒BeanDefinitionRegistryPostProcessor
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// 从beanFactory中获取BeanDefinitionRegistryPostProcessor类型且实现Ordered接口的Bean
// Next, invoke the BeanDefinitionRegistryPostProcessors that implement Ordered.
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
// 这里排除已经被处理的BeanDefinitionRegistry
if (!processedBeans.contains(ppName) && beanFactory.isTypeMatch(ppName, Ordered.class)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
}
}
// 排序currentRegistryProcessors
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
// 唤醒BeanDefinitionRegistryPostProcessor
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
// 最后唤醒所有的其他的非PriorityOrdered和Ordered实现的BeanDefinitionRegistryPostProcessor
// Finally, invoke all other BeanDefinitionRegistryPostProcessors until no further ones appear.
boolean reiterate = true;
while (reiterate) {
reiterate = false;
postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false);
for (String ppName : postProcessorNames) {
if (!processedBeans.contains(ppName)) {
currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class));
processedBeans.add(ppName);
reiterate = true;
}
}
sortPostProcessors(currentRegistryProcessors, beanFactory);
registryProcessors.addAll(currentRegistryProcessors);
invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry);
currentRegistryProcessors.clear();
}
// 唤醒BeanFactoryPostProcessor
// Now, invoke the postProcessBeanFactory callback of all processors handled so far.
invokeBeanFactoryPostProcessors(registryProcessors, beanFactory);
invokeBeanFactoryPostProcessors(regularPostProcessors, beanFactory);
}
else {
// 如果不是BeanDefinitionRegistry实例,则直接唤醒BeanFactoryPostProcessor
// Invoke factory processors registered with the context instance.
invokeBeanFactoryPostProcessors(beanFactoryPostProcessors, beanFactory);
}
//1. 按照BeanFactoryPostProcessor类型获取Bean工厂中的Bean名字
//2. 不过早的初始化,防止FactoryBeans被初始化
// Do not initialize FactoryBeans here: We need to leave all regular beans
// uninitialized to let the bean factory post-processors apply to them!
String[] postProcessorNames =
beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false);
// 以下逻辑就是按照bean名称逐个获取Bean,且将PriorityOrdered和Ordered分离
// PriorityOrdered优先级最高,其次是Ordered,最后是剩余部分
// Separate between BeanFactoryPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<BeanFactoryPostProcessor>();
List<String> orderedPostProcessorNames = new ArrayList<String>();
List<String> nonOrderedPostProcessorNames = new ArrayList<String>();
for (String ppName : postProcessorNames) {
// 跳过,在上述处理BeanDefinitionRegistryPostProcessor时,已经执行了该BeanFactoryPostProcessor
if (processedBeans.contains(ppName)) {
// skip - already processed in first phase above
}
else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class));
}
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
nonOrderedPostProcessorNames.add(ppName);
}
}
// 首先排序PriorityOrdered接口的试下,然后执行BeanFactoryPostProcessor
// First, invoke the BeanFactoryPostProcessors that implement PriorityOrdered.
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(priorityOrderedPostProcessors, beanFactory);
// 再排序Ordered接口的实现,然后执行BeanFactoryPostProcessor
// Next, invoke the BeanFactoryPostProcessors that implement Ordered.
List<BeanFactoryPostProcessor> orderedPostProcessors = new ArrayList<BeanFactoryPostProcessor>();
for (String postProcessorName : orderedPostProcessorNames) {
orderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
sortPostProcessors(orderedPostProcessors, beanFactory);
invokeBeanFactoryPostProcessors(orderedPostProcessors, beanFactory);
// 最后唤醒执行剩下的其他的BeanFactoryPostProcessor
// Finally, invoke all other BeanFactoryPostProcessors.
List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<BeanFactoryPostProcessor>();
for (String postProcessorName : nonOrderedPostProcessorNames) {
nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class));
}
invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory);
// 清理缓存的元数据
// Clear cached merged bean definitions since the post-processors might have
// modified the original metadata, e.g. replacing placeholders in values...
beanFactory.clearMetadataCache();
}上述的逻辑比较复杂,这里做下总结概括:
Note:
BeanDefinitionRegistryPostProcessor也是ApplicationContext的扩展点之一。它继承了BeanFactoryPostProcessor接口,但是又增强了其能力,添加了想BeanFactory中注册更多的Bean定义的能力。具体详见javadocs。
至此,关于ApplicationContext的BeanFactoryPostProcessor的扩展点的原理也就非常清晰,在加载配置的Bean定义后和实例化Bean之前,触发载入BeanFactoryPostProcessor,并唤醒执行。从源码实现上更可以清晰的看到Spring的设计:
虽然BeanFactoryPostProcessor是Spring为应用开放的扩张点,但是Spring框架本身也使用了该特征,内置了一些公共常用的BeanFactoryPostProcessor实现。本节就通过具体的BeanFactoryPostProcessor实现进一步认识它的能力。
PropertySourcesPlaceholderConfigurer是Spring 3.1为提供属性资源占位解析功能而引入,它是BeanFactoryPostProcessor的标准实现。这里不再介绍其使用细节,更多关注其实现原理。使用细节请参考Spring Framework Reference Documentation。
PropertySourcesPlaceholderConfigurer具有两大能力:
下面着重分析这两个特征。PropertySourcesPlaceholderConfigurer具有解析属性资源的能力和Environment非常相似。前文在介绍Environment时也稍微提到过,Spring中的Environment不负责解析所有的属性资源,主要是针对与环境相关的属性解析。这里再总结下:
但是Spring中还有很大一部分属性解析不在Environment的能力范畴内。如:@Value标注的属性,Bean定义中的${...}占位的属性解析替换。这些属性的解析主要由PropertySourcesPlaceholderConfigurer负责处理。
PropertySourcesPlaceholderConfigurer的属性由两部分组成:
public class PropertySourcesPlaceholderConfigurer extends PlaceholderConfigurerSupport implements EnvironmentAware {
/**
* {@value} is the name given to the {@link PropertySource} for the set of
* {@linkplain #mergeProperties() merged properties} supplied to this configurer.
*/
public static final String LOCAL_PROPERTIES_PROPERTY_SOURCE_NAME = "localProperties";
/**
* {@value} is the name given to the {@link PropertySource} that wraps the
* {@linkplain #setEnvironment environment} supplied to this configurer.
*/
public static final String ENVIRONMENT_PROPERTIES_PROPERTY_SOURCE_NAME = "environmentProperties";
// PropertySourcesPlaceholderConfigurer的属性集合
private MutablePropertySources propertySources;
// PropertySourcesPlaceholderConfigurer最终可以被使用的属性
private PropertySources appliedPropertySources;
// 环境对象
private Environment environment;
}propertySources是PropertySourcesPlaceholderConfigurer中的所有属性容器,PropertySourcesPlaceholderConfigurer通过实现EnvironmentAware将ApplicationContext中的environment注入至PropertySourcesPlaceholderConfigurer。
environment也是属性容器,PropertySourcesPlaceholderConfigurer将environment的属性转至propertySources中,propertySources即PropertySourcesPlaceholderConfigurer的所有属性集合。
PropertySourcesPlaceholderConfigurer通过实现BeanFactoryPostProcessor接口,用于处理Bean定义中的占位解析和@Value注解中的占位。下面就上述属性解析和占位解析综合分析PropertySourcesPlaceholderConfigurer的具体实现。其中主要逻辑在BeanFactoryPostProcessor的接口实现中postProcessBeanFactory:
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) throws BeansException {
// 如果propertySources集合为空
if (this.propertySources == null) {
// 创建propertySources
this.propertySources = new MutablePropertySources();
// 如果environment不为空
if (this.environment != null) {
// 将environment加入至propertySources结尾
this.propertySources.addLast(
new PropertySource<Environment>(ENVIRONMENT_PROPERTIES_PROPERTY_SOURCE_NAME, this.environment) {
@Override
public String getProperty(String key) {
return this.source.getProperty(key);
}
}
);
}
// 如果localProperties不为空,将其加入至propertySources中
try {
PropertySource<?> localPropertySource =
new PropertiesPropertySource(LOCAL_PROPERTIES_PROPERTY_SOURCE_NAME, mergeProperties());
// 如果是本地覆盖,则加载头部
if (this.localOverride) {
this.propertySources.addFirst(localPropertySource);
}
// 否则加载尾部
else {
this.propertySources.addLast(localPropertySource);
}
}
catch (IOException ex) {
throw new BeanInitializationException("Could not load properties", ex);
}
}
// 处理Bean定义和@Value中的占位
processProperties(beanFactory, new PropertySourcesPropertyResolver(this.propertySources));
// 记录实际被应用的属性
this.appliedPropertySources = this.propertySources;
}从以上逻辑中可以看出,propertySources包含了environment的属性,localPropertySource主要是应用本地配置的属性,即在配置PropertySourcesPlaceholderConfigurer时指定的属性文件:
// 将多个properties合并成单个properties
protected Properties mergeProperties() throws IOException {
// 创建单个properties
Properties result = new Properties();
if (this.localOverride) {
// Load properties from file upfront, to let local properties override.
loadProperties(result);
}
// 将本地的多个properties合并到单个properties中
if (this.localProperties != null) {
for (Properties localProp : this.localProperties) {
CollectionUtils.mergePropertiesIntoMap(localProp, result);
}
}
if (!this.localOverride) {
// Load properties from file afterwards, to let those properties override.
loadProperties(result);
}
return result;
}processProperties中主要负责解析Bean定义的占位。对于属性占位的解析由另一个组件PropertySourcesPropertyResolver负责,在Environment的文章中也介绍了,这里不再赘述。PropertySourcesPlaceholderConfigurer通过以工具的方式使用PropertySourcesPropertyResolver完成Bean定义中的占位解析。
PropertySourcesPlaceholderConfigurer利用Bean定义访问器组件访问Bean定义中的占位,然后将占位交由PropertySourcesPropertyResolver解析替换:
protected void processProperties(ConfigurableListableBeanFactory beanFactoryToProcess,
final ConfigurablePropertyResolver propertyResolver) throws BeansException {
// 分别何止占位前缀(默认值:"${")、后缀(默认值:"}")和值分割符(默认值:":")
propertyResolver.setPlaceholderPrefix(this.placeholderPrefix);
propertyResolver.setPlaceholderSuffix(this.placeholderSuffix);
propertyResolver.setValueSeparator(this.valueSeparator);
// 创建String值解析器,因为占位的都是String类型
// 其中组合使用属性解析器实现
StringValueResolver valueResolver = new StringValueResolver() {
@Override
public String resolveStringValue(String strVal) {
String resolved = (ignoreUnresolvablePlaceholders ?
propertyResolver.resolvePlaceholders(strVal) :
propertyResolver.resolveRequiredPlaceholders(strVal));
if (trimValues) {
resolved = resolved.trim();
}
return (resolved.equals(nullValue) ? null : resolved);
}
};
// 处理占位属性
doProcessProperties(beanFactoryToProcess, valueResolver);
}接下来在继续看doProcessProperties的逻辑:
protected void doProcessProperties(ConfigurableListableBeanFactory beanFactoryToProcess,
StringValueResolver valueResolver) {
// 使用解析器构造Bean定义访问器
BeanDefinitionVisitor visitor = new BeanDefinitionVisitor(valueResolver);
// 获取Bean工厂中所有的Bean名字
String[] beanNames = beanFactoryToProcess.getBeanDefinitionNames();
// 循环根据Bean名字遍历所有Bean定义,排除本身Bean定义
for (String curName : beanNames) {
// Check that we‘re not parsing our own bean definition,
// to avoid failing on unresolvable placeholders in properties file locations.
if (!(curName.equals(this.beanName) && beanFactoryToProcess.equals(this.beanFactory))) {
BeanDefinition bd = beanFactoryToProcess.getBeanDefinition(curName);
try {
// 访问Bean定义
visitor.visitBeanDefinition(bd);
}
catch (Exception ex) {
throw new BeanDefinitionStoreException(bd.getResourceDescription(), curName, ex.getMessage(), ex);
}
}
}
// 兼容处理
// New in Spring 2.5: resolve placeholders in alias target names and aliases as well.
beanFactoryToProcess.resolveAliases(valueResolver);
// New in Spring 3.0: resolve placeholders in embedded values such as annotation attributes.
beanFactoryToProcess.addEmbeddedValueResolver(valueResolver);
}主要是完成Bean定义的访问,其中访问时解析占位。需要注意的是,排除自身Bean定义,防止自身的属性文件路径中有不可解析的占位导致解析失败。PropertySourcesPlaceholderConfigurer的通过继承关系实现了BeanFactoryAware和BeanNameAware接口,从而将BeanFactory和Bean自身的名字加载进来。
其中解析的占位的核心逻辑在visitor.visitBeanDefinition(bd)中实现,主要逻辑就是遍历bean定义中的各个属性。然后交由StringValueResolver负责解析:
// 遍历访问Bean定义的各个属性,父bean名称、bean类型名称、属性值、构造参数值等等
public void visitBeanDefinition(BeanDefinition beanDefinition) {
// 访问解析父bean名称
visitParentName(beanDefinition);
// 访问解析bean类型名称
visitBeanClassName(beanDefinition);
// 访问解析工厂bean名称
visitFactoryBeanName(beanDefinition);
// 访问解析工厂方法名称
visitFactoryMethodName(beanDefinition);
// 访问解析作用域
visitScope(beanDefinition);
// 访问解析属性值
visitPropertyValues(beanDefinition.getPropertyValues());
// 按照索引方式访问解析构造参数值
ConstructorArgumentValues cas = beanDefinition.getConstructorArgumentValues();
visitIndexedArgumentValues(cas.getIndexedArgumentValues());
// 通用方式访问解析构造参数值
visitGenericArgumentValues(cas.getGenericArgumentValues());
}以上逻辑非常简单,就是遍历访问Bean定义的各个属性,然后逐个解析占位。虽然情形比较多,但是大致原理都是一样,这里选择父Bean类型名称解析和属性值解析作为重点介绍,其他的读者可以自行阅读源码
访问解析Bean类型名称
// 访问解析Bean类型名称
protected void visitBeanClassName(BeanDefinition beanDefinition) {
// 获取Bean定义的Bean类型名称
String beanClassName = beanDefinition.getBeanClassName();
// 如果Bean名称不为空
if (beanClassName != null) {
// 解析Bean名称
String resolvedName = resolveStringValue(beanClassName);
// 解析结果如果与原Bean类型名称不相等,则覆盖设置Bean类型名称
if (!beanClassName.equals(resolvedName)) {
beanDefinition.setBeanClassName(resolvedName);
}
}
}protected String resolveStringValue(String strVal) {
if (this.valueResolver == null) {
throw new IllegalStateException("No StringValueResolver specified - pass a resolver " +
"object into the constructor or override the ‘resolveStringValue‘ method");
}
// 使用解析器解析属性值
// 关于解析的细节,可以参考前篇文章中关于Environment的讲解
String resolvedValue = this.valueResolver.resolveStringValue(strVal);
// Return original String if not modified.
// 如果解析后与原值不等,则返回解析后的新值,否则返回原值
return (strVal.equals(resolvedValue) ? strVal : resolvedValue);
}访问解析属性值
// 访问解析属性值中的占位
protected void visitPropertyValues(MutablePropertyValues pvs) {
// 获取属性值数组
PropertyValue[] pvArray = pvs.getPropertyValues();
// 遍历访问每个属性值
for (PropertyValue pv : pvArray) {
// 解析属性值
Object newVal = resolveValue(pv.getValue());
// 解析后结果与原值不等,则覆盖原值
if (!ObjectUtils.nullSafeEquals(newVal, pv.getValue())) {
pvs.add(pv.getName(), newVal);
}
}
}protected Object resolveValue(Object value) {
// 如果属性值类型是BeanDefinition、BeanDefinitionHolder则简介递归调用访问bean定义方法
if (value instanceof BeanDefinition) {
visitBeanDefinition((BeanDefinition) value);
}
else if (value instanceof BeanDefinitionHolder) {
visitBeanDefinition(((BeanDefinitionHolder) value).getBeanDefinition());
}
// 如果是引用其他的Bean的属性值,直接获取引用的值,然后解析占位
// 如果解析后的值与原值不等,则重新创建新的引用属性值并返回
// 到这里,对Spring中的占位应该非常清晰了
else if (value instanceof RuntimeBeanReference) {
RuntimeBeanReference ref = (RuntimeBeanReference) value;
String newBeanName = resolveStringValue(ref.getBeanName());
if (!newBeanName.equals(ref.getBeanName())) {
return new RuntimeBeanReference(newBeanName);
}
}
// 如果是其他的Bean名称的引用的属性值,直接获取引用的bean名称,然后解析占位
// 如果解析后的值与原值不等,则重新创建新的并返回
else if (value instanceof RuntimeBeanNameReference) {
RuntimeBeanNameReference ref = (RuntimeBeanNameReference) value;
String newBeanName = resolveStringValue(ref.getBeanName());
if (!newBeanName.equals(ref.getBeanName())) {
return new RuntimeBeanNameReference(newBeanName);
}
}
// 如果是数组,则访问解析数组
else if (value instanceof Object[]) {
visitArray((Object[]) value);
}
// 如果是列表,则访问解析列表
else if (value instanceof List) {
visitList((List) value);
}
// 如果是集合,则访问解析集合
else if (value instanceof Set) {
visitSet((Set) value);
}
// 如果是映射表,则访问解析映射表
else if (value instanceof Map) {
visitMap((Map) value);
}
// TypedStringValue是针对Bean的String类型成员域的解析表示
// 如果是该类型,则获取对应的值,然后解析
// 然后覆盖旧值
else if (value instanceof TypedStringValue) {
TypedStringValue typedStringValue = (TypedStringValue) value;
String stringValue = typedStringValue.getValue();
if (stringValue != null) {
String visitedString = resolveStringValue(stringValue);
typedStringValue.setValue(visitedString);
}
}
// 如果是String类型,则直接解析
else if (value instanceof String) {
return resolveStringValue((String) value);
}
return value;
}到这里,BeanFactoryPostProcessor的原理应该非常清楚了,且对于Spring中的常用占位处理的扩展点PropertySourcesPlaceholderConfigurer的原理应该也非常清晰。接下来的内容着重介绍Spring的另一个扩展点BeanPostProcessor。
BeanPostProcessor是Bean的后置处理器,顾名思义,用于后置处理容器中的Bean。那么定然是在Spring已经实例化了Bean之后,BeanPostProcessor才得以运用。根据官方文档的描述:
The BeanPostProcessor interface defines callback methods that you can implement to provide your own (or override the container’s default) instantiation logic, dependency-resolution logic, and so forth. If you want to implement some custom logic after the Spring container finishes instantiating, configuring, and initializing a bean, you can plug in one or more BeanPostProcessor implementations.
BeanPostProcessor的功能非常强大,能够覆盖默认的实例化逻辑,定制应用需要的实例化方式,实现依赖注入的策略,等等。也可以在Spring容器完成实例化、配置、初始化Bean之后,插入自定义的BeanPostProcessor实现。
Note 1:
BeanPostProcessor是具有容器层次的。一个Spring容器中的BeanPostProcessor是无法后置处理另一个容器的Bean的。
Note 2:
需要区分BeanPostProcessor和BeanFactoryPostProcessor的区别,前者是后置处理Bean,后者是后置处理Bean定义,作用的对象不同。
Note 3:
BeanPostProcessor作为Spring容器的另一个扩展点,被插在容器实例化Bean之后的点。从这里又再次感受到,Spring容器无处不扩展的特征,在各个关键地方都预留扩展口。
谈论何处扩展需要从两个点分析:
由于在Bean实例化之后需要唤醒BeanPostProcessor逻辑,所以需要在Bean实例化之前或者实例化中定要将BeanPostProcessor实例化和初始化完成。Spring中选择在实例化其他Bean之前实例化BeanPostProcessor。BeanFactory中有持有BeanPostProcessor的列表,将存储实例化的BeanPostProcessor。在Bean实例化后唤醒BeanPostProcessor逻辑。
BeanPostProcessor中定义了两个接口:
// 实例化Bean后,初始化Bean之前处理Bean
Object postProcessBeforeInitialization(Object bean, String beanName)
// 实例化Bean后,初始化Bean之后处理Bean
Object postProcessAfterInitialization(Object bean, String beanName)这节就从BeanPostProcessor的注册和唤醒的源码实现角度分析,更进一步认识BeanPostProcessor设计。
Spring容器在实例化Bean之前需要实例化上下文中的BeanPostProcessor并将其注册至BeanFactory中,有些事Spring框架内置实现,有些事应用开发者自身的实现扩展。注册BeanPostProcessor在AbstractApplicationContext的模板方法refresh的流程中:
...省略
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
invokeBeanFactoryPostProcessors(beanFactory);
// 注册BeanPostProcessors至BeanFactory中
// Register bean processors that intercept bean creation.
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
initApplicationEventMulticaster();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
...省略注册的主要逻辑由registerBeanPostProcessors实现,其中包括实例化容器中的BeanPostProcessor,并具有优先级能力。然后将其注册至BeanFactory:
// 注册容器中的BeanPostProcessor
protected void registerBeanPostProcessors(ConfigurableListableBeanFactory beanFactory) {
// 委托PostProcessorRegistrationDelegate实现
PostProcessorRegistrationDelegate.registerBeanPostProcessors(beanFactory, this);
}Spring中后置处理器的注册都是委托PostProcessorRegistrationDelegate的实现:
// 注册BeanPostProcessor
// 包括两部分逻辑:1. 实例化BeanFactory中的BeanPostProcessor的Bean定义;2. 注册BeanPostProcessor实例至BeanFactory
// 仍然是三步骤:1.PriorityOrdered接口实现;2.Ordered的实现;3.rest部分
public static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, AbstractApplicationContext applicationContext) {
// 根据类型BeanPostProcessor获取容器中所有的Bean名称,使用false参数,禁止FactoryBean过早初始化
String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanPostProcessor.class, true, false);
// 注册BeanPostProcessor的实现BeanPostProcessorChecker记录在BeanPostProcessor实例化期间,被创建的Bean
// Register BeanPostProcessorChecker that logs an info message when
// a bean is created during BeanPostProcessor instantiation, i.e. when
// a bean is not eligible for getting processed by all BeanPostProcessors.
int beanProcessorTargetCount = beanFactory.getBeanPostProcessorCount() + 1 + postProcessorNames.length;
beanFactory.addBeanPostProcessor(new BeanPostProcessorChecker(beanFactory, beanProcessorTargetCount));
// 分三步实例化注册BeanPostProcessor。1. 实现了PriorityOrdered接口最优先实例化并注册;
// 2.再实例化并注册Ordered实现;3.最后实例化注册剩余的BeanPostProcessor
// 这里分别使用三个列表priorityOrderedPostProcessors、orderedPostProcessorNames、nonOrderedPostProcessorNames
// 来记录三种类型的BeanPostProcessor的Bean名称
// Separate between BeanPostProcessors that implement PriorityOrdered,
// Ordered, and the rest.
List<BeanPostProcessor> priorityOrderedPostProcessors = new ArrayList<BeanPostProcessor>();
List<BeanPostProcessor> internalPostProcessors = new ArrayList<BeanPostProcessor>();
List<String> orderedPostProcessorNames = new ArrayList<String>();
List<String> nonOrderedPostProcessorNames = new ArrayList<String>();
for (String ppName : postProcessorNames) {
// 实现了PriorityOrdered接口,记录到priorityOrderedPostProcessors列表中
if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
priorityOrderedPostProcessors.add(pp);
// 如果是MergedBeanDefinitionPostProcessor实现,再记录internalPostProcessors中
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
// 如果是Ordered的实现,则记录到orderedPostProcessorNames中
else if (beanFactory.isTypeMatch(ppName, Ordered.class)) {
orderedPostProcessorNames.add(ppName);
}
else {
// 剩余的记录到nonOrderedPostProcessorNames
nonOrderedPostProcessorNames.add(ppName);
}
}
// 分三步:fisrt -> PriorityOrdered, second -> Ordered, finally -> rest部分
// First, register the BeanPostProcessors that implement PriorityOrdered.
// 先排序
sortPostProcessors(priorityOrderedPostProcessors, beanFactory);
// 注册到BeanFactory中
registerBeanPostProcessors(beanFactory, priorityOrderedPostProcessors);
// Next, register the BeanPostProcessors that implement Ordered.
// 排序,然后再注册Ordered的实现
List<BeanPostProcessor> orderedPostProcessors = new ArrayList<BeanPostProcessor>();
for (String ppName : orderedPostProcessorNames) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
orderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
sortPostProcessors(orderedPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, orderedPostProcessors);
// 最后注册剩余部分的BeanPostProcessors
// Now, register all regular BeanPostProcessors.
List<BeanPostProcessor> nonOrderedPostProcessors = new ArrayList<BeanPostProcessor>();
for (String ppName : nonOrderedPostProcessorNames) {
BeanPostProcessor pp = beanFactory.getBean(ppName, BeanPostProcessor.class);
nonOrderedPostProcessors.add(pp);
if (pp instanceof MergedBeanDefinitionPostProcessor) {
internalPostProcessors.add(pp);
}
}
registerBeanPostProcessors(beanFactory, nonOrderedPostProcessors);
// Finally, re-register all internal BeanPostProcessors.
sortPostProcessors(internalPostProcessors, beanFactory);
registerBeanPostProcessors(beanFactory, internalPostProcessors);
// 最后在BeanPostProcessor的链尾再加入ApplicationListenerDetector
// Re-register post-processor for detecting inner beans as ApplicationListeners,
// moving it to the end of the processor chain (for picking up proxies etc).
beanFactory.addBeanPostProcessor(new ApplicationListenerDetector(applicationContext));
}以上的实例化注册BeanPostProcessor的策略基本和BeanFactoryPostProcessor一致,根据优先级都是分为三步骤。
其中需要注意的两点是:
internalPostProcessors主要是针对MergedBeanDefinitionPostProcessor,该接口是BeanPostProcessor的子接口,对其进行了能力增强。这里不再详细介绍。
ApplicationListenerDetector作用功能是用于检测容器中的ApplicationLisenter,将其注册到上下文中。后续再典型案例中将分析该实现原理。
这里对registerBeanPostProcessors的逻辑再深入点介绍,该方法中主要实现BeanPostProcessor注册入BeanFactory中:
// 注册BeanPostProcessor入BeanFactory中
private static void registerBeanPostProcessors(
ConfigurableListableBeanFactory beanFactory, List<BeanPostProcessor> postProcessors) {
// 循环遍历加入BeanFactory中
for (BeanPostProcessor postProcessor : postProcessors) {
beanFactory.addBeanPostProcessor(postProcessor);
}
}DefautListableBeanFactory中持有BeanFactory的列表:
/** BeanPostProcessors to apply in createBean */
private final List<BeanPostProcessor> beanPostProcessors = new ArrayList<BeanPostProcessor>();
addBeanPostProcessor是BeanFactory顶层抽象的接口:
void addBeanPostProcessor(BeanPostProcessor beanPostProcessor);ConfigurableBeanFactory定义了该接口,主要是为了添加BeanPostProcessor。到这里关于BeanPostProcessor的实现也介绍结束,它的逻辑本身并不复杂,关于何时唤醒BeanPostProcessor的逻辑,在下篇文章中填坑。这里不再赘述,因为BeanPostProcessor的调用执行涉及到Bean的创建过程,非常复杂,需要有对Bean的创建过程熟悉。
类似PropertySourcesPlaceholderConfigurer这样的方式介绍案例。BeanPostProcessor的实现分为两部分:
本篇文章主要以原理为主,这里笔者同样不再编写Demo介绍,仍以Spring中内建的实现作为案例介绍。
ApplicationListenerDetector是Spring中内置的BeanPostProcessor实现,主要是为了检测Spring容器中的的ApplicaiontListener,然后将其注册到Spring上下文中。
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
// 当上下文不为空时且该bean是ApplicationListener
if (this.applicationContext != null && bean instanceof ApplicationListener) {
// potentially not detected as a listener by getBeanNamesForType retrieval
// 如果是单例,则将该bean注册至上下文中
Boolean flag = this.singletonNames.get(beanName);
if (Boolean.TRUE.equals(flag)) {
// singleton bean (top-level or inner): register on the fly
this.applicationContext.addApplicationListener((ApplicationListener<?>) bean);
}
else if (Boolean.FALSE.equals(flag)) {
if (logger.isWarnEnabled() && !this.applicationContext.containsBean(beanName)) {
// inner bean with other scope - can‘t reliably process events
logger.warn("Inner bean ‘" + beanName + "‘ implements ApplicationListener interface " +
"but is not reachable for event multicasting by its containing ApplicationContext " +
"because it does not have singleton scope. Only top-level listener beans are allowed " +
"to be of non-singleton scope.");
}
this.singletonNames.remove(beanName);
}
}
return bean;
}ApplicationListenerDetector实现了实例化后进行后置处理的逻辑,主要就是检测ApplicationListener,然后将其加入Spring上下文中。
Note:
无论是实例化前还是实例化后的后置处理,都需要return bean。否则上下文的后续逻辑将无法处理该Bean。
本文主要介绍Spring容器中的两大扩展点,BeanFactoryPostProcessor和BeanPostProcessor。前者用于对Bean定义进行后置处理,后者用于对Spring容器中的Bean进行后置处理。虽然命名即为相似,但是作用上有根本的区别。
关于Spring中的扩展点非常多,本篇文章也只在阅读源码过程中的发现的扩展点总结,后续会有更多扩张点文章呈现。
Spring源码系列 — 容器Extend Point(一)
标签:trie names nmon RoCE 应用 sso subclass oid lis
原文地址:https://www.cnblogs.com/lxyit/p/10108543.html