标签:algorithm 分享图片 The ima 梯度下降 des 14. sub png
1.Mini-batch 梯度下降(Mini-batch gradient descent)
batch gradient descent :一次迭代同时处理整个train data
Mini-batch gradient descent: 一次迭代处理单一的mini-batch (X{t} ,Y{t})
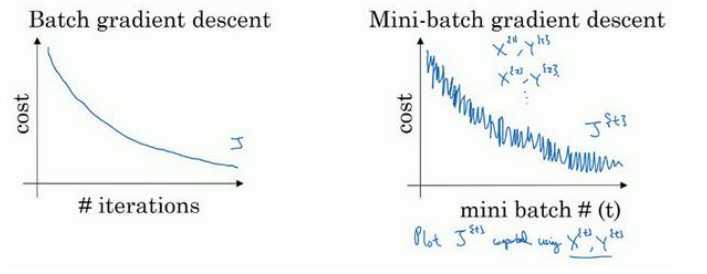
Choosing your mini-batch size : if train data m<2000 then batch ,else mini-batch=64~512 (2的n次方),需要多次尝试来确定mini-batch size
2.指数加权平均数(Exponentially weighted averages):
指数加权平均数的公式: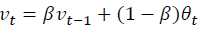 在计算时可视Vt 大概是1/(1-B)的每日温度,如果B是0.9,那么就是十天的平均值,当B较大时, 指数加权平均值适应更缓慢
在计算时可视Vt 大概是1/(1-B)的每日温度,如果B是0.9,那么就是十天的平均值,当B较大时, 指数加权平均值适应更缓慢
指数加权平均的偏差修正:

3.动量梯度下降法(Gradinent descent with Momentum)

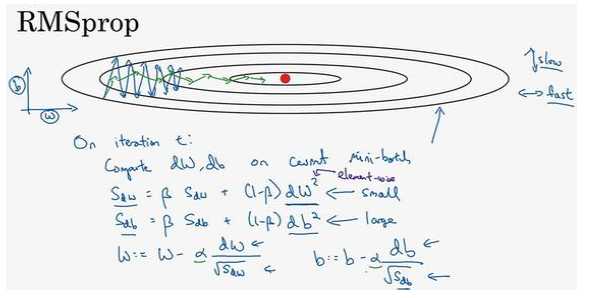
4.RMSprop算法(root mean square prop):
5.Adam 优化算法(Adam optimization algorithm):
Adam 优化算法基本上就是将Momentum 和RMSprop结合在一起



6.学习率衰减(Learning rate decay):
加快学习算法的一个办法就是随时间慢慢减少学习率,这样在学习初期,你能承受较大的步伐,当开始收敛的时候,小一些的学习率能让你步伐小一些。


标签:algorithm 分享图片 The ima 梯度下降 des 14. sub png
原文地址:https://www.cnblogs.com/easy-wang/p/10112014.html