标签:div 红色 加速 inf load roo eps 结合 想法
我们初学的算法一般都是从SGD入门的,参数更新是:

它的梯度路线为:

但是可以看出它的上下波动很大,收敛的速度很慢。因此根据这些原因,有人提出了Momentum优化算法,这个是基于SGD的,简单理解,就是为了防止波动,取前几次波动的平均值当做这次的W。这个就用到理论的计算梯度的指数加权平均数,引进超参数beta(一般取0.9):
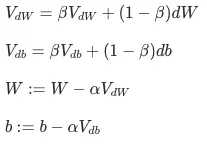
beta和1-beta分别代表之前的dW权重和现在的权重。
效果图如下(红色):

下面继续另一种加速下降的一个算法RMSprop,全称root mean square prop。也用到权重超参数beta(一般取0.999),和Momentum相似:

其中dW的平方是(dW)^2,db的平方是(db)^2。如果严谨些,防止分母为0,在分数下加上个特别小的一个值epsilon,通常取10^-8。
效果图如下(绿色):

研究者们其实提出了很多的优化算法,可以解决一些问题,但是很难扩展到多种神经网络。而Momentum,RMSprop是很长时间来最经得住考研的优化算法,适合用于不同的深度学习结构。所以有人就有想法,何不将这俩的方法结合到一起呢?然后,pia ji一下,Adam问世了。全程Adaptive Moment Estimation。算法中通常beta_1=0.9,beta_2=0.999。
算法为(很明显看出是两者的结合,其中多了一步V和S的调节,t为迭代次数,除以1-beta^t表示越近的重要,越远的就可以忽视):

因为Adam结合上述两种优化算法的优点于一身,所以现在经常用的是Adam优化算法。
标签:div 红色 加速 inf load roo eps 结合 想法
原文地址:https://www.cnblogs.com/lijie-blog/p/10184547.html