1.1模块
什么是模块:
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。
为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,在python中。一个.py文件就称为一个模块(Module)
使用模块的好处:
提高了代码的可维护性。
其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们编写程序的时候也经常引用其他模块,包括python的内置的模块和第三方模块。
包(package)的概念:
如果不同的人编写的模块名相同怎么办?
为了避免模块名冲突,python有引入了按目录组织模块的方法,称为包(Package)

一个abc.py的文件就是一个名字叫abc的模块。
假设,我们的abc和qaz这两个模块名字与其他模块冲突了,于是我们可以通过包来组织模块,避免冲突,方法是选择一个顶层的包名比如MyUser。
引入包以后,只要顶层的包名不与别人 冲突,那所有的模块都不会与别人冲突。现在abc.py模块的名字就变成了MyUser.abc,qaz模块名字就变成了MyUser.qaz.
多级包结构:包.包.模块
注:每个包目录下面都会有一个——init——.py文件,这个文件是必须存在的,否则,python就把这个目录当成普通目录,而不是一个包。——init——.py可以是空文件,里面可以有程序代码,因为——init——.py就是一个模块,模块名就是MyUser
注:我们自已编写模块名时,尽量不要与内置函数或则模块名字冲突。如同与系统的模块同名,否则无法导入系统自带的模块
模块分为3种:
1.自定义模块
2.内置标准模块(又称标准库)
3.第三方模块(开源模块)
1.1.1导入模块

1 #1语法import 2 import module1,module2,module3,module4 3 4 #2from xx import xx 语句 5 from module import name1,name2 6 7 #这个声明不会把module模块导入到当前的命名空间,只会把name1,name2单个引入到执行的程序 8 9 from module.xx import name as rename 10 #把来自于modname.xx的name的重新改了一个名字,去掉用这个模块的方法 11 12 13 from module import * 14 #这提供了一个简单的方法来导入一个模块中的所有项目。这个导入的模块的方法一般不推荐使用,如果引入的其它来源的命名,很有可能覆盖已有的定义。
模块的运行本质
#1 import test #2 from modname from test
无论是1,还是2,首先通过sys.pyth找到test.py,然后执行test代码(全部执行)
区别是1会将test这个模块名加载到名字空间,而2只会将test这个变量名加载进来。
为模块添加路径
#模块运行时通过sys.path的路径一步一步查找模块的 #导入模块时是根据那个路径作为基准来进行的呢?即:sys.path #如果sys.path路劲列表中没有你想要的路径,可以通过sys.path.append("路径")来添加 #当前这是临时添加,如需永久添加则需修改系统的环境变量 import os,sys BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR)
开源模块安装的常用方法
1 1.yum 2 2.pip 3 3.apt-get
1.1.2__name__
python解释器把一个特殊变量__name__的值为__main__
#很多模块文件内容里面都有 if __name__==‘__main__‘: 运行测试代码程序的逻辑 如果我们写的模块文件,需要被别人调用则不会运行下面的程序的逻辑 我们自已使用用,可以些运行整体程序代码的逻辑 自已用的时候 __name__==‘__main__‘ , __name__的变量就等于‘__main__‘,被当作模块导入到其他的文件里时, __name__的变量不等于‘__main__‘
1.2sys模块

1 sys.argv #在命令行参数是一个空列表,在其他中第一个列表元素中程序本身的路径 2 sys.exit(n) #退出程序,正常退出时exit(0) 3 sys.version #获取python解释程序的版本信息 4 sys.path #返回模块的搜索路径,初始化时使用python PATH环境变量的值 5 sys.platform #返回操作系统平台的名称 6 sys.stdin #输入相关 7 sys.stdout #输出相关 8 sys.stderror #错误相关
1 import sys,time 2 for i in range(1,20): 3 sys.stdout.write("#") #显示写入 4 time.sleep(0.2) 5 sys.stdout.flush() # 把每次写入的东西都给刷新到屏幕
1 import sys,time 2 3 def view_bar(num, total): 4 rate = float(num) / float(total) 5 rate_num = int(rate * 100) 6 r = ‘\r%d%%‘ % (rate_num, ) #%% 表示一个% 7 sys.stdout.write(r) 8 sys.stdout.flush() 9 if __name__ == ‘__main__‘: 10 for i in range(0, 101): 11 time.sleep(0.1) 12 view_bar(i, 100)
1.3time模块
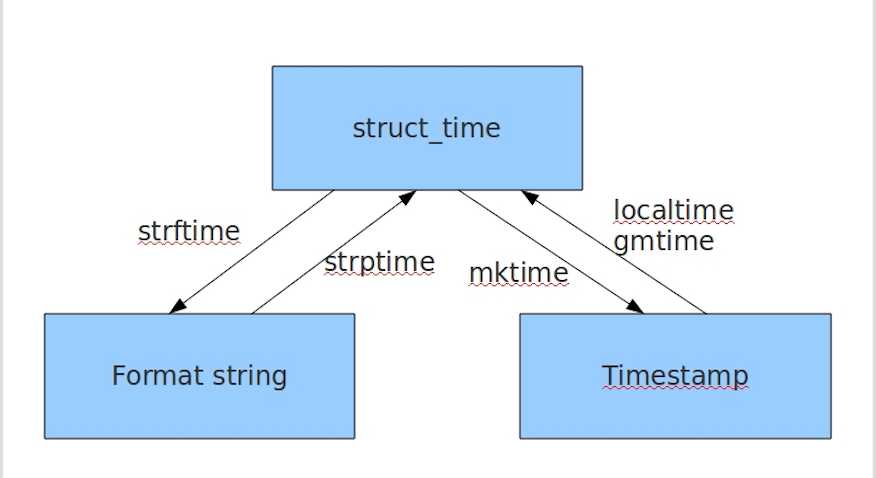
在python中,通常3种时间的表示
1.时间戳(timestamp):时间戳表示的是从从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。
2.格式化的时间字符串 (年-月-日 时:分:秒)
3.元组(struct_time)结构化时间:struct_time元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
常用time模块方法
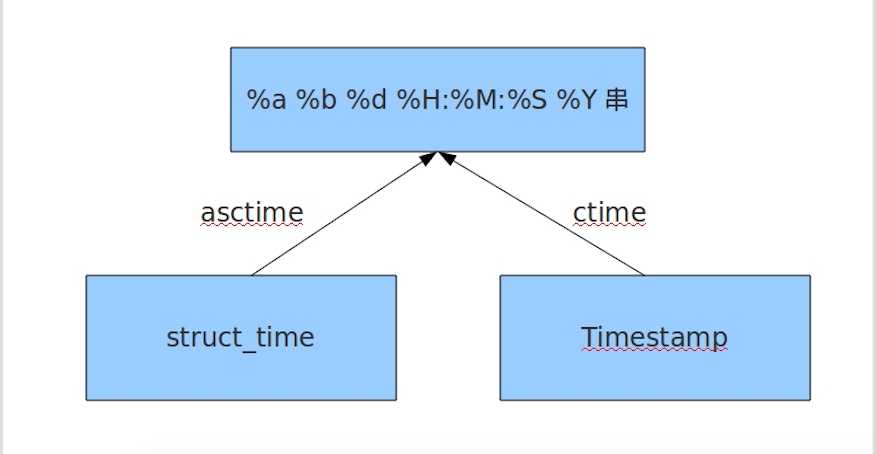
1 #注:小白多用print(),查看 2 3 1#time.time() 时间戳 4 print(time.time()) 5 6 2#time.localtime(second) 加上second(时间戳)转换结构化时间,不加则显示当前的结构化时间 7 print(time.localtime()) 8 print(time.localtime(1371643198)) 9 10 3#time.gmtime(second) #utc时区加上second(时间戳)转换结构化时间,不加则显示当前的结构化时间 11 print(time.gmtime()) 12 print(time.gmtime(1391614837)) 13 14 4#mktime ()结构化时间转换为时间戳 15 print(time.mktime(time.localtime())) 16 17 5#time.ctime(seconds)#将加上时间戳转换为时间戳的格式化时间,不加则返回当前的的格式化时间 18 print(time.time()) 19 print(time.ctime(1331644244)) 20 21 6#time.asctime(p_tuple)#加参数是加一个结构化时间,把加的结构化时间转换为格式化时间,不加则返回当前的格式化时间 22 print(time.asctime()) 23 print(time.asctime(time.gmtime())) 24 25 7#time.strftime(format,p_tuple) #把一个结构化时间转化相应的格式时间 26 print(time.strftime("%Y-%m-%d %X",time.localtime())) 27 28 8#time.strptime(string,format) #把相应的格式时间,转换为结构化时间 29 print(time.strptime("2015-5-20 20:22:36","%Y-%m-%d %X")) 30 #time.struct_time(tm_year=2015, tm_mon=5, tm_mday=20, tm_hour=20, tm_min=22, tm_sec=36, tm_wday=2, tm_yday=140, tm_isdst=-1) 31 32 9#time.sleep(second)#将程序延迟指定的秒数运行 33 print(time.sleep(5)) 34 35 # 10 time.clock() 36 # 这个需要注意,在不同的系统上含义不同。在UNIX系统上,它返回的是“进程时间”,它是用秒表示的浮点数(时间戳)。 37 # 而在WINDOWS中,第一次调用,返回的是进程运行的实际时间。而第二次之后的调用是自第一次调用以后到现在的运行 38 # 时间,即两次时间差。
1.4random模块
1 import random 2 3 print(random.random())#随机生成一个小于1的浮点数 4 5 print(random.randint(1,3)) #[1-3]随机生成1到3的数 6 7 print(random.randrange(1,3)) #[1-3)随机生成1到2的数 8 9 print(random.choice([1,‘23‘,[4,5]]))#随机在列表中选取一个元素 10 11 print(random.sample([1,‘23‘,[4,5]],2))#随机在列表中选取2个元素 12 13 print(random.uniform(1,3))#随机生成1-3的之间的浮点数 14 15 print(random.shuffle([1,3,5,7,9]))#打乱列表中元素的顺序
1 import random 2 3 def v_code(): 4 #随机生成5位数的验证码 5 code = ‘‘ 6 for i in range(5): 7 num=random.randint(0,9) 8 alf=chr(random.randint(65,90)) 9 add=random.choice([num,alf]) 10 code += str(add) 11 return code 12 print(v_code())
1.5os模块
1 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 2 os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd 3 os.curdir 返回当前目录: (‘.‘) 4 os.pardir 获取当前目录的父目录字符串名:(‘..‘) 5 os.makedirs(‘dirname1/dirname2‘) 可生成多层递归目录 6 os.removedirs(‘dirname1‘) 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 7 os.mkdir(‘dirname‘) 生成单级目录;相当于shell中mkdir dirname 8 os.rmdir(‘dirname‘) 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname 9 os.listdir(‘dirname‘) 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 10 os.remove() 删除一个文件 11 os.rename("oldname","newname") 重命名文件/目录 12 os.stat(‘path/filename‘) 获取文件/目录信息 13 os.sep 输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" 14 os.linesep 输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" 15 os.pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为: 16 os.name 输出字符串指示当前使用平台。win->‘nt‘; Linux->‘posix‘ 17 os.system("bash command") 运行shell命令,直接显示 18 os.environ 获取系统环境变量 19 os.path.abspath(path) 返回path规范化的绝对路径 20 os.path.split(path) 将path分割成目录和文件名二元组返回 21 os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素 22 os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 23 os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False 24 os.path.isabs(path) 如果path是绝对路径,返回True 25 os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False 26 os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False 27 os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 28 print(os.path.join("D:\\python\\wwww","xixi")) #做路径拼接用的 29 #D:\python\wwww\xixi 30 31 os.path.getatime(path) 返回path所指向的文件或者目录的最后存取时间 32 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
1.6json & pickle序列化模块
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
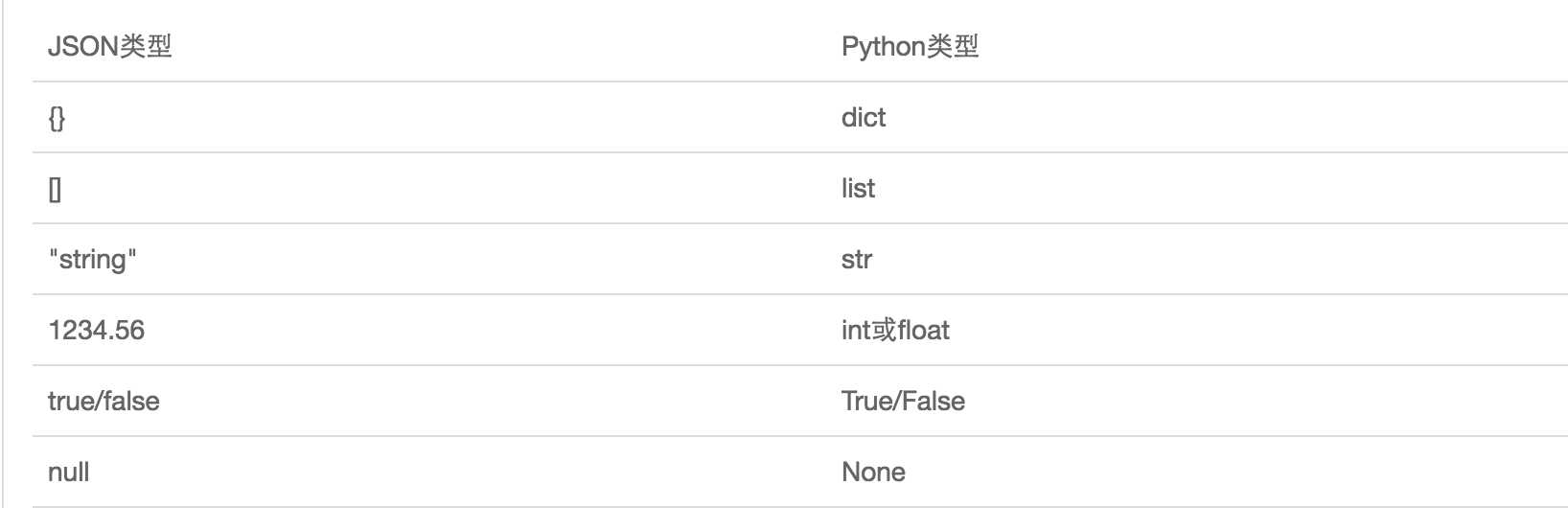
json和内置函数的eval()方法,eval将一个字符串转成python对象,不过,eval 方法有局限性,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
1 import json 2 aa = ‘{"name":"qa","age":11}‘ 3 xixi="[1,2,3,4,5,6]" 4 bb = "(‘1‘,‘2‘)" 5 print(eval(aa)) 6 print(json.loads(aa)) 7 print(type(json.loads(xixi))) 8 print(type(json.loads(aa))) 9 # print(type(json.loads(bb))) #报错[](){}里面所有的元素的单引号必须改为双引号,json不认单引号 10 11 xx = "[xixi,haha]" 12 # print(eval(xx)) #报错 13 print(json.dumps(xx)) #"[xixi,haha]"
什么是序列化:
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化。
json:用于字符串和python数据类型间进行转换。
pickle:用于python特有的类型和python的数据类型间进行转换。
json的dumps,loads的功能:

1 import json 2 data = {‘k1‘:123,‘k2‘:456} 3 s_str=json.dumps(data) #把data对象序列化成字符串 >>>>>#序列化的过程 4 # print(s_str) #{"k2": 456, "k1": 123} 5 # print(type(s_str)) str 6 with open("js_new","w") as f: 7 f.write(s_str) #把json的字符串写入到文件js_new 8 9 #注:用之前先把上面的写文件的方式给注释掉 10 with open("js_new","r") as f: 11 aa = json.loads(f.read()) #把字符串重新读到python原来数据对象 >>>>#反序列化过程 12 print(aa) 13 # print(type(aa)) #<class ‘dict‘>
json的dump,load的功能
1 import json 2 data = {‘k1‘:123,‘k2‘:456} 3 with open("json_dump","w") as f: 4 json.dump(data,f) 5 #json.dump(x,f) x是python原来数据的对象,f是文件对象 主要是用来写python对象到文件里面 6 7 with open("json_dump","r") as f: 8 bb = json.load(f) 9 print(bb) 10 print(type(bb)) #<class ‘dict‘> 11 #json.read(f) #f是文件对象,把文件对象的数据读取成原来python对象的类型
json的dumps,loads,dump,load功能总结
json.dumps(x) 把python的(x)原对象转换成json字符串的对象,主要用来写入文件。
json.loads(f) 把json字符串(f)对象转换成python原对象,主要用来读取文件和json字符串
json.dump(x,f) 把python的(x)原对象,f是文件对象,写入到f文件里面,主要用来写入文件的
json.load(file) 把json字符串的文件对象,转换成python的原对象,只是读文件
pickle的功能
pickle和json的用法类似。
这里我就不一一举列了
1 li = "[1,2,3,4,5,6,‘aa‘]" 2 aa = pickle.dumps(li) 3 print(type(aa)) #<class ‘bytes‘> 4 # print(pickle.dumps(li)) #bytes对象 5 6 with open("pickle_new","wb") as p: #注意w是写入str,wb时写入字节 ,wb写入文件是二进制, 7 # 我们看不到里面的里面写入的文件内容pickle_new 8 pickle.dump(li,p) 9 with open("pickle_new","rb") as p_b: #以二进制方式读取 10 # print(pickle.load(p_b)) #[1,2,3,4,5,6,‘aa‘] 11 print(pickle.loads(p_b.read())) #[1,2,3,4,5,6,‘aa‘]
注:pickle的问题和所有其他编程语言特有的序列化的问题一样,就是pickle它只能用于python,并且可能不同版本的python彼此都不兼容,因此,只能用pickle保存那些不重要的数据,不能成功的反序列化也没关系。