标签:json upd 日志同步 自动发现 不一致 自己实现 有用 heartbeat normal

Etcd按照官方介绍:
Etcd is a distributed, consistent key-value store for shared configuration and service discovery
是一个分布式的,一致的键值对存储,主要用于共享配置和服务发现。
Etcd是CoreOS团队于2013年6月发起的开源项目,它的目标是构建一个高可用的分布式键值对(key-value)数据库,基于GO语言实现。
在分布式系统中,最基本最重要的问题就是各种信息的一致性,包括对服务的配置信息的管理、服务的发现、更新、同步等等。
而要解决这些问题,往往需要基于一套能保证一致性的分布式数据库系统,比如经典的Apache ZooKeeper项目,通过维护文件目录信息来实现数据的一致性。
Etcd就是专门为集群环境设计,可以很好的实现数据的一致性,提供集群节点管理和服务自动发现等。
受到Apache ZooKeeper项目和doozer项目的启发,Etcd在进行设计的时候重点考虑下面四个要素:
简单:支持REST风格的HTTP+JSON API;
安全:支持HTTPS方式的访问;
快速:支持并发每秒一千次的写操作;
可靠:支持分布式结构,基于Raft算法实现一致性。
通常情况下,使用Etcd可以在多个节点上启动多个实例,并将他们添加为一个集群。
同一个集群中的Etcd实例将会自动保持彼此信息的一致性,这意味着分布在各个节点上的应用也将获取到一致的信息。
Etcd基于Go语言实现,可以直接从项目主页:https://github.com/coreos/etcd下载源码自行编译,
也可以下载编译好的二进制文件,甚至直接使用制作好的Docker镜像文件来使用,下面使用二进制文件的方式进行安装。
下载和解压:
wget https://github.com/etcd-io/etcd/releases/download/v3.3.10/etcd-v3.3.10-linux-arm64.tar.gz
tar -vxf etcd-v3.3.10-linux-arm64.tar.gz
解压后,可以看到的文件包括:

其中etcd是服务主文件,etcdctl是提供给用户的的客户端命名,其它都是文档文件。
将etcd和etcdctl放到系统的可执行目录/usr/bin/或者/usr/local/bin/下面就可以使用了
cp etcd* /usr/local/bin/
直接执行Etcd命令,将启动一个实例监听本地的2379和4001端口。
此时客户端可以通过本地的2379和4001端口访问Etcd,其他Etcd本地实例可以通过2380和7001端口连接到新启动实例。
(1)启动
(2)查看版本
(3)查看集群健康状态
通过REST API直接查看集群健康状态:

通过ectdctl查看:

Etcd服务启动的时候支持一些参数,用户可以通过这些参数来调整服务和集群的行为。
参数可以通过环境变量形式传入,命名全部为大写,并且加ETCD_前缀,例如ETCD_NAME=‘etcd-cluster‘。
主要参数包括:通用参数、集群参数、安全相关参数、代理参数。
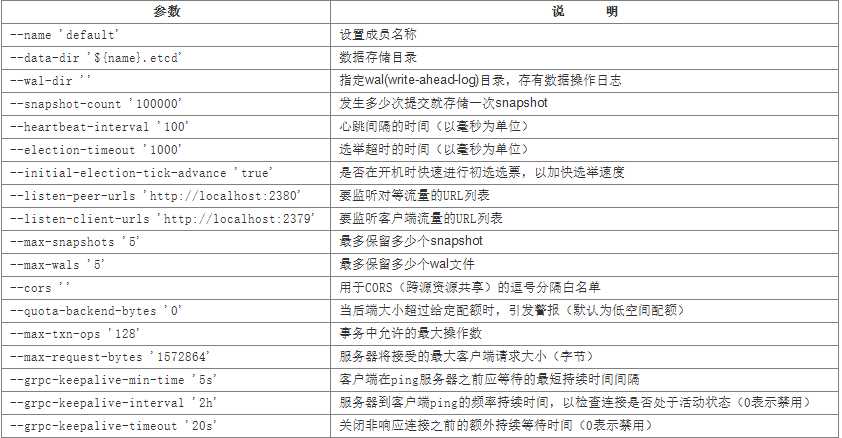
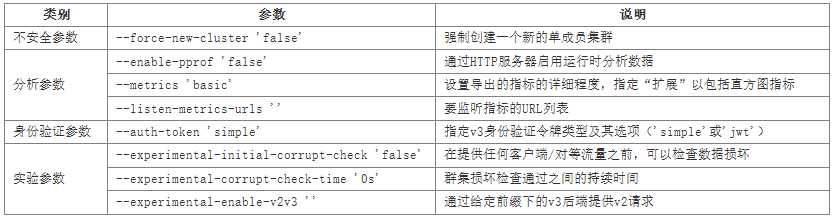
(1)通用参数
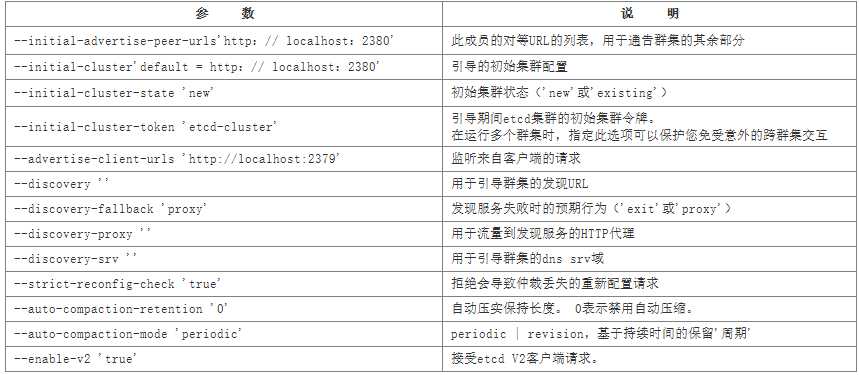
(2)集群参数
(3)安全相关参数
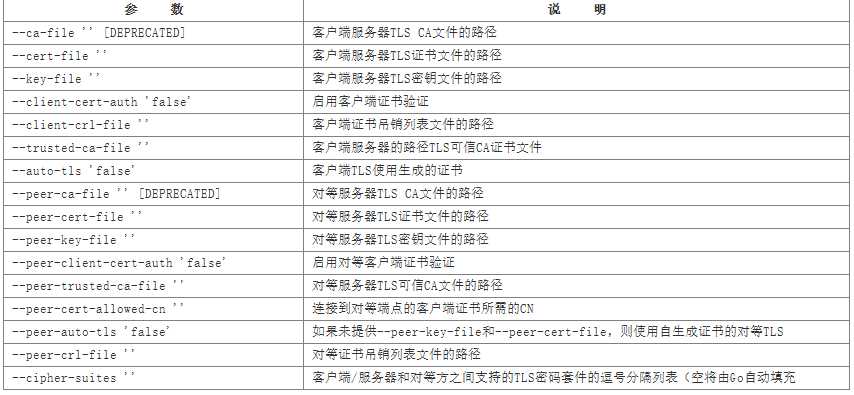
(4)代理参数
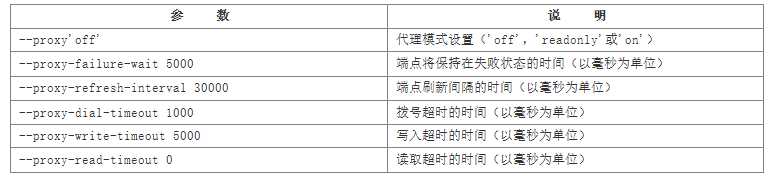
这些参数主要是当Etcd服务自身仅作为代理模式时候使用,即转发来自客户端的请求到指定的Etcd集群。
此时Etcd服务本省并不参与集群中去,不保存数据和参加选举。
(5)日志参数

(6)其它
etcdctl是Etcd官方提供的命令行客户端,它支持一些基于HTTP API封装好的命令,
供用户直接跟Etcd服务打交道,而无需基于HTTP API的方式。
当然这些命令跟HTTP API实际上是对应的,最终效果上并无不同之处。
Etcd项目二进制文件包中已经包含了etcdctl工具,也可以专门下载一个。
etcdctl的命令格式:
etcdctl [global options] command [command options] [arguments...]
etcdctl [全局选项] 命令 [命令选项] [命令参数]
etcdctl命令的全局选项参数:
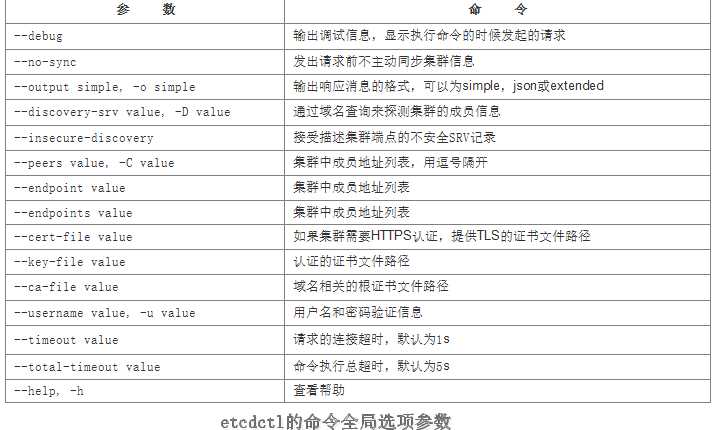
支持的命令大体上分为数据类操作和非数据类操作两类。
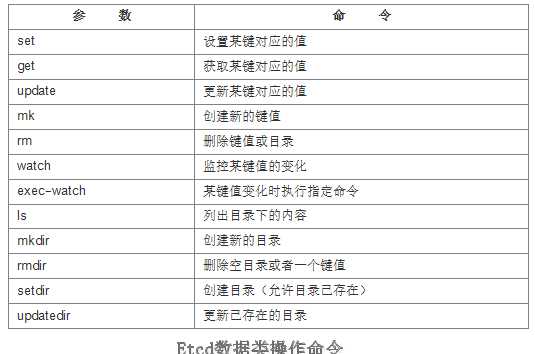
etcdctl数据类操作命令:
etcdctl非数据类操作命令:
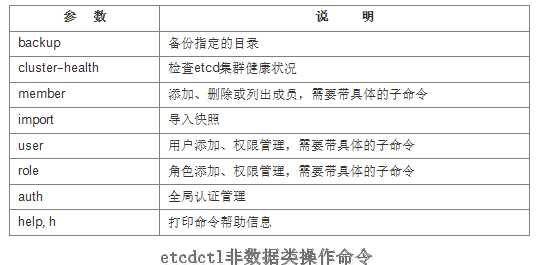
数据类操作围绕对键值和目录CRUD(符合REST风格的一套操作:Create)完整生命周期的管理。
CRUD即Create、Read、Update、Delete,是符合REST风格的一套API操作规范。
Etcd在键的组织上采用了层次化的空间结构(类似于文件系统中目录的概念),用户指定的键可以为单独的名字。
例如,testkey放在根目录/下面,也可以为指定目录结构,如clusterl/node2/testkey,则将创建相应的目录结构。
为某个键设置定值

参数说明:
--ttl value 键值的超时时间(单位为秒),默认为0则为永不超时。
--swap-with-value value 若该键现在的值是value,则进行设置操作
--swap-with-index value 若该键现在的索引值是指定索引,则进行设置操作。
获取指定键的值:

当键不存在时报错:

参数说明:
--sort 对返回结果进行排序
当键存在时,更新内容:

当不存在时,报错:

参数说明:
--ttl value 键值的超时时间(单位为秒),默认为0则为永不超时。
如果给定的键不存在,则创建一个新的键值:

如果键存在会直接报错:

参数说明:
--in-order 在目录<key>下创建按顺序键
--ttl value 键值的超时时间(单位为秒),默认为0则为永不超时。
删除某个键:
当键不存在的时候,报错:

参数说明:
--dir 如果键是个空目录或者是键值对则删除
--recursive, -r 删除目录和所有子键
--with-value value 检查现有的值是否匹配
--with-index value 检查现有的index是否匹配
监测一个键值的变化,一旦键值发生更新,就会输出最新的值并退出。

参数说明:
--forever, -f 一直监测,直到用户按“ctrl+c”退出;
--after-index value 在指定index之前一直监测;
--recursive, -r 返回所有的键值和子键值;
检测一个键值的变化,一旦键值发生更新,就执行给定命令。
很多时候用户实时根据键值更新本地服务的配置信息,并重新加载服务。
可以实现分布式应用配置的自动分发。
参数说明:
--after-index value 在指定index之前一直监测;
--recursive, -r 返回所有的键值和子键值;
列出目录(默认为根目录)下的键或者子目录,默认不显示子目录中的内容。
参数说明:
--sort 将输出结果排序
--recursive 如果目录下有子目录,则递归输出其中的内容
-p 如果输出为目录,在最后添加‘/’进行分区
如果给定的目录不存在,则创建一个新的键目录:
如果键目录存在,报错:

参数说明:
--ttl value 键值的超时时间(单位为秒),默认为0则为永不超时。
删除一个空目录或者键值对,如目录不为空则报错:


创建一个键目录,无论存在与否:

更新一个已经存在的目录属性。

备份Etcd的配置状态数据目录
选项:
--data-dir 要进行备份的Etcd的数据存放目录
--backup-dir 备份数据到指定路径

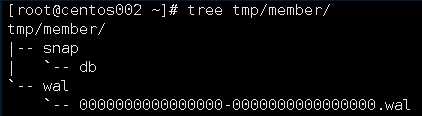
其中,snap为快照目录,保存节点状态文件,wal保存了数据库预写日志信息。
预写日志要求数据库在发生实际提交之前必须先将操作写入日志,可以保障系统在崩溃后更具日志回复状态。
查看Etcd集群的健康状态:

参数说明:
--forever, -f 每10秒检查一次,直到手动终止
通过list、add、remove等子命令列出、添加、删除Etcd实例到Etcd集群中。
etcdctl member command [command options] [arguments...]
例如本地启动一个Etcd服务实例后,可以用如下命令查看默认的成员实例:

导入旧版本的快照文件到系统
对用户进行管理,包括一系列子命令
add 添加一个用户
get 查询用户细节
list 列出所有用户
remove 删除用户
grant 添加用户到角色
revoke 删除用户角色
passwd 修改用户密码
默认情况下,需要先创建(启用)root用户作为etcd集群的最高权限管理员。

创建一个testuser用户:

分配某些已有角色给用户:

对用户角色进行管理
add 添加一个角色
get 查询角色信息
list 列出所有用户角色
remove 删除用户角色
grant 添加路径到角色控制
revoke 删除某路径的角色用户信息
默认带有root、guest两种角色,前者为全局最高权限。

是否启用访问验证,enable为启用,disable为禁用。
Etcd的集群也采用了典型的“主从”模型,通过Raft协议来保证在一段时间内有一个节点为主节点,其它节点为从节点。
一旦主节点发生故障,其它节点可以自动再重新选举出新的节点。
和其它分布式系统类似,急群众节点个数推荐为基数个,最少为3个,此时(quorum为2),
越多节点自然能提供更多的冗余性,但同时会带来写数据能力的下降。
构建集群无非是让节点知道自己加入哪个集群,其它对等节点的访问信息是什么。
Etcd支持两种模式来构建集群:静态配置和动态探测。
静态配置就是提取写好集群中的有关信息。
三个节点的ip信息分别为:
172.16.16.15 172.16.0.4 172.16.0.15
通过如下命令来分别启动各个节点上的etcd服务。
节点1: etcd --name infra0 --initial-advertise-peer-urls http://172.16.16.15:2380 --listen-peer-urls http://172.16.16.15:2380 --listen-client-urls http://172.16.16.15:2379,http://127.0.0.1:2379 --advertise-client-urls http://172.16.16.15:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster infra0=http://172.16.16.15:2380,infra1=http://172.16.0.4:2380,infra2=http://172.16.0.15:2380 --initial-cluster-state new 节点2: etcd --name infra1 --initial-advertise-peer-urls http://172.16.0.4:2380 --listen-peer-urls http://172.16.0.4:2380 --listen-client-urls http://172.16.0.4:2379,http://127.0.0.1:2379 --advertise-client-urls http://172.16.0.4:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster infra0=http://172.16.16.15:2380,infra1=http://172.16.0.4:2380,infra2=http://172.16.0.15:2380 --initial-cluster-state new 节点3: etcd --name infra2 --initial-advertise-peer-urls http://172.16.0.15:2380 --listen-peer-urls http://172.16.0.15:2380 --listen-client-urls http://172.16.0.15:2379,http://127.0.0.1:2379 --advertise-client-urls http://172.16.0.15:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster infra0=http://172.16.16.15:2380,infra1=http://172.16.0.4:2380,infra2=http://172.16.0.15:2380 --initial-cluster-state new
启动成功之后,可以在任意一个节点查看当前集群中的成员信息:
[root@centos002 ~]# etcdctl member list 1f146a283033baa3: name=infra2 peerURLs=http://172.16.0.15:2380 clientURLs=http://172.16.0.15:2379 isLeader=false 6de1f3013b32aaf9: name=infra1 peerURLs=http://172.16.0.4:2380 clientURLs=http://172.16.0.4:2379 isLeader=false d89aedc239d376e5: name=infra0 peerURLs=http://172.16.16.15:2380 clientURLs=http://172.16.16.15:2379 isLeader=true
还可以查看各个节点的健康状态:
[root@centos002 ~]# etcdctl cluster-health member 1f146a283033baa3 is healthy: got healthy result from http://172.16.0.15:2379 member 6de1f3013b32aaf9 is healthy: got healthy result from http://172.16.0.4:2379 member d89aedc239d376e5 is healthy: got healthy result from http://172.16.16.15:2379 cluster is healthy
静态配置的方法虽然简单,但是如果节点的信息需要变动的时候,就需要手动修改。
可以通过动态发现的方法,让集群自动更新节点信息。
要实现动态发现,首先需要一套支持动态发现的服务。
CoreOS提供了一个公开的Etcd发现服务,地址是:https://discovery.etcd.io。
这个网址会为创建的集群提供一个独一无二的uuid,需要提供的唯一参数是节点的个数
[root@centos001 ~]# curl https://discovery.etcd.io/new?size=3 https://discovery.etcd.io/37435a480ba59aa81a682fee7f415856
分别在各个节点上指定服务发现地址信息,替换掉原先动态指定的节点列表。
节点1: etcd --name infra0 --initial-advertise-peer-urls http://172.16.16.15:2380 --listen-peer-urls http://172.16.16.15:2380 --listen-client-urls http://172.16.16.15:2379,http://127.0.0.1:2379 --advertise-client-urls http://172.16.16.15:2379 --initial-cluster-token etcd-cluster-1 --discovery https://discovery.etcd.io/37435a480ba59aa81a682fee7f415856 --initial-cluster-state new 节点2: etcd --name infra1 --initial-advertise-peer-urls http://172.16.0.4:2380 --listen-peer-urls http://172.16.0.4:2380 --listen-client-urls http://172.16.0.4:2379,http://127.0.0.1:2379 --advertise-client-urls http://172.16.0.4:2379 --initial-cluster-token etcd-cluster-1 --discovery https://discovery.etcd.io/37435a480ba59aa81a682fee7f4158560 --initial-cluster-state new 节点3: etcd --name infra2 --initial-advertise-peer-urls http://172.16.0.15:2380 --listen-peer-urls http://172.16.0.15:2380 --listen-client-urls http://172.16.0.15:2379,http://127.0.0.1:2379 --advertise-client-urls http://172.16.0.15:2379 --initial-cluster-token etcd-cluster-1 --discovery https://discovery.etcd.io/37435a480ba59aa81a682fee7f415856 --initial-cluster-state new
dns发现主要通过dns服务来记录集群中各节点的域名信息,各节点到dns服务中获取相互的地址信息,从而建立集群。
即为每个节点指定同一个子域的域名,然后通过域名发现来自动注册。例如:
infra0.example.com infra1.example.com infra2.example.com
则启动参数中的集群节点列表信息可以替换为--discovery-srv example.com
影响集群性能的因素可能有很多,包括时间同步、网络抖动、存储压力、读写压力等。
需要通过优化配置尽量减少这些因素的影响。
对于分布式集群来说,各个节点上的同步时钟十分重要,
Etcd集群需要各个节点时钟差异不超过1s。否则可能会导致Raft协议的异常。
可以修改/etc/ntp.conf这个配置文件,来指定ntp服务器的地址。
对于Etcd集群来说,有两个因素十分重要:心跳消息时间间隔和选举时间间隔。
前者意味着主节点每隔多久来通过心跳消息通知从节点自身的存活状态;
后者意味着从节点多久没收到心跳通知后可以尝试发起选举自身为主节点。
显然后者要比前者大,一般建议设为前者的5倍以上。
时间越短,发生故障后回复的越快,但心跳信息占用的计算和网络资源也就越多。
默认情况下,心跳消息间隔为100ms。选举时间间隔为1s。
可以在启动服务的时候通过--heartbeat-interval和--election-timeout来指定。
当然也可以通过环境变量来指定。ETCD_HEARTBEAT_INTERVAL=100 ETCD_ELECTION_TIMEOUT=1000。
Etcd会定期将数据的修改存储为snapshop,默认情况下每10000次修改才会存一个snapshot。
在存储的时候会有大量数据进行写入,影响Etcd的性能。
启动时通过--snapshot-count ‘100000‘指定,也可以使用环境变量ETCD_SNAPSHOP_COUNT=2000 etcd来指定。
无论是添加、删除还是迁移节点,都要一个一个的进行,并且确保先修改配置信息
(包括节点广播的监听地址、集群中节点列表),然后再进行操作。
例如要删多个节点,当有主节点被删除时,需要先删掉一个,等集群中状态稳定后(新的节点重新生成),再删除另外节点。
要迁移或者替换节点的时候,先将节点从集群中删除掉,等集群状态重新稳定后,再添加上新的节点。
当然,使用旧节点的数据目录会加快新节点的同步过程,但要保证这些数据是完整的,且是比较新的。
Etcd集群中的节点会通过数据目录来存放修改信息和集群配置。
一般来说,当某个节点出现故障的时候,本地数据已经过期甚至格式破坏。
如果只是简单的重启进程,容易造成数据的不一致。
这个时候保险的做法是先通过命令来删除该节点,然后清空数据目录,再重新作为空节点加入。
Etcd提供了-strict-reconfig-check选项,确保当集群状态不稳定的时候拒绝对配置状态的修改。
极端情况下,集群中大部分节点都出现问题,需要重启整个集群。
这个时候,最保险的做法就是找到一个数据记录完整且比较新的节点,
先以它为唯一节点创建新的集群,然后将其他节点一个一个的添加进来。
所有的分布式系统,都面临的一个问题是多个节点之间的数据共享,这和团队协作的道理是一样的,成员可以分头干活,
但总是需要共享一些必要的信息,比如谁是leader,都有那些成员,依赖任务之间的顺序协调等。
所以分布式系统要么自己实现一个可靠的共享存储来同步信息(比如Elasticsearch),要么依赖一个可靠的共享存储,而Etcd就是这样一个服务。
(1)提供存储以及获取数据的接口,它通过协议保证Etcd集群中的多个节点数据的强一致性,用于存储元信息和共享配置。
(2)提供监听机制,客户端可以监听某个key或者某些key的变更(v2和v3的机制不同),用于监听和推送变更。
(3)提供key的过期以及续约机制,客户端通过定时刷新来实现续约(v2和v3实现的机制也不一样),用于集群监控以及服务注册发现。
(4)提供原子的CAS(Compare-and-swap)和CAD(Compare-and-Delete)支持(v2通过接口参数实现,v3通过批量事物实现),用于分布式锁以及leader选举。
(1)raft算法通过对不同的场景(选主,日志复制)设计不同的机制,虽然降低 了通用性(相对paxos),但同时也降低了复杂度,便于理解和实现。
(2)raft内置的选主协议是给自己用的,用于选出主节点,理解raft的选主机制的关键在于理解raft的时钟周期以及超时机制。
(3)理解Etcd的数据同步的关键在于理解raft的日志同步机制。
Etcd实现raft的时候,充分利用go语言CSP并发模型和chan的魔法,想更进一步了解的话可以去阅读源码,下面简单分析一下它的wal日志。
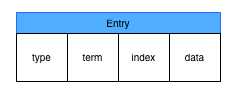
wal日志是二进制的,解析出来后是以上数据结构LogEntry。
其中第一个字段type,只有两种,一种是0表示Normal,1表示ConfChange(ConfChange表示Etcd本身的配置变更同步,比如有新的节点加入等)。
第二个字段是term,每个term代表一个主节点的任期,每次主节点变更term就会变化。
第三个字段是index,这个序号是严格有序递增的,代表变更序号。
第四个字段是二进制的data,将raft request对象的pb结构整个保存下。
Etcd源码下有个tools/etcd-dump-logs,可以将wal日志dump成文本查看,可以协助分析raft协议。
raft协议本身不关心应用数据,也就是data中的部分,一致性都通过同步wal日志来实现,
每个节点将从主节点收到的data apply到本地的存储,raft只关心日志的同步状态,
如果本地存储实现的有bug,比如没有正确的将data apply到本地,可能会导致数据不一致。
Etcd v2与v3本质上是共享同一套raft协议代码的两个独立应用,接口不一样,存储不一样,数据相互隔离。
也就是说如果从Etcd v2升级到Etcd v3,原来v2的数据还是只能用v3的接口访问,v3的接口创建的数据只能访问通过v3的接口访问。
Etcd v2存储,Watch以及过期机制
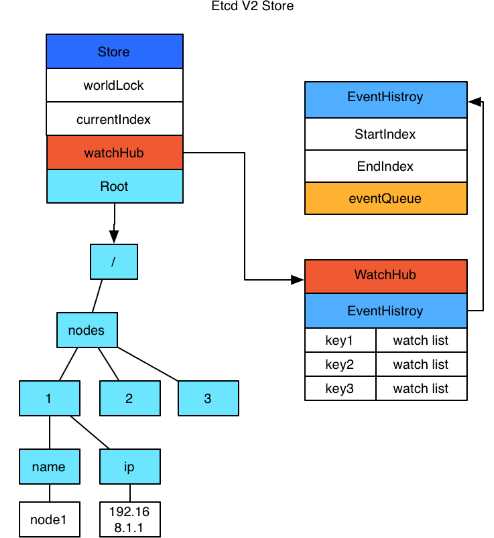
Etcd v2是个纯内存的实现,并未实时将数据写入到磁盘,持久化机制很简单,就是将store整合序列成json写入文件。
数据在内存中是一个简单的树结构,比如以下结构数据存储到Etcd中的结构如图所示:
store中有一个全局currentindex,每次变更,index会加1,然后每个event都会关联到currentindex。
当客户端调用watch接口(参数中怎加wait参数)时,如果请求参数中有waitindex,
并且waitindex小于currentindex,则从EventHistory表中查询index小于等于waitindex,并且和watch key匹配的event。
如果有数据,则直接返回。如果历史表中没有或者请求没有带waitindex,则放入WatchHub中,每个key会关联以和watcher列表。
当有变更操作时,变更生成的event会放入EventHistory表中,同时通知和该key相关的watcher。
这里面有几个影响使用的细节问题:
(1)EventHistory是有长度限制的,最长1000,也就是说,如果你的客户端停了许久,
然后重新watch的时候,可能和该waitindex相关的event已经被淘汰了,这种情况下会丢失变更。
(2)如果通知watch的时候,出现了阻塞(每个watch的channel有100个缓冲空间),
Etcd会直接把watch删除,也就是会导致wait请求的连接中断,客户端需要重新连接。
(3)Etcd store的每个node中保存了过期时间,通过定时机制进行清理。
Etcd v2的一些限制:
(1)过期时间只能设置到每个key上,如果多个key要保证生命周期一致则比较困难。
(2)watch只能watch某一个key以及其子节点(通过参数 recursive),不能进行多个watch。
(3)很难通过watch机制来实现完整的数据同步(有丢失变更的风险),所以当前的大多数使用方式是通过watch得知变更,
然后通过get重新获取数据,并不完全依赖于watch的变更event。
标签:json upd 日志同步 自动发现 不一致 自己实现 有用 heartbeat normal
原文地址:https://www.cnblogs.com/yangmingxianshen/p/10153573.html