标签:共享库 自身 引入 扩展 技术 imp python解释器 分享图片 就是
一. 模块 import
加载的模块一共分成四个通用类别:
1.使用python编写的py文件
2.已被变异为共享库活着DLL或者C或者C++的扩展
3.包好一组模块的包
4.使用c编写并连接到python解释器的内置模块
导入模块有两种方式:
1. import
2. from xxx import xxxx
1.导入模块的执行的步骤
1.为导入的模块创立新的名称空间
2. 在新建的名称空间中运行该模块中的代码
3. 创建模块的名字. 并使用该名称作为该模块在当前模块中引用的名字
模块在导入的时候会创建其自己的名称空间. 所以. 我们在使用模块中的变量的时候一般是不会产生冲突的.
我们可以使用globals来查看模块的名称空间
import yitian
print(globals())
结果
{‘__name__‘: ‘__main__‘, ‘__doc__‘: None, ‘__package__‘: None, ‘__loader__‘: <_frozen_importlib_external.SourceFileLoader object at 0x000002D6FA56D0F0>,
‘__spec__‘: None, ‘__annotations__‘: {}, ‘__builtins__‘: <module ‘builtins‘ (built-in)>, ‘__file__‘:
‘D:/pyworkspace/untitled/day25 模块和包/jinyong.py‘, ‘__cached__‘: None, ‘yitian‘: <module ‘yitian‘ from ‘D:\\pyworkspace\\untitled\\day25 模块和包\\yitian.py‘>}
2.自定义模块
在不同的模块中一如了同一个模块.并且在某一模块中改变了被引入模块中的全局变量.则其他模块看到的值也跟着边.原因是python的模块只会引入一次. 大家共享同一个名称空间
import yitian print(yitian.content) content = "我是主文件" print(content)
结果#
我是yitian
我是主文件
在python中.每个模块作为程序运行的入口时.此时该模块的__name__时"__mian__".而如果我们把模块导入时,此时模块内部的__name__就是该模块自身的名字
在jinyong文件中 import yitian2 yitian2中: print(__name__) 运行jinyong 结果 yitian2
导入模块的顺序:
1.所有的模块导入都要写在最上面.这是最基本的
2.先引入内置模块
3.再引入扩展模块
4.最后引入你自定义的模块
二. from xxx import xxx
1.部分导入.当一个模块中的内容过多的时候.我们可以选择性的导入要使用的内容. 也支持 as
jinyong文件中
from yitian2 import chi chi()
如果当前文件中出现了重名的变量时,会覆盖掉模块引入的那个变量
yitian2:
content = "我是yitian2"
def chi():
print("我是yitian2中的函数chi")
jinyong:
import yitian2 print(yitian2.content) content = 2 print(content)
结果:
我是yitian2 2
2.有一种特殊的写法 from xxx import *
此时是把模块中的所有内容都导入.如果模块中没有写出__all__则默认所有内容都导入.如果写了__all__此时导入的内容就是在__all__列表中列出来的所有名字
# yitian.py
__all__ = ["he"]
def chi():
print("我是yitian2中的函数chi")
def he():
print("我是yitian2中的函数he")
# test.py from yitian2 import * he() chi() # 报错,因为all中只写了 ‘ he ‘ 这个函数
三.自定义包
一个表达式 - > 一条语句 - > 语句块 - > 函数 ->类 ->模块 -> 包 -> 项目
包就是我们的文件夹,包内可以写很多个模块.
查找路径是:sys.path,随动. 跟着启动文件所在的位置变化
我们先创建一些包:
import os os.makedirs(‘glance/api‘) os.makedirs(‘glance/cmd‘) os.makedirs(‘glance/db‘) l = [] l.append(open(‘glance/__init__.py‘,‘w‘)) l.append(open(‘glance/api/__init__.py‘,‘w‘)) l.append(open(‘glance/api/policy.py‘,‘w‘)) l.append(open(‘glance/api/versions.py‘,‘w‘)) l.append(open(‘glance/cmd/__init__.py‘,‘w‘)) l.append(open(‘glance/cmd/manage.py‘,‘w‘)) l.append(open(‘glance/db/__init__.py‘,‘w‘)) l.append(open(‘glance/db/models.py‘,‘w‘)) map(lambda f:f.close() ,l)
运行创建之后,结果如下:
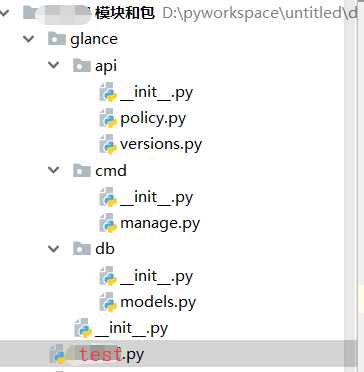
以下是每个文件的放的代码
# policy.py
def get():
print("from policy.py")
# versions.py
def create_resource(conf):
print("我是versions.py")
#manage.py
def main():
print(‘我是manage.py‘)
#models.py
def register_models(engine):
print(‘我是models.py‘)
之后我们引包
# test.py
import glance.db.models glance.db.models.register_models("哈哈") # 结果 我是models.py
包里的__init__, 只要是第一次导入包或者是包的任何其他部分,都会先执行__init__.py文件,
# glance的__init__.py
print("这里是glance的__init__文件")
#test.py import glance.db.models #结果 这里是glance的__init__文件
不论使用绝对导入,还是相对导入,启动文件要放在最外面
标签:共享库 自身 引入 扩展 技术 imp python解释器 分享图片 就是
原文地址:https://www.cnblogs.com/robertx/p/10196508.html