标签:break 速度 ace pytho 直接 efi 梯度下降 end step
大致总结一下学到的各个优化算法。
一、梯度下降法
函数的梯度表示了函数值增长速度最快的方向,那么与其相反的方向,就可看作函数减少速度最快的方向。
在深度学习中,当目标设定为求解目标函数的最小值时,只要朝梯度下降的方向前进,就可以不断逼近最优值。
梯度下降主要组成部分:
1、待优化函数f(x)
2、待优化函数的导数g(x)
3、变量x,用于保存优化过程中的参数值
4、变量x点处的梯度值:grad
5、变量step,沿梯度下降方向前进的步长,即学习率
假设优化目标函数为:f(x) = (x-1)^2,那么导数为f‘(x) = g(x) = 2x - 2。我们可以直接看出最优值在x = 1处取得。
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return (x-1)**2
def g(x):
return 2 * x -2
def gd(x_start, step, g):
x_list = []
y_list = []
x = x_start
for i in range(20):
grad = g(x)
x = x - step*grad
x_list.append(x)
y_list.append(f(x))
print(‘x = {:}. grad = {:}, y = {:}‘.format(x, grad, f(x)))
if grad < 1e-6:
break;
return x_list,y_list
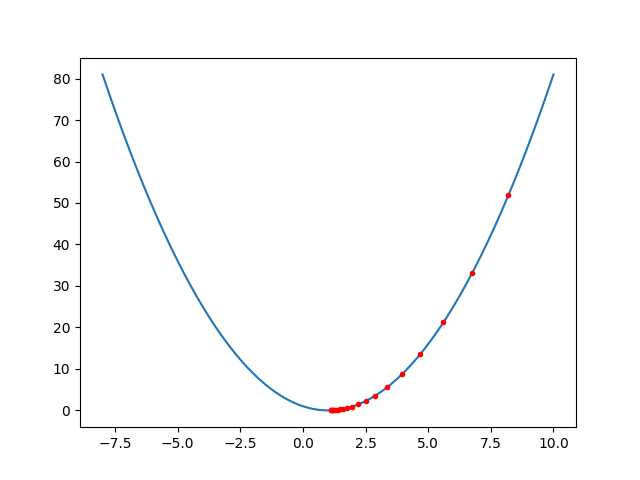
x = np.linspace(-8,10,200)
y = f(x)
//初始点为 x = 10, step = 0.1
x_gd, y_gd = gd(10, 0.1, g)
plt.plot(x, y)
plt.plot(x_gd, y_gd, ‘r.‘)
plt.savefig(‘gradient_descent.png‘)
plt.show()
输出结果:
x = 8.2. grad = 18, y = 51.83999999999999 x = 6.76. grad = 14.399999999999999, y = 33.1776 x = 5.608. grad = 11.52, y = 21.233663999999997 x = 4.6864. grad = 9.216, y = 13.58954496 x = 3.9491199999999997. grad = 7.3728, y = 8.697308774399998 x = 3.3592959999999996. grad = 5.8982399999999995, y = 5.5662776156159985 x = 2.8874367999999997. grad = 4.718591999999999, y = 3.562417673994239 x = 2.5099494399999998. grad = 3.7748735999999994, y = 2.2799473113563127 x = 2.2079595519999997. grad = 3.0198988799999995, y = 1.45916627926804 x = 1.9663676415999998. grad = 2.4159191039999994, y = 0.9338664187315456 x = 1.7730941132799998. grad = 1.9327352831999995, y = 0.5976745079881891 x = 1.6184752906239999. grad = 1.5461882265599995, y = 0.3825116851124411 x = 1.4947802324992. grad = 1.2369505812479997, y = 0.2448074784719623 x = 1.3958241859993599. grad = 0.9895604649983998, y = 0.15667678622205583 x = 1.316659348799488. grad = 0.7916483719987197, y = 0.10027314318211579 x = 1.2533274790395903. grad = 0.633318697598976, y = 0.06417481163655406 x = 1.2026619832316723. grad = 0.5066549580791806, y = 0.04107187944739462 x = 1.1621295865853378. grad = 0.40532396646334456, y = 0.026286002846332555 x = 1.1297036692682703. grad = 0.32425917317067565, y = 0.016823041821652836 x = 1.1037629354146161. grad = 0.2594073385365405, y = 0.010766746765857796
二、Momentum动量算法
标签:break 速度 ace pytho 直接 efi 梯度下降 end step
原文地址:https://www.cnblogs.com/lingjiajun/p/10118246.html