标签:网络连接 sea 解释 mil complex wal 基础上 可行性 必须
论文原文:https://pan.baidu.com/s/1D1xjySQD25qaQXKMdJp7eA
1 introduction
面向服务计算(Service-Oriented Computing,SOC)在进几年广泛使用,其中web服务就是其中的基石,因为面向服务计算需要web服务封装应用功能以及提供标准接口。
一个web应有意味着需要满足用户的一系列任务,而每一个任务就可以对应到一个web服务上边,所以,在实际应用中就产生了一个不得不面对的问题,为了需要在一堆功能相当的web服务当中找到我们所需要的那一个,所以我们需要更多的关于么一个web服务的信息。
这时候就有一种比较好的方法去区分具有功能相似的web服务——服务质量(Quality of Service,QoS),包括,响应时间,吞吐量,有效性等。这时候就可以通过最优QoS,在一堆功能相近的web服务里边选择一个最优的web服务——这也就是所谓的“web服务推荐”。
在执行web服务推荐的时候,所必须要有的就是QoS,显然没有这个属性,就无法进行接下来的预测,而在实际生活中,也确实面临着这样的问题,原因如下:
1.web服务的QoS,因为服务状态(用户数目,负载等)和网络状况(带宽等)随着时间一直变化,所以与调用时间有很大的关系;
2.其次,QoS呈现典型的地理分布特征,网络连接对于QoS的性能影响很大,所以不同的用户调用同一服务可能会观察到不同的QoS性能。
至此,引出了本篇论文的主旨——为了更高质量的web服务推荐,我们设计了一个新的QoS预测算法:基于改进的协同过滤的具有时间感知以及数据稀疏容忍的web服务推荐。
协同过滤可以从以下两方面进行改进:
1.协同过滤的主要基于相似用户,相似服务,以及上边两个方法的结果综合,这个方法通过从相似用户或者相似服务中提取出必要的信息之后,对目标用户进行QoS预测,为了提高预测的准确性,一些研究提出了可以将上下文信息纳入进行考虑,但是,这些研究都没有考虑QoS的时间动态性;
2.既然协同过滤是依赖相似用户(服务)的数据进行QoS预测,那么不可避免的情况就是:web服务是成千上万的,一个用户调用的也就那么点,或者说一个服务也就被调用微乎其微的次数,这些数据很明显是难以找到足够的相似用户或者服务的,而随机游走机制可以很好的缓解数据稀疏所带来的问题;
2 related work
这一节主要大概介绍以下web服务推荐,协同过滤,以及数据稀疏问题的研究现状,然后基于此,进行我们的研究。
web服务推荐可以基于web服务的QoS属性帮助用户在功能相当的web服务中挑选出最优的那一个;
又因为QoS是未知的,所以需要协同过滤算法进行QoS预测;
其中,协同过滤算法主要分为以下两种:基于邻居(neighborhood-based),基于模型(model-based);
在本篇论文中,因为前者更加直观地解释了服务推荐的结果,所以是采用了前者作为研究;
而前者又可以细分为以下三类:基于用户(used-based),基于服务(item-based),混合以上两种方法(hybrid);
以下是它们的定义:
- used-based:The used-based method utilizes historical QoS experience from a group of similar users to make QoS prediction.
- item-based:The item-based method uses historical QoS information from similar sevices for QoS prediction.
- hybrid:The hybrid approach is the combination pf the user-based and service -based methods, which can achieve a higher QoS prediction accuracy.
而在协同过滤算法研究中,即使为了提高QoS预测的准确度,考虑了上下文信息,但是依旧忽视了时间信息的影响(since QoS performance of web service is highly related to some time-varying factor (e.g., service, network condition, etc. ))
协同过滤还有不可忽视的一个短板就是,数据稀疏的问题;
为了解决这个问题,采用了一个随机游走的改进算法:
大致操作如下:
1. 分别构建用户图,服务图,其中节点表示(用户、服务),边上的权值表示(两个用户、服务)之间的相似性;
2. 在两个图上分别执行随机游走算法;
3. 最后发现相似用户,相似服务,获得更多的历史信息;
4. userd-based,service-based的结果结合起来,进行更加准确的预测;
3 problem and approach overview
3.1 problem statement

U={u1,u2...um}表述用户集合;
S={s1,s2...sn}表示服务集合;
以m*n矩阵表示用户服务之间的关系,每一项是(qij,tij),分别表示ui调用sj时候的QoS,以及对应的时间戳;
当目标用户提出功能要求的时候,web服务推荐不仅需要提供一个满足要求的web服务,还需要是所有web服务候选中最优的那一个;
因此,缺失的QoS值qij需要在每一次服务调用时进行预测(the missing QoS value qij should be predicted for each pair (ui, sj) (sj is a candidate web service) at the current time tcurrnet, based on the historical QoS information contained in Q.)
3.2 overview of our approach
为了解决上述问题,所以我们提出一个新的算法,算法执行流程如下图所示:
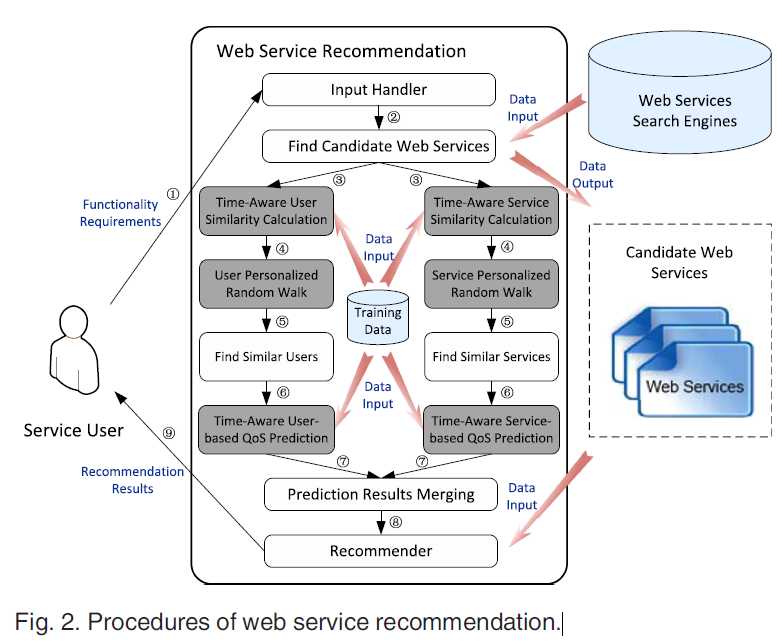
1. 目标用户通过input handler 提出他的功能要求,从而进行web服务推荐;
2. 系统通过web services search engines 获得一系列满足要求的web服务
3. 为每一个用户,服务通过历史信息,计算时间感知(time-aware)相似性——直接
4. 执行随机游走——间接
5. 发现相似用户,服务
6. 获得用户,服务的QoS预测
7. 合并6的用户,服务预测结果
8. 根据结果预测,然后返回给用户
4 time-aware similarity measurement
相似性测量对于基于邻居的协同过滤是很重要的,因为用户(服务)之间的相似性越高,就意味着更加准确的QoS预测。
本篇论文反复强调时间对于QoS预测准确性的影响,以下做出具体解释:
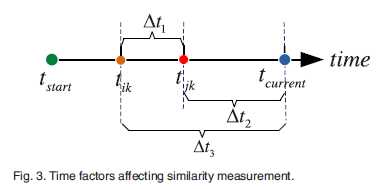
tstart表示web服务推荐的开始时间,tik,tjk分别表示用户i、j调用服务k的时间点,其他剩下的也就如字面表示的那样;
1. 两个用户调用同一个服务的时间点越接近,对用户相似性的测量越精准
如果△t1很长,即是用户i、j拥有相似的QoS经历,也不意味着他们之间的相似性高,因为这段时间足够用户i的QoS在服务k上发生巨大的变化;所以可以用如下衰减方程表示:
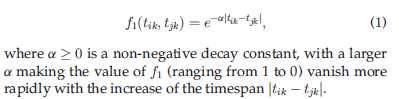
2. 越是接近当前时间的,两个用户调用同一个服务的QoS经历,对于QoS预测贡献更大
如果用户是在很早以前调用的web服务,这对于相似性测量用处不大,毕竟时间久了,中间的各种情况发生变化的可能性就更大;
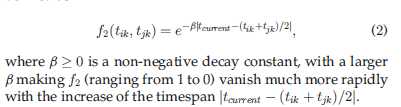
至此,时间对于相似性测量的影响,以及公式已经全部得出,现在需要做的是将两个结果统一起来,得出一个更加精确的结果:
现在以PCC(Pearson Correlation Coefficient (PCC) as their similarity models.)作为例子,构建一个相似性模型:
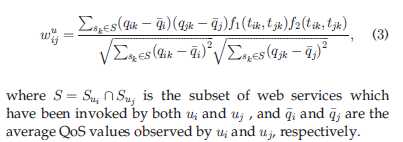
上述结果是在用户只调用一次服务的情况下,以下是多次的结果,推导过程本质上是一样的,只是多次匹配用户i、j调用服务k,最后求出平均值:

其实以上的结果还存在一个问题,比如说,两个用户之间调用的服务是比较少的,此时就可能出现一种情况:虽然两用户彼此不相似,但是QoS值是一样的——有点类似hash碰撞;
所以,可以更进一步的解决这个问题:主要思想在于,彼此重叠的集合越大,下边公式左边的值就会越大,否则越小,这就很好的解决了调用服务少却撞相似性的现象;

同样的,每个服务被不同用户调用至多只有一次的公式如下:
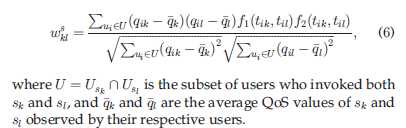
调用多次的情况也是类似的:
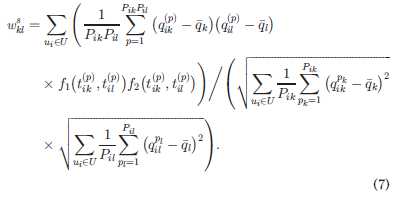
最后也是通过相似性权重去减少两个服务因为共同用户数目少导致的结果不准确:
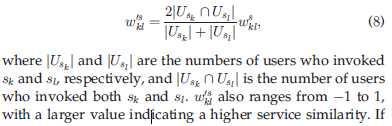
最后是总结上述过程的算法伪代码:

1~2:初始化
3~17:对用户i、j,迭代计算对于不同服务k,计算多次调用服务k的QoS总和以及相似用户的集合,并且最后进行平均值计算;
18~19:获取相似性系数
20:最终结果中的一部分
21~28:考虑时间因素,计算用户i、j的相似性准确性
29~30:计算结果并且返回
对于服务相似性的算法大致如上,此处不再赘述;
5 personalized reandom walk to handle data sparsity
5.1 similarity transition
通过上边的计算,已经可以为目标用户(服务)识别相似的邻居,但是user-service 矩阵通常是稀疏的,也即是数据稀疏问题,这也就导致了许多用户没有公共服务,许多服务没有公共用户,这也就导致了下边公式的值为0:
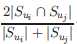
从而导致最后的相似性结果为0,最终导致最后的相似性计算结果为0,没办法获得足够多的历史数据去预测准确的QoS值。
因为上边的相似性用户是局限于直接邻居,所以当不存在直接邻居的时候,就会导致最后结果的不足;那么可以从另外一个角度出发,从间接相似的用户那里获得足够多的历史信息,从而进行有效准确的QoS预测;
以下是这个方法可行性的分析:
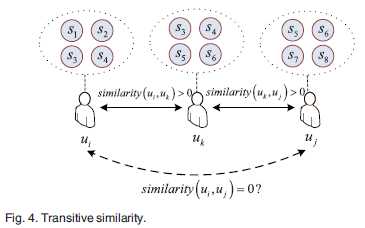
用户i调用了服务1、2、3、4;
用户k调用了服务3、4、5、6;
用户j调用了服务5、6、7、8;
如果仅仅只是按照上边所陈述的算法进行计算,显然用户i、j的相似性应该是0的,但是从另外一个角度看待这个问题:用户i、k共同调用了3、4服务,用户k、j共同调用了5、6服务,所以我们不能简单的判断用户i、j之间不存在相似性,因为相似性是一个可传递的关系——这也就是间接相似邻居(indirect similar neighbors)
5.2 indirect similarity inference
5.2.1 personalized random walk algorithm
大致思路就是构建用户图,服务图,然后在两幅图上边跑个性化的随机游走算法,而至于怎么跑?大致操作如下阐述:
此处使用用户图对间接相似邻居的识别进行详细阐述。
在个性化的随机游走算法中,如果一个用户获得的分数越高,就意味着他与目标用户的相似性越高。
为了执行个性化随机游走,首先需要对每一个用户选择top-k的直接相似用户,并以此为基础,构建一个用户邻接矩阵:

在一个用户的排序列向量r中,每一项rj表示访问用户j的可能性,r定义如下:

初始的r0定义如下:表示在初始阶段,每一个用户都具有相同的分数

关于矢量r,可以有如下化简:
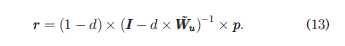
对于矢量r中的每一项rj,都是用户j的一个长期访问概率,因此,rj可以被当做是目标用户与uj之间相似性的近似测量值,越大表示相似性越接近;
5.2.2 similarity reconstruction
矢量r表示的是在目标用户与邻居之间的相对接近性而不是实际近似性(the stationary ranking vector r denotes the relative proximities rather than actual similarities between the target user and his neighbors),但是QoS预测是需要的实际相似性的(the actual similarities are necessary to QoS prediction.)
所以5.1.1中的结果需要进行重构获得我们所需要的直接相似性,具体操作如下:
同样的,对目标用户ui的top-k的直接邻居,表示如下:
在目标用户与他所有的直接,间接邻居的实际相似性构造如下:
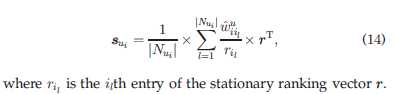
最后是时间感知相似性算法的伪代码总结:

1~2:初始化准备
3~8:矩阵标准化(具体意义见公式10)
9~11:计算排序向量r
12~18:公式14
19~20:得出结果并且返回
服务相似性类似于用户相似性的推导,此处不再赘述。
6 time-aware QoS prediction
在之前的步骤中,我们已经从直接的,间接的相似性用户(服务)中获得最够多的历史信息,此时,我们可以通过这些信息进行QoS预测。
条件阐述:
ui和sk分别是目标用户以及其中一个候补服务;
uj是ui的相似用户,sl是sk的相似服务;
其余参数之前都以介绍,此处不再赘述;
因此,基于用户,基于服务的时间感知QoS预测分别如下:
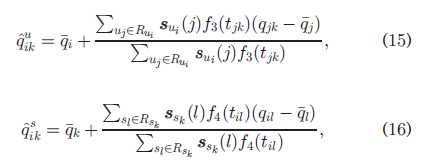
考虑复杂情况,也就是一个用户调用多次,一个服务被调用多次,其实也就是之前复杂化以后的公式往上套:
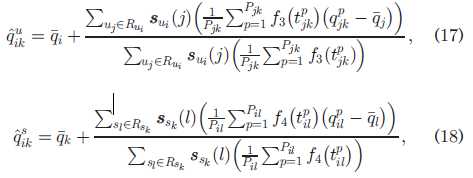
现在拿到了两个不同的qos值,分别代表基于用户,基于服务,那么有必要将其统一起来形成一个综合的结果,也是套用权重的方法,分别表示对user-based以及service-based的信任权重:
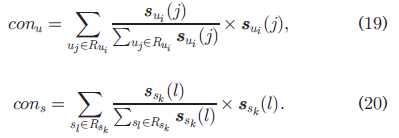
最后是使用权值参数将他们的结果统一起来:
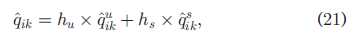
权值参数h的定义如下:表示最终结果多少是基于user-based,多少是基于service-based
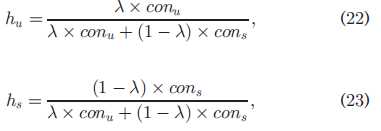
关于QoS预测,存在多种情况,分别是:
1. 有相似用户,没有相似服务;——>公式15或17
2. 没有相似用户,有相似服务;——>公式16或18
3. 有相似用户,有相似服务;——>公式21
4. 没有相似用户,没有相似服务;——>公式24
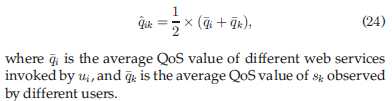
7 computational complexity analysis
略。
8 experiments
8.1 dataset
在64个时间间隔(15min)中,对于响应时间(response time)以及吞吐量(throughput)分别有64个矩阵(142行——用户,4532列——服务)表示;
8.2 data processing
以对响应时间数据的处理为例,以下是处理过程:
1. 随机选择140个用户以及140个服务,构造64个user-service response time矩阵(140*140),分别由每一个时间间隔提供;
2. 其中存在一些调用失败的web服务,此时需要替换掉;
3. 然后将第64个矩阵,也即是最新的那一个,随机分成两部分,一部分作为训练矩阵(60%),剩余的作为测试矩阵(40%);
4. 之后随即选择训练矩阵中90%的条目被之前63个观察的QoS值取代(具体作用:since it is difficult to discover enough similar users and services for QoS prediction based on sparse training data.这下子就有足够多的数据去做预测了,与test matrix中的剩余40%数据作对比)
8.3 evalutaion metric
我们用平均绝对误差(Mean Absolute Error,MAE)衡量我们方法的准确性。
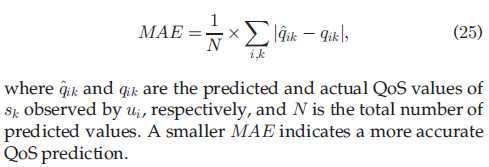
8.4 performance comparison
1. this indicates that the time information is valuable to QoS prediction.(Figs 5a-5h)
2. we can observe that under different training data densities (from 100 to 40 percent), the algorithms performing user or service personalized random walk outperform that without random walk.(Figs 6a-6h)
8.5 the impact of time decay constants
在8.4中,所有常量的值都是统一固定的,在这里讨论它们不同值对结果的影响。
9 conclusions
方法的创新性在于,在前人研究的基础上,通过时间信息提高预测的准确度,随机游走算法解决数据稀疏的问题;
其次,通过实验结果对比可以发现,这个方法性能还是很不错的;
但是,这个实验还是存在一些不足的地方,比如我们没有考虑时间戳的影响,这周一跟上周一的历史信息就真的不同吗?......时间需要从更加广阔的角度来看待,并与它所处的位置相关联才有意义(time needs to be regarded from a broader perspective and associated to its location to have meaning)
标签:网络连接 sea 解释 mil complex wal 基础上 可行性 必须
原文地址:https://www.cnblogs.com/xuxianyuan/p/10111001.html