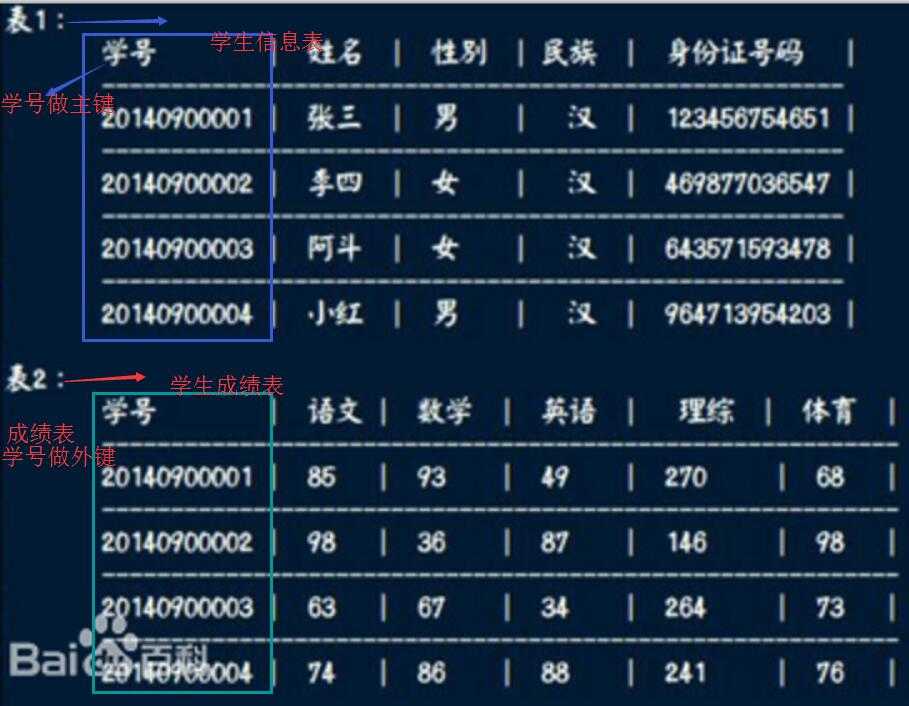
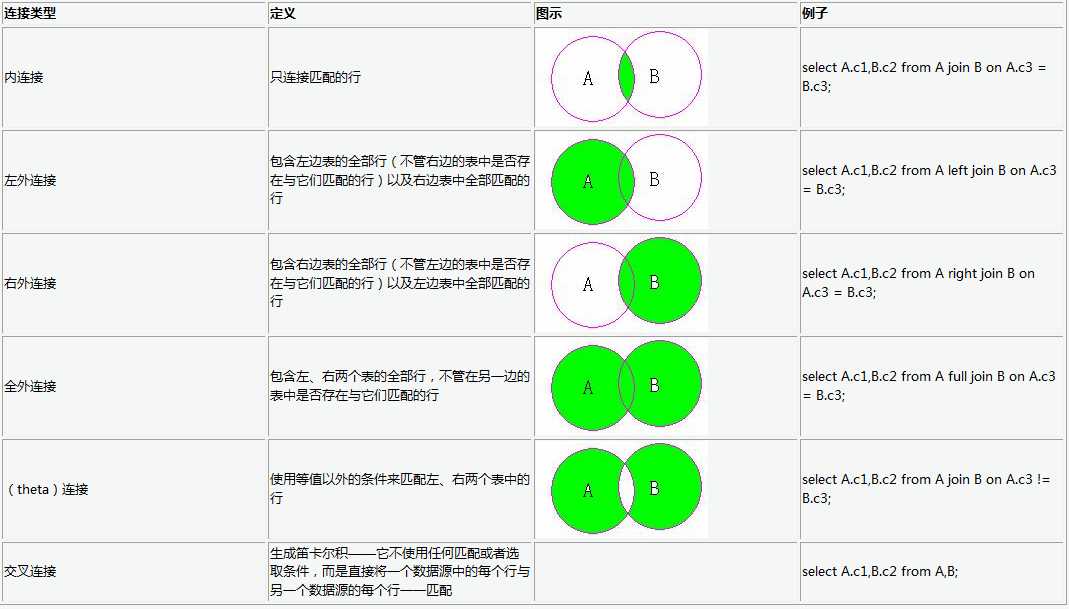
数据库是什么
简单理解:存放东西(数据)的仓库,我们可以对仓库的东西做一些操作(基本的:增删改查)
为什么要有数据库
最开始数据是以账簿类似的手工管理操作
计算机出来以后是以文件系统的方式来存储数据
由于各种原因很不方便于是出现了 数据库系统来管理数据

数据库的构成
1.数据库系统DBS
常用的数据的数据管理系统(DBMS)有:
DBMS(DataBase Management System):Mysql ,SQL server ,Oracle , DB2, Mariadb
RDBMS((Relational Database Management System):上述DBMS被称之为关系型数据库
2.SQL语句
|
1
2
3
|
- DDL(Data Definition Language)数据库定义语言,库、表、视图、索引、存储过程,包含create DROP ALTER语句- DML(Data Manipulation Language)数据库操作语言,包含insert,delete,update,select- DCL(Data Control Language)是数据库控制语言,。是用来设置或更改数据库用户或角色权限的语句,包括(grant,deny,revoke等)语句。 |
3.数据库访问技术
|
1
2
|
- JDBC(Java Data Base Connectivity,java数据库连接)是一种用于执行SQL语句的Java API- ODBC(Open Database Connectivity,开放数据库连接)它建立了一组规范,并提供了一组对数据库访问的标准API(应用程序编程接口),ODBC本身也提供了对SQL语言的支持,用户可以直接将SQL语句送给ODBC。 |
MYSQL介绍及安装
安装
注:centos平台
|
1
2
3
4
|
yum安装1 yum -y install mariadb mariadb-server 如果是centos7.x系列或则REDHAT7.x系列2 或者3 yum -y install mysql mysql-server 如果是centos6.x系列或则REDHAT6.x系列 |
也可以下载二进制包用编译安装,
也还可以用编译好的tar包,直接做相应权限和一些配置文件的修改即可用
这里就不介绍
启动
|
1
2
3
4
5
|
1 service mysqld start #开启 centos6.x系列或则REDHAT6.x系列2 chkconfig mysqld on #设置开机自启3 或者4 systemctl start mariadb centos7.x系列或则REDHAT7.x系列5 systemctl enable mariadb 7.x 系列的开机自启 |
查看
查看mysql是否启动成功,启动不成功会报错
|
1
2
|
1 ps aux |grep mysqld #查看进程2 netstat -an |grep 3306 #查看端口 |
设置密码
四种方式
|
1
2
3
4
|
1 mysqladmin -uroot password ‘123‘#设置初始密码,初始密码为空因此-p选项没有用2 mysqladmin -u root -p123 password ‘1234‘ #修改root用户密码3.SET PASSWORD FOR root=PASSWORD(’new password’);(对登录数据库后这种方式)4.UPDATE user SET password=PASSWORD(”new password”) WHERE user=’root’; (对登录数据库 后这种方式) |
登录
|
1
2
3
4
5
|
1 mysql #本地登录,默认用户root,空密码,用户为root@127.0.0.12 mysql -uroot -p1234 #本地登录,指定用户名和密码,用户为root@127.0.0.13 mysql -uroot -p1234 -h 10.0.0.17 #远程登录,用户为root@10.0.0.17注:远程访问server的数据库,还需要做一些权限设置,但是一般不会允许你远程登录 ,安全性,除非是测试的数据库 |
忘记密码
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
[root@controller ~]# service mysqld stop[root@controller ~]# mysqld_safe --skip-grant-table &[root@controller ~]# mysqlmysql> select user,host,password from mysql.user;+----------+-----------------------+-------------------------------------------+| user | host | password |+----------+-----------------------+-------------------------------------------+| root | localhost | *A4B6157319038724E3560894F7F932C8886EBFCF || root | localhost.localdomain | || root | 127.0.0.1 | || root | ::1 | || | localhost | || | localhost.localdomain | || root | % | *23AE809DDACAF96AF0FD78ED04B6A265E05AA257 |+----------+-----------------------+-------------------------------------------+mysql> update mysql.user set password=password("123") where user="root" and host="localhost";mysql> flush privileges;mysql> exit[root@controller ~]# service mysqld restart[root@controller ~]# mysql -uroot -p123 |
库备份
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
dbname参数表示数据库的名称;table表示备份那个数据库的表名backupname备份数据库名字第一种:备份一个数据库的那些表mysqldump -u username -p dbname table1 table2 ...-> BackupName.sql第二种:备份多个数据库mysqldump -u username -p --databases dbname2 dbname2 > Backup.sql加上了--databases选项,然后后面跟多个数据库第三种:备份所有库mysqldump -u username -p -all-databases > BackupName.sql第四种:就是将MySQL中的数据库文件直接复制出来。这是最简单,速度最快的方法。不过在此之前,要先将服务器停止,这样才可以保证在复制期间数据库的数据不会发生变化。如果在复制数据库的过程中还有数据写入,就会造成数据不一致。这种情况在开发环境可以,但是在生产环境中很难允许备份服务器。 注意:这种方法不适用于InnoDB存储引擎的表,而对于MyISAM存储引擎的表很方便。同时,还原时MySQL的版本最好相同。 第五种:第三方client软件备份 |
还原库
|
1
2
3
|
mysql -u root -p dbname< BackupName.sqldbname 是可选项 ,是用于某些表还原到那些库才需要用到dbname直接还原库不用加上dbname,也就是数据库名 |
SQL语句
库操作
库名
首字符是字母,其余部分可以是字母、数字、下划线、@、$
不能是关键字,如create database create
最长128位
不能是纯数字
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
|
查询有所有库show databases;mysql> show databases;+--------------------+| Database |+--------------------+| information_schema | #虚拟库,不占用磁盘空间,存储的是数据库启动后的一些参数(用户表信息,列信息,权限信息,字符信息),存放于内存中| mysql | #授权库,存放mysql所有的授权信息| performance_schema | #存放mysql服务的性能参数| test | #测试库+--------------------+5 rows in set (0.00 sec)创建库create database dbname查看某一个数据库show create database dbnamemysql> create database xixi; #创建Query OK, 1 row affected (0.00 sec)mysql> show create database xixi; #查看+----------+------------------------------------------------------------------+| Database | Create Database |+----------+------------------------------------------------------------------+| xixi | CREATE DATABASE `xixi` /*!40100 DEFAULT CHARACTER SET utf8mb4 */ |+----------+------------------------------------------------------------------+1 row in set (0.00 sec)选择数据库 use 库名;看看当前use了哪个库select database()mysql> use xixi;Database changedmysql> select database();+------------+| database() |+------------+| xixi |+------------+1 row in set (0.00 sec)修改用alter用删除库drop database 数据库名;mysql> drop database xixi; #删除库Query OK, 0 rows affected (0.01 sec)mysql> show databases;+--------------------+| Database |+--------------------+| information_schema || mysql || performance_schema || test |+--------------------+4 rows in set (0.00 sec) |
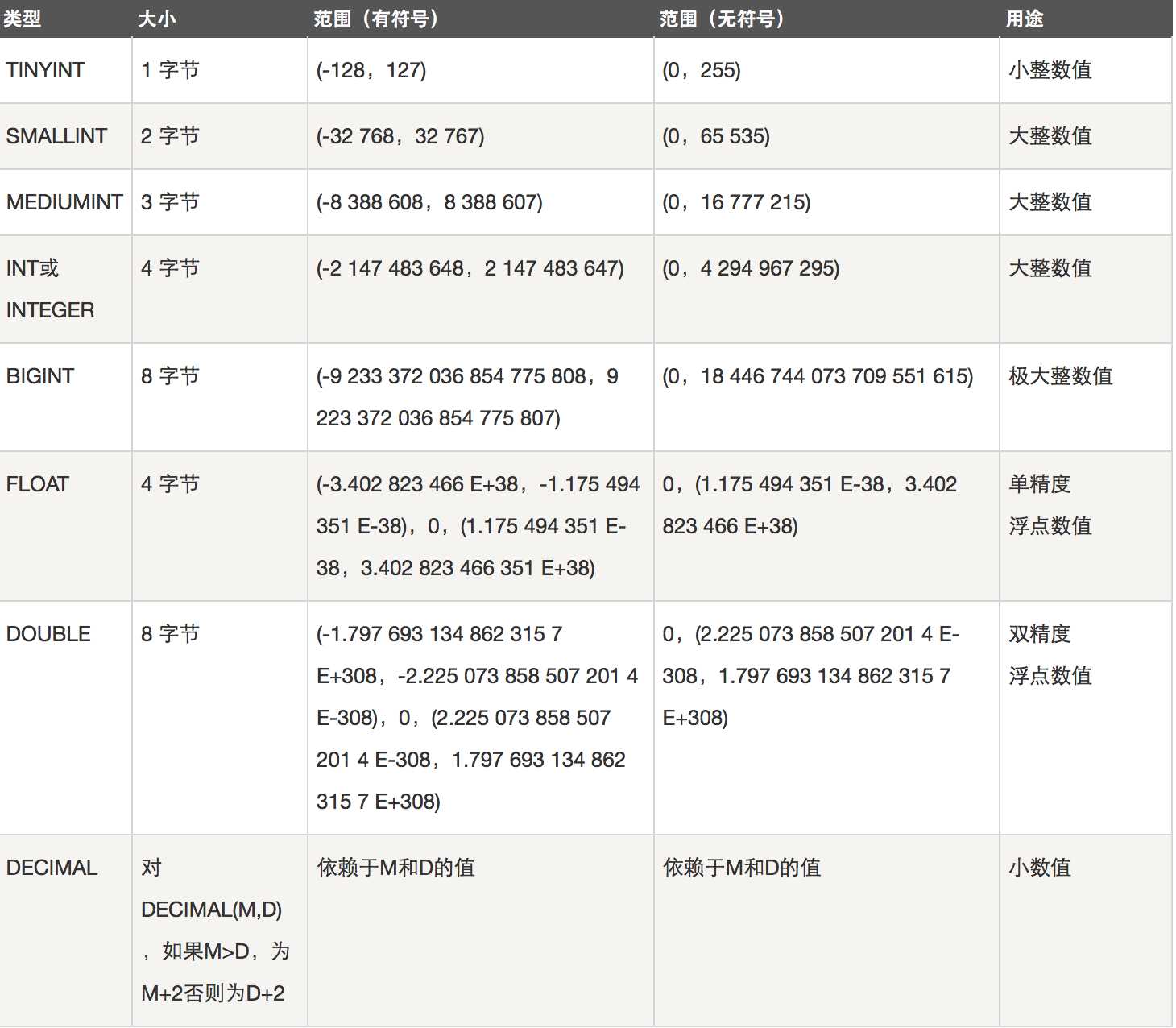
MYSQL数据类型
数值类型
下面的表显示了需要的每个整数类型的存储和范围。
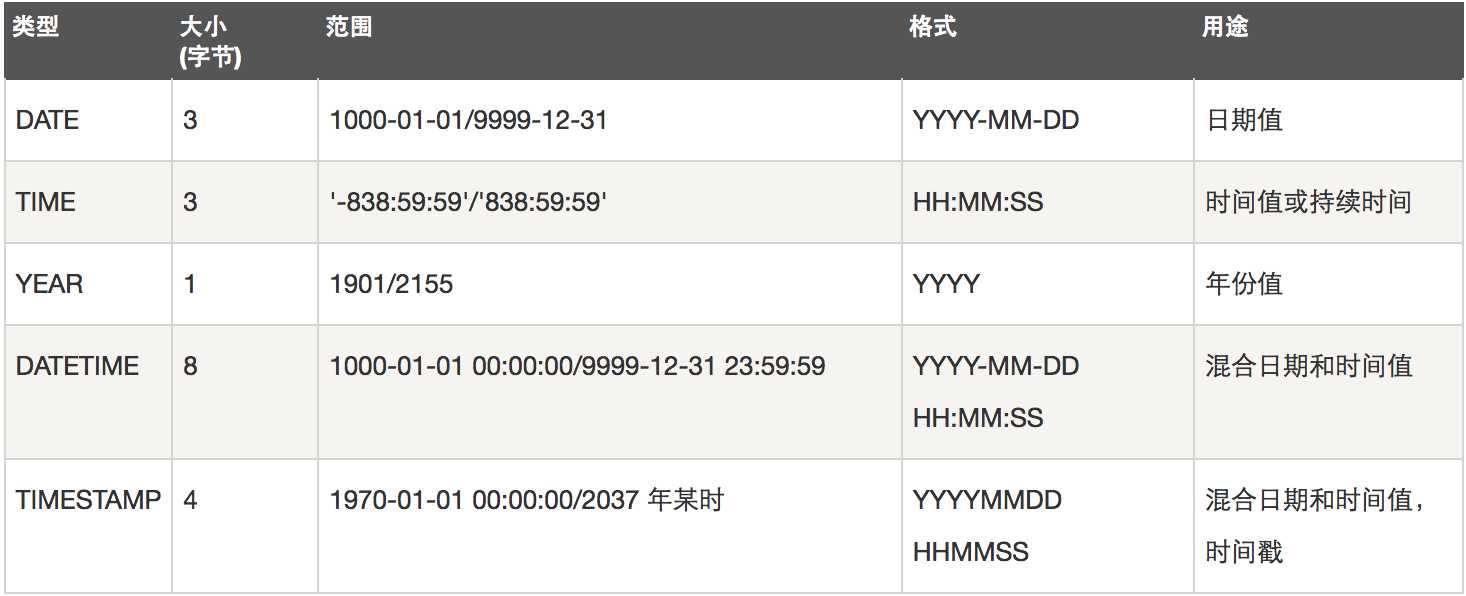
日期/时间类型
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
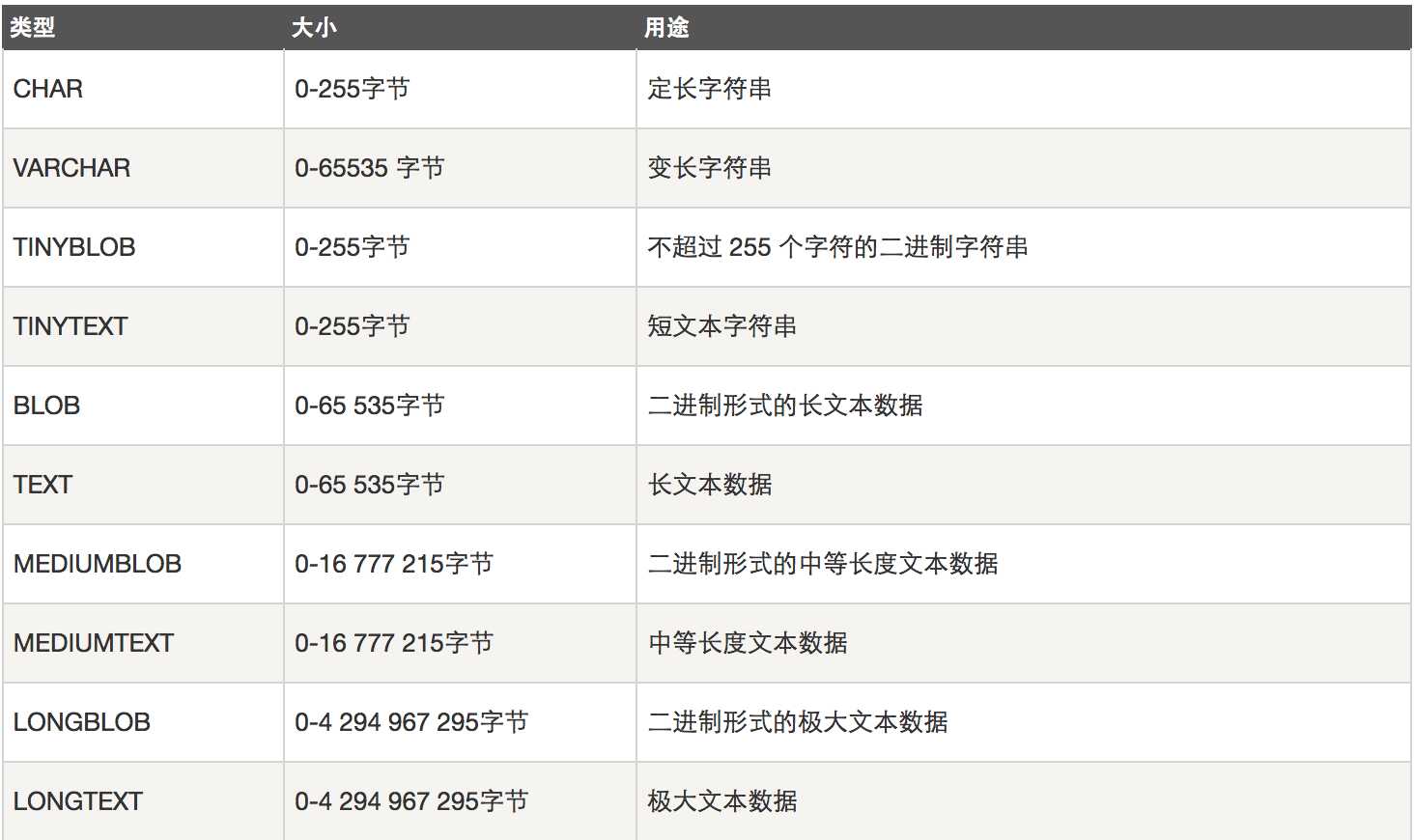
CHAR和VARCHAR类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换。
BINARY和VARBINARY类类似于CHAR和VARCHAR,不同的是它们包含二进制字符串而不要非二进制字符串。也就是说,它们包含字节字符串而不是字符字符串。
BLOB是一个二进制大对象,可以容纳可变数量的数据。有4种BLOB类型:TINYBLOB、BLOB、MEDIUMBLOB和LONGBLOB。它们只是可容纳值的最大长度不同。
有4种TEXT类型:TINYTEXT、TEXT、MEDIUMTEXT和LONGTEXT。这些对应4种BLOB类型,有相同的最大长度和存储需求。
上面这些的数据类型都存放在数据表里面的,现在介绍数据表操作
数据表操作
我们需要进入某一个库里才能创建表
一张表必须属于一个库
表分成:字段+记录
创建表
语法:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
create table 表名 ( 字段名1 类型 (宽度) 约束条件, 字段名2 类型(宽度) 约束条件, 字段名3 类型(宽度) 约束条件, ....... ); 注 :同一张表中,字段名不能相同字段名和类型必须有宽度和约束条件为可选项``````mysql> create table host ( -> id int(10), -> hostname char(20), -> port int(5) -> );Query OK, 0 rows affected (0.11 sec) |
查看表
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
|
1.查看某个库有多少表show tables;2.看看某个新建表信息show create table 表名;3.查看表结构desc 表名;4.查看表记录(也就是相应字段下面的内容)查看表的所有字段内容*select * from 表名;mysql> select * from host;Empty set (0.00 sec)5.查看表内容查看表的某些字段的内容select id from host; #查看host表的id字段的内容select id,port from host; #查看host表的id字段和port字典的内容``````mysql> show tables;+----------------+| Tables_in_xixi |+----------------+| host |+----------------+1 row in set (0.00 sec)mysql> show create table host;+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------+| Table | Create Table |+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------+| host | CREATE TABLE `host` ( `id` int(10) DEFAULT NULL, `hostname` char(20) DEFAULT NULL, `port` int(5) DEFAULT NULL) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |+-------+-------------------------------------------------------------------------------------------------------------------------------------------------------------+1 row in set (0.00 sec)mysql> mysql> desc host;+----------+----------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+----------+----------+------+-----+---------+-------+| id | int(10) | YES | | NULL | || hostname | char(20) | YES | | NULL | || port | int(5) | YES | | NULL | |+----------+----------+------+-----+---------+-------+3 rows in set (0.01 sec)field 代表字段名type代表该字段类型,Null 该字段是否可以为空default 该字段的默认设置extra 额外的设置mysql> select * from xixi.host;Empty set (0.00 sec) #empty这里表示一张空表mysql> select id,port from xixi.host;Empty set (0.00 sec) |
修改表结构
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
1.往表里添加新字段alter table 表名 add 字段名 类型(宽度) 约束条件;添加多个字段alter table 表名 add 字段名1 类型(宽度) 约束条件, add 字段名2 类型(宽度) 约束条件; mysql> alter table host -> add ip DOUBLE, -> add brand VARCHAR(30);Query OK, 0 rows affected (0.07 sec)Records: 0 Duplicates: 0 Warnings: 02.删除表字段alter table 表名 drop 字段名;删除多个字段跟添加类似mysql> alter table host drop brand;Query OK, 0 rows affected (0.02 sec)Records: 0 Duplicates: 0 Warnings: 0修改表字段类型after | before 字段名alter table 表名 modify 字段名 修改的类型 约束条件 往字段名2修改到字段名1的后面alter table 表名 modify 字段名2 修改的类型 约束条件 after 字段名13.修改字段名修改字段名changealter table 表名 change 原来的字段名 新的字段名 类型;4.修改表名rename table 原表名 to 新表面5. 修改表所有的字符集alter table 表名 character set 字符集; |
表记录操作
往表里插入内容
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
语法insert into 表名(字段1,字段2,字段3...) values(值1,值2,值3)第一种:单条插入mysql> use xixi;Database changedmysql> insert into host(id,hostname,port) value (1,"mysql",3306);Query OK, 1 row affected (0.00 sec)第二种:多条插入mysql> insert into host(id,hostname,port) values -> (2,"webapp",8080), -> (3,"HA",9906), -> (4,"LB",3306);Query OK, 3 rows affected (0.00 sec)Records: 3 Duplicates: 0 Warnings: 0第三种:指定字段插入mysql> insert into host(hostname) values ("webapp2");Query OK, 1 row affected (0.04 sec)第四种:完整字段插入是根据表字段的顺序依次插入内容,内容必须要跟字段一样多,这一种也可以多条插入mysql> insert into host values (5,"webapp3",8081);Query OK, 1 row affected (0.00 sec)查看刚刚插入的所有内容mysql> select * from host;+------+----------+------+| id | hostname | port |+------+----------+------+| 1 | mysql | 3306 || 2 | webapp | 8080 || 3 | HA | 9906 || 4 | LB | 3306 || NULL | webapp2 | NULL || 5 | webapp3 | 8081 |+------+----------+------+6 rows in set (0.00 sec)第五种:set插入记录insert into 表名 set 字段名=值; |
删除表记录
删除记录可根据where条件来删除
|
1
2
3
4
5
6
7
8
9
10
|
语法delete from 表名 where 字段名=值 and/or 字段名=值删除一个表delete from 表名truncate table 表名delete和truncate的区别delete是对这个表逐条删除,可通过一些技术进行修复这个表销毁表的所有记录(不可恢复) |
表记录查询
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
select语句只是起查询做用,并不会真正的修改数据内容查询表的所有记录内容slect * from 表名;根据指定字段查询记录select 字段名,字段名,字段名..... from 表名查询去除重复的记录的字段select distinct 字段名 from 表名;查询字段加10后并去除重复的字段,显示的后的记录,不会真正影响数据本身的内容select distinct 字段名+10 from 表名;给查询某些字段做别名,做显示用的select 字段名1 as 别名1, 字段名2 as 别名2,...... from 表名as可去掉,但是一般加上 |
表记录修改
根据某一个条件字段来修改,不加where条件则该字段内容全部全改
语法:
|
1
|
update 表名 set 字段名=值, 字段名=值,字段名=值....... where 字段名=值; |
where子句
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
运算符= 等于<> 不等于> 大于< 小于>= 大于等于<= 小于等于BETWEEN 在某个范围内 常用结合andLIKE 搜索某种模式AND 与运算符 如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。OR 或者运算符 如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。通配符:% 替代一个或多个字符_ 仅替代一个字符[charlist] 字符列中的任何单一字符[^charlist]或者[!charlist] 不在字符列中的任何单一字符IN 操作符WHERE 字段名 IN (value1,value2,...) #语法IN 操作符允许我们在 WHERE 子句中规定多个值。查找IN里面的值 |
通配符常用like联合起来用
select 很多情况都与where字句结合一起使用
|
1
2
|
语法SELECT 字段名称 FROM 表名称 WHERE 列 运算符 值 |
ORDER BY 字句
ORDER BY 语句用于根据指定的结果对结果集进行排序
默认按照ASC升序排序 由低到高
可以使用 DESC 关键字。来进行降序 ,由高到低
关键字:ASC DESC
|
1
2
|
语法:SELECT 字段 FROM 表名 ORDER BY 字段,字段 关键字; |
GROUP BY 子句
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
语法
|
1
|
SELECT 字段名, 函数(字段名) FROM 表名 HAVING GROUP BY 字段名 |
常用的聚合函数
|
1
2
3
4
5
6
7
8
|
sum(字段名) 对该字段进行求和count(字段名) 查看该字段有多少记录avg(字段名) 对该段进行求平均值ifnull(字段名,0) 把字段中null的记录替换成0max(字段名) 对该字段求最大值min(字段名) 对该字段求最小值注:聚合函数可以互相嵌套 例如:max(ifnull(字段名,0)) |
HAVING 字句
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用
语法:
|
1
|
SELECT 字段名, 函数(字段名) FROM 表名 WHERE 字段名 操作值(运算符和值) GROUP BY 字段 HAVING 函数(字段名) 操作值 |
LIMIT 关键字
limit 数字 查看number条记录
limit 2,2 相同number,跳过number条,查看number条记录 (跳过两条显示两条记录)
limit 2,5 不同number的范围 , 查看2到5条的记录类似索引的查找
语法:
|
1
|
select * from 表名 limit 数字; #查看几条记录 |
小结:
Select from where group by having order by
Mysql在执行sql语句时的执行顺序:from where select group by having order by