标签:src 博客 open www. python str return 分享图片 文章
实例需求:运用python语言爬取http://www.eastmountyxz.com/个人博客的基本信息,包括网页标题,网页所有图片的url,网页文章的url、标题以及摘要。
实例环境:python3.7
requests库(内置的python库,无需手动安装)
re库(内置的python库,无需手动安装)
实例网站:
第一步,点击网站地址http://www.eastmountyxz.com/,查看页面有哪些信息,网页标题、图片以及摘要等
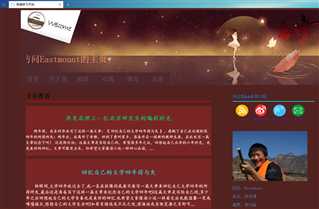
第二步,查看网页源代码,即可看到想要爬取的基本信息


实例代码:
1 #encoding:utf-8 2 import re 3 #import urllib.request 4 import requests 5 6 7 def getHtmlStr(url): 8 #content = urllib.request.urlopen(url).read().decode("utf-8") 9 res = requests.get(url) 10 res.encoding = res.apparent_encoding 11 return res.text 12 13 def parseHtml(content): 14 #爬取整个网页的标题 15 title = re.findall(r‘<title>(.*?)</title>‘, content) 16 print(title[0]) 17 #爬取图片地址 18 urls = re.findall(r‘<img .*src="\./(.*?)"‘, content) 19 baseUrl = ‘http://www.eastmountyxz.com/‘ 20 21 for i in range(len(urls)): 22 urls[i] = baseUrl + urls[i] 23 print(urls) 24 25 #爬取文章信息 26 p = r‘<div class="essay.*?">(.*?)</div>‘ 27 artcles = re.findall(p, content, re.S) 28 for a in artcles: 29 res = r‘<a .*href="(.*?)">‘ 30 t1 = re.findall(res, a, re.S) #超链接 31 print(t1[0]) 32 t2 = re.findall(r‘<a .*?>(.*?)</a>‘, a, re.S) #标题 33 print(t2[0]) 34 t3 = re.findall(‘<p style=.*?>(.*?)</p>‘, a, re.S) #摘要( 35 print(t3[0].replace(‘ ‘,‘‘)) 36 print(‘‘) 37 38 if __name__ == ‘__main__‘: 39 url = "http://www.eastmountyxz.com/" 40 htmlString = getHtmlStr(url) 41 parseHtml(htmlString)
实例结果:
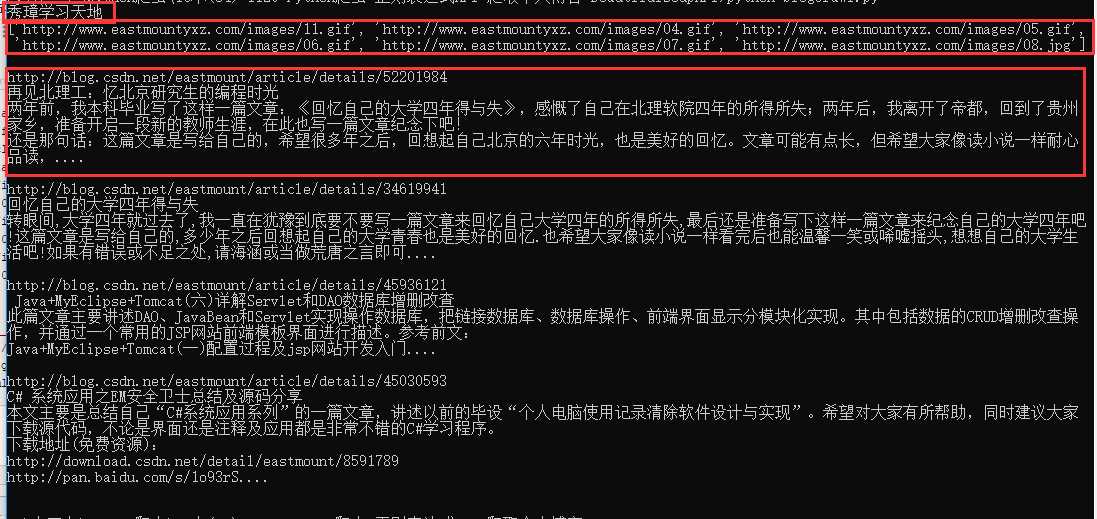
标签:src 博客 open www. python str return 分享图片 文章
原文地址:https://www.cnblogs.com/xiaoyh/p/10130447.html