1.1正则表达式
正则表达式和字符串
在编程里字符串是涉及到最多的一种数据结构,对字符串操作的需要几乎无处不在。
比如判断一个字符串是否合法的email地址,虽然可以提取@前面和后面的子串,又再分别判断是否是单词和域名,但这样很麻烦,而且代码难以复用。
正则表达式式一种用来模糊匹配字符串的方法,它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配了”,否则该“没有匹配到该字符串”
需要导入正则的模块
import re
字符匹配(普通字符,元字符)
1.普通字符:数字字符和英文字母和自身匹配
2.元字符:. ^ $ * + ? {} [] () | \
re.方法("规则","匹配的字符串")
. 匹配任意一个字符,除了\n换行符


1 #findall查找所有字符 2 print(re.findall("a.","ssdfyildazvdfeewrae")) #[‘az‘, ‘ae‘] 匹配a后面的任意一个字符 3 print(re.findall("a..","ssdfyildazvdfeewrae")) #[‘azv‘] 匹配a后面的任意两个个字符
^ 匹配以什么开头的字符
1 re_str = "ssdfyildazvdfeewrae" 2 print(re.findall("^s..",re_str)) # [‘ssd‘] #匹配以s开头后面两个任意字符 3 print(re.findall("^aa",re_str)) #[] #匹配aa开头
$ 匹配以什么结尾
1 re_str = "ssdfyildaaazvdfeewrae" 2 print(re.findall("ee$",re_str)) #[] 3 print(re.findall("ae$",re_str)) #[‘ae‘]
* 字符* 匹配前面的字符 出现的0-无穷次
1 import re 2 3 re_str = "ssdfyilddddkaaazvdfeewrae" 4 5 # print(re.findall("*",re_str)) #报错,要加匹配字符 6 print(re.findall("d*",re_str))#匹配d出现的0到无穷次 没有,也匹配上了 7 # [‘‘, ‘‘, ‘d‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘dddd‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘d‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘] 8 print(re.findall("ld*k",re_str)) #[‘lddddk‘] #匹配ld*k 匹配*前面的d字符出现的0到无穷次 9 10 print(re.findall("sd*",re_str)) #[‘s‘, ‘sd‘] 匹配sd* d出现的0到无穷次 11 print(re.findall("ras*",re_str)) #[‘ra‘] 匹配ras* res中s出现的0到无穷次
+ 字符+ 匹配前面的一个字符出现的1-无穷次 ,最少有1次
1 re_str = "ssdfyilddddkaaazvddfeewrae" 2 3 print(re.findall("dd+",re_str)) #[‘dddd‘] 匹配dd+中d出现的一到无穷次 4 print(re.findall("d+",re_str)) #[‘d‘, ‘dddd‘, ‘dd‘] 匹配d+中d出现的一到无穷次
? 字符? 匹配前面字符重复零次或一次
1 name = "asdfqwzerzxcv" 2 print(re.findall("x?",name)) #匹配x字符出现的0次或者1次 3 # [‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘‘, ‘x‘, ‘‘, ‘‘, ‘‘] 4 print(re.findall("zx?",name)) #[‘z‘, ‘zx‘] #匹配zx x出现的0次或者1次
注:* + ?等都是贪婪匹配,也就是尽最大能力去匹配,匹配字符后面加?变成了惰性匹配,一般都是用贪婪匹配
1 name = "asdfqwzerzxcv" 2 print(re.findall("zx*?",name)) #[‘z‘, ‘z‘] #惰性匹配,最小匹配原则
{} 字符{n} 匹配字符出现的n次,字符{1,n}匹配字符出现1到n次
1 name = "aasdfqwzerzxcvaaaavv" 2 print(re.findall("aa{1,5}",name)) #[‘aa‘, ‘aaaa‘] #匹配aa a出现的一到5次之间 3 print(re.findall("aa{1,5}v",name)) #[‘aaaav‘] #匹配aa{1,5}v ,a出现的一到5次之间 4 print(re.findall("a{5}",name)) #[] 只匹配a出现的5次 5 print(re.findall("a{3}",name)) #[‘aaa‘] 只匹配a出现的3次
[] 字符[字符集] 匹配字符集中的某一个符号
1 name = "aasdfqawzerzxcvaaaavv" 2 print(re.findall("a[a]",name)) #[‘aa‘, ‘aa‘, ‘aa‘] #只匹配aa 3 print(re.findall("a[a]a",name)) #[‘aaa‘] #只匹配aaa 4 print(re.findall("f[.q]",name)) #[‘fq‘]#匹配f.或者fq 5 print(re.findall("f[.q]b",name)) ##匹配[] f.b或者fqb
[字符集] 里面的字符集都是普通字符,除了-,^.\
- ^ \这三个符号在字符集有特殊功能的符号,其它都是普通字符
1 [] 字符集中- 的方法 - 组成一个连接范围的数字 2 name = "aasdfqawzerzxcvaaaavv" 3 print(re.findall("a[a-z]",name))#[‘aa‘, ‘aw‘, ‘aa‘, ‘aa‘] #匹配a[a到z]的任意字符 4 alp_num = "a12a 34a5567asdfqwer" 5 print(re.findall("a[0-9 a-z]",alp_num)) #[‘a1‘, ‘a ‘, ‘a5‘, ‘as‘]#空格也是普通字符 6 print(re.findall("a[0-9a-zA-Z]",alp_num)) #[‘a1‘, ‘a5‘, ‘as‘] 7 8 9 []字符集中^的方法 ^非,把相反的给找出来 10 name = "aasdfqawzerzxcvaaaavv" 11 tes = "abc" 12 print(re.findall("[^0-9]",tes)) #[‘a‘, ‘b‘, ‘c‘] #把非0到9数字给匹配出来 13 print(re.findall("a[^0-9]",name))#[‘aa‘, ‘aw‘, ‘aa‘, ‘aa‘] 把匹配a字符集中非0到9数字给匹配出来 14 15 16 []字符集中\的方法,把普通的特殊字符变得有意义 17 aa = "advca11234" 18 print(re.findall("[\d]",aa)) #[‘1‘, ‘1‘, ‘2‘, ‘3‘, ‘4‘] #\是转义字符,把普通字符,实现特殊的功能
\ 元字符的转义符\
反斜杠后面跟元字符去除特殊功能,比如\. \*
反斜杠后边跟普通字符实现特殊功能比如\d
\d 匹配任何十进制数;它相当于类 [0-9]。
\D 匹配任何非数字字符;它相当于类 [^0-9]。
\s 匹配任何空白字符;它相当于类 [ \t\n\r\f\v]。
\S 匹配任何非空白字符;它相当于类 [^ \t\n\r\f\v]。
\w 匹配任何字母数字字符;它相当于类 [a-zA-Z0-9_]。
\W 匹配任何非字母数字字符;它相当于类 [^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格 ,&,#等
1 bb = "axs1233_sa _%" 2 print(re.findall("\d",bb)) #[‘1‘, ‘2‘, ‘3‘, ‘3‘] 3 print(re.findall("\D",bb)) #[‘a‘, ‘x‘, ‘s‘, ‘_‘, ‘s‘, ‘a‘, ‘ ‘, ‘_‘, ‘%‘] 4 print(re.findall("\s",bb)) #[‘ ‘] 5 print(re.findall("\S",bb)) #[‘a‘, ‘x‘, ‘s‘, ‘1‘, ‘2‘, ‘3‘, ‘3‘, ‘_‘, ‘s‘, ‘a‘, ‘_‘, ‘%‘] 6 print(re.findall("\w",bb))#[‘a‘, ‘x‘, ‘s‘, ‘1‘, ‘2‘, ‘3‘, ‘3‘, ‘_‘, ‘s‘, ‘a‘, ‘_‘]
1 cal = "()(_)(*)(s)12+(28*10+5+2-8-3*(2-1))" 2 print(re.findall("\(\)",cal)) #[‘()‘] #只匹配普通字符的括号() 3 print(re.findall("\([\w]\)",cal)) #[‘(_)‘, ‘(s)‘] #匹配(任意一个字母数字_)
1 gan = "\\" 2 print(gan)#\ python解释器中字符串\\,才表示一个\ 3 print(re.findall("\\\\",gan)) #[‘\\‘],其实就是一个\
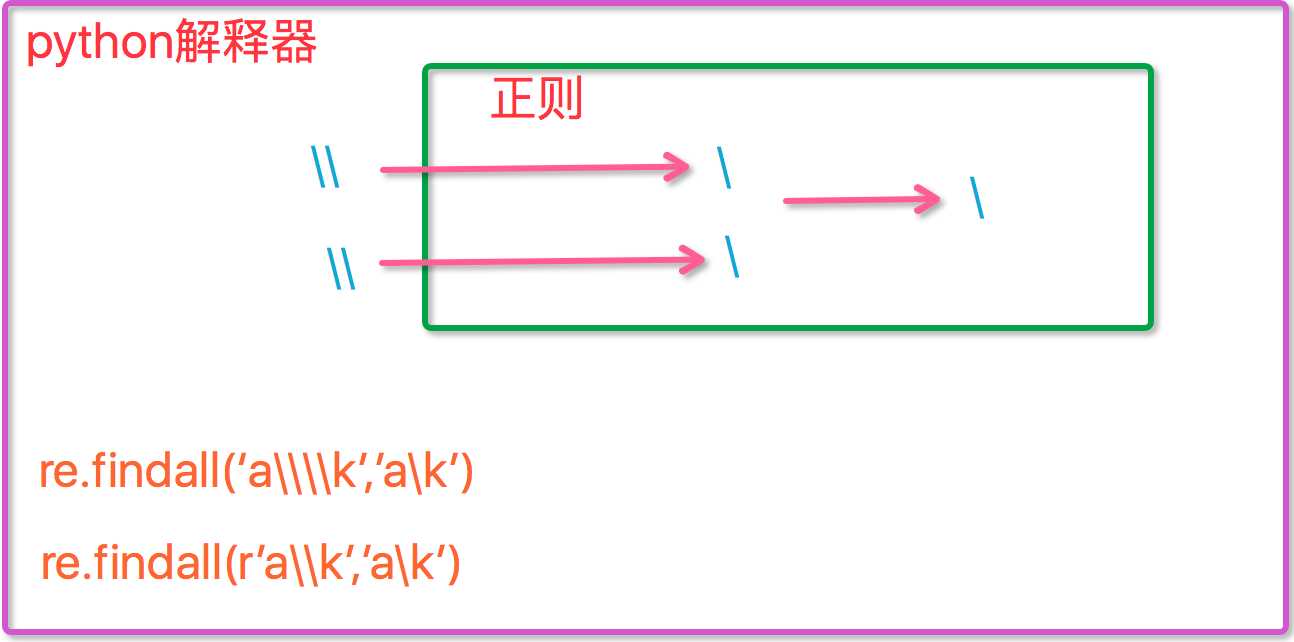
r"字符串" 表示原始字符串(r---> raw string)
| 字符a|字符b 匹配字符a或者字符b 的表示或得方法
1 ss = "abs,youbyy" 2 print(re.findall("a|b",ss))#[‘a‘, ‘b‘, ‘b‘] 3 print(re.findall("ou|y",ss)) #[‘y‘, ‘ou‘, ‘y‘, ‘y‘]
() (字符)优先匹配字符里面的内容。
1 tot = "asdasdasdasd" 2 print(re.findall("(asd)*",tot)) #[‘asd‘, ‘‘] #0到无穷匹配 3 print(re.findall("(asd)?",tot)) #[‘asd‘, ‘asd‘, ‘asd‘, ‘asd‘, ‘‘] #0到1次匹配asd 4 print(re.findall("(asd)+",tot)) #[‘asd‘] #1到无穷匹配 5 print(re.findall("(asd)",tot)) #[‘asd‘, ‘asd‘, ‘asd‘, ‘asd‘]
re模块的常用方法
1.re.findall()
1 import re 2 print(re.findall("a",bb)) #返回所有满足匹配条件的结果,放在列表里
2.re.match()
语法
re.match(pattern, string, flags=0)
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功re.match方法返回一个匹配位置的对象,否则返回None。(从最开始匹配)
我们可以使用group(num)或groups()匹配对象函数来获取匹配表达式。
| group(num=0) | 匹配的整个表达式的字符串,group() 可以一次输入多个组号,在这种情况下它将返回一个包含那些组所对应值的元组。 |
| groups() | 返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。 |
1 bb = "advca11234" 2 print(re.match("12",bb)) #None 不是开始位置匹配 3 print(re.match("adv",bb)) #开始位置匹配,返回匹配的位置对象 4 #<_sre.SRE_Match object; span=(0, 3), match=‘adv‘> 5 6 print(re.match("adv",bb).span()) #(0, 3) 获取匹配对象的位置 7 # 8 print(re.match("adv",bb).group()) # adv #获取匹配对象的结果内容 9 print(re.match("adv",bb).groups()) #() #获取模型中匹配到的分组结果 10 print(re.match("adv",bb).groupdict()) #{} #获取模型中匹配到的分组结果 {}
3re.search方法
re.search扫描整个字符串并返回第一成功的匹配
用法:re.search(pattern, string, flags=0)
匹配成功re.search方法返回一个匹配的对象,否则返回None
我们可以使用group(num)或groups()匹配对象函数来获取匹配表达式
1 bb = "advca11234" 2 print(re.search("\d+",bb)) 3 #返回一个函数匹配对象 span 是匹配的位置 math是匹配对象的内容 4 #<_sre.SRE_Match object; span=(5, 10), match=‘11234‘> 5 6 info = "yj18yj18yj19" 7 print(re.search("(?P<name>[a-z]+)",info).group("name")) #yj #得到特定的分组信息内容 8 print(re.search("(?P<name>[a-z]+)(?P<age>\d+)",info).group("name","age"))#(‘yj‘, ‘18‘) #得到特定的分组信息 ,以元祖返回 9 print(re.search("(?P<name>[a-z]+)(?P<age>\d+)",info).group())# yj18 #获取分组信息的所有内容、 10 print(re.search("(?P<name>[a-z]+)(?P<age>\d+)",info).groups()) #(‘yj‘, ‘18‘) 11 #得到分组的所有信息,以元祖返回 12 print(re.search("(?P<name>[a-z]+)(?P<age>\d+)",info).groupdict())# yj18 #获取分组的所有内容、 13 #{‘name‘: ‘yj‘, ‘age‘: ‘18‘} 以字典返回,分组信息 14 print(re.search("(?P<name>[a-z]+)(?P<age>\d+)",info)) #得到是分组的对象 15 16 #?P<name> 给信息做一个分组
re.match与re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
而re.search匹配整个字符串,直到找到一个匹配。
4re.sub() 用于替换字符串中的匹配项。
语法:re.sub(pattern, repl, string, count=0)
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
1 phone = "110-119-911-112" 2 print(re.sub(r"-"," ",phone,count=2))#检索字符串的-,把前两个替换成空格 3 #110 119 911-112
5re.split() 分割字符串
语法:split(pattern, string, maxsplit=0, flags=0):
maxsplit : 模式匹配后分割的最大次数,默认 0 表示替换所有的匹配。
1 alp = "a b c d" 2 print(re.split("\s+",alp,maxsplit=2)) 3 #[‘a‘, ‘b‘, ‘c d‘] #分割前两个的字符串个空格,以列表形式返回
6re.finditer() 方法,把找到的结果做成一个迭代器对象,取值用next()
语法和findall一样
1 phone = "110-119-911-112" 2 print(re.finditer("\d+",phone))#<callable_iterator object at 0x0000009E83BCAE10> 3 te = re.finditer("\d+",phone) 4 print(next(te).group()) #110 5 print(next(te).group()) #119 6 print(next(te).group()) #911
字符类
| [0-9] | 匹配任何数字。类似于 [0123456789] |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| [a-zA-Z0-9] | 匹配任何字母及数字 |
| [^aeiou] | 除了aeiou字母以外的所有字符 |
| [^0-9] | 匹配除了数字外的字符 |
特殊转义字符类
| 实例 | 描述 |
|---|---|
| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 ‘\n‘ 在内的任何字符,请使用象 ‘[.\n]‘ 的模式。 |
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 [^0-9]。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 [^ \f\n\r\t\v]。 |
| \w | 匹配包括下划线的任何单词字符。等价于‘[A-Za-z0-9_]‘。 |
| \W | 匹配任何非单词字符。等价于 ‘[^A-Za-z0-9_]‘。 |