标签:输出 迭代 技术分享 线性变换 sig 初始化 log 计算 ext
本文摘自:
https://www.cnblogs.com/pinard/p/6422831.html
http://www.cnblogs.com/charlotte77/p/5629865.html
在监督学习中,优化参数的方法
在DNN神经网络中,前向传播算法,主要是用来计算一层接着一层的输入值,通过计算出来的最后一层的输出值与真实值相计算就可以得到损失函数的值,然后通过反向传播,就可以优化参数。不断迭代前向传播与反向传播这个过程,就可以优化出最优参数。
假设有网络,结构如下图所示,以w7为例子,优化其参数。
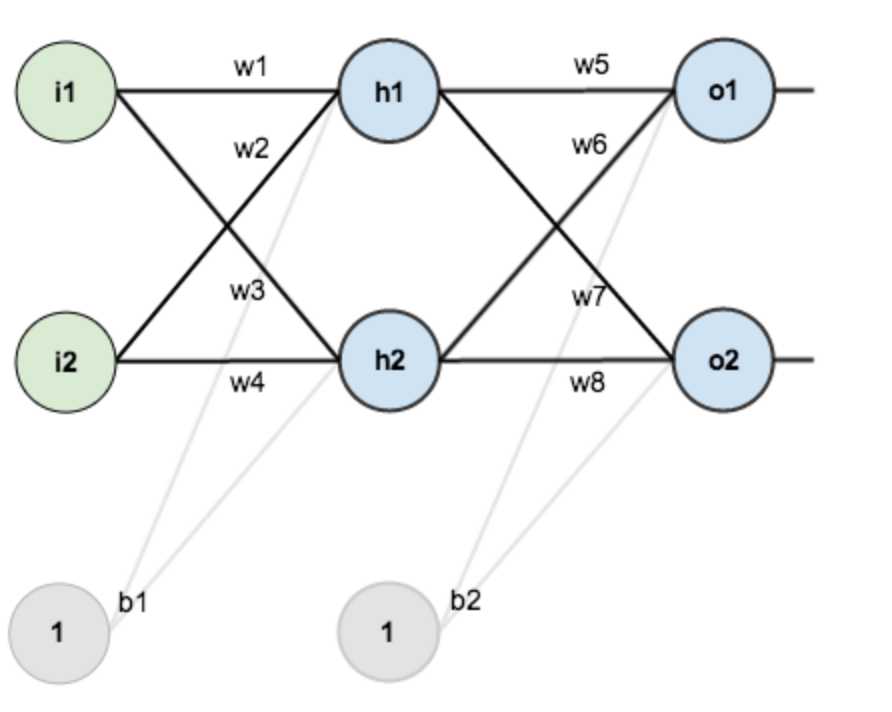
1、由上述介绍,首先前向传播算法第i层的输出oi为(现行变换通过激励函数):
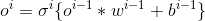
2、定义损失函数为(不唯一):
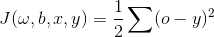
3、定义sigma激励函数为sigmoid。
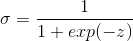
其中,z为线性变换
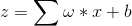
4、在初始化了所有参数之后,首先由前向传播算法,可以得到每一层的输入。在最后一层,可以得总误差:
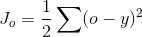
5、由微分方程可以得到:
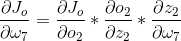
6、各部分:
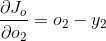
7、sigmoid导数是h(x)(1-h(x)), 因此:
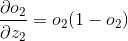
8、
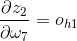
9、因此
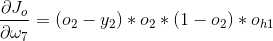
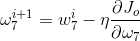
其中eta是学习率。对于同层的其他omega方法耶是一样的。
1、更新隐藏层的参数。以w1为例。
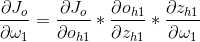
2、
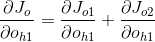
3、
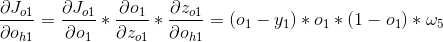
4、
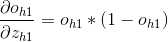
5、
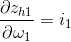
6、因此得:
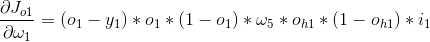
8、
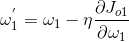
9、根据上述过程就可以得到同一隐藏层的所有参数。
标签:输出 迭代 技术分享 线性变换 sig 初始化 log 计算 ext
原文地址:https://www.cnblogs.com/ylxn/p/10166053.html