标签:需要 highlight sele username b-tree from 提高 高效 pre
目前Mysql的MyISAM和InnoDB都支持B-Tree索引,InnoDB还支持B+Tree索引,Memory还支持Hash。现在互联网应用中对数据库的使用多数都是读较多,比例可以达到 10:1。并且数据库在做查询时 IO 消耗较大,所以如果能把一次查询的 IO 次数控制在常量级那对数据库的性能提升将是非常明显的,因此基于 B+ Tree 的索引结构出现了。
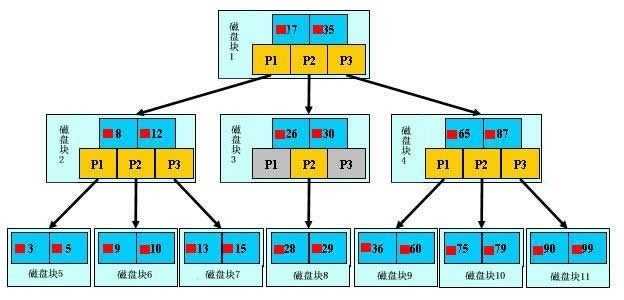
B+ Tree 的数据结构。是由一个一个的磁盘块组成的树形结构,每个磁盘块由数据项和指针组成。
所有的数据都是存放在叶子节点,非叶子节点不存放数据。
以磁盘块1为例,指针 P1 表示小于17的磁盘块,P2 表示在 17~35 之间的磁盘块,P3 则表示大于35的磁盘块。
比如要查找数据项99,首先将磁盘块1 load 到内存中,发生 1 次 IO。接着通过二分查找发现 99 大于 35,所以找到了 P3 指针。通过P3 指针发生第二次 IO 将磁盘块4加载到内存。再通过二分查找发现大于87,通过 P3 指针发生了第三次 IO 将磁盘块11 加载到内存。最后再通过一次二分查找找到了数据项99。
由此可见,如果一个几百万的数据查询只需要进行三次 IO 即可找到数据,那么整个效率将是非常高的。
观察树的结构,发现查询需要经历几次 IO 是由树的高度来决定的,而树的高度又由磁盘块,数据项的大小决定的。
磁盘块越大,数据项越小那么树的高度就越低。这也就是为什么索引字段要尽可能小的原因。
select name from user where id not in (1,3,4);
应该修改为:
select name from user where id in (2,5,6);
如:
select name from user where name like ‘%zhangsan‘
非前导则可以:
select name from user where name like ‘zhangsan%‘
建议可以考虑使用 Lucene 等全文索引工具来代替频繁的模糊查询。
如 user 表中的性别字段,可以明显区分的才建议创建索引,如身份证等字段。
这样会带来和预期不一致的查询结果。
select name from user where FROM_UNIXTIME(create_time) < CURDATE();
应该修改为:
select name from user where create_time < FROM_UNIXTIME(CURDATE());
如果给 user 表中的 username pwd 字段创建了复合索引那么使用以下SQL 都是可以命中索引:
select username from user where username=‘zhangsan‘ and pwd =‘axsedf1sd‘
select username from user where pwd =‘axsedf1sd‘ and username=‘zhangsan‘
select username from user where username=‘zhangsan‘
但是使用
select username from user where pwd =‘axsedf1sd‘
是不能命中索引的。
select name from user where username=‘zhangsan‘ limit 1
可以提高效率,可以让数据库停止游标移动。
select name from user where telno=18722222222
这样虽然可以查出数据,但是会导致全表扫描。
需要修改为
select name from user where telno=‘18722222222‘
不然也不会命中索引。
标签:需要 highlight sele username b-tree from 提高 高效 pre
原文地址:https://www.cnblogs.com/Chi-Sophia/p/10134792.html