标签:不一致 初始化 mysql 5.7 解压 表结构 灵活 轻量级 数据一致性 索引
上一片博文中,我们说明了mysqldump的备份与恢复。因为mysqldump是单线程导出,单线程恢复的,因此备份与恢复的时间比较长!
首先来安装mydumper:
下载源码:https://github.com/maxbube/mydumper
安装:
1解压 unzip mydumper-master 2:安装依赖包 yum install glib2-devel mysql-devel zlib-devel pcre-devel zlib gcc-c++ gcc cmake -y 3:编译安装 cd mydumper-master cmake . make make install
[root@test3 mydumper-master]# make install
[ 62%] Built target mydumper
[100%] Built target myloader
Install the project...
-- Install configuration: ""
-- Installing: /usr/local/bin/mydumper
-- Removed runtime path from "/usr/local/bin/mydumper"
-- Installing: /usr/local/bin/myloader
-- Removed runtime path from "/usr/local/bin/myloader"
博文参考地址: http://www.ywnds.com/?p=7267
mydumper&myloader是用于对MySQL数据库进行多线程备份和恢复的开源 (GNU GPLv3)工具。开发人员主要来自MySQL、Facebook和SkySQL公司,目前由Percona公司开发和维护,是Percona Remote DBA项目的重要组成部分,包含在Percona XtraDB Cluster中。
mydumper的特点:
1:C语言写的,轻量级。
2:多线程备份,执行速度比mysqldump快N倍,并支持行级chunk备份。
3:事务性和非事务性表一致的快照(适用于0.2.2以上版本)。
4:快速的文件压缩。
5:支持导出binlog。
6:多线程恢复(适用于0.2.1以上版本)。
7:以守护进程的工作方式,定时快照和连续二进制日志(适用于0.5.0以上版本)。
8:支持从库备份时记录主库的position,且不需要关闭slave sql线程(mysqldump需要关闭sql线程);并且支持同时记录主从position(mysqldump不支持)。
9:开源 (GNU GPLv3)。
多线程导出原理:
mydumper原理与mysqldump原理类似,最大的区别是引入了多线程备份,每个备份线程备份一部分表,当然并发粒度可以到行级,达到多线程备份的目的。这里要解决最大一个问题是,如何保证备份的一致性,其实关键还是在于FTWRL。对于非Innodb表,在释放锁之前,需要将表备份完成。对于Innodb表,需要确保多个线程都能拿到一致性位点,这个动作同样要在持有全局锁期间完成,因为此时数据库没有读写,可以保证位点一致。所以基本流程如下:先备份no-innodb表数据在备份innodb数据。
在MySQL 5.7版本中,官方发布了一种新的备份工具mysqlpump,也是多线程的,其实现方式给人耳目一新的感觉,但遗憾的是其仍为表级别的并行且不支持position点的记录。而mydumper能够实现记录级别的并行备份,其备份框架由主线程和多个工作线程组成,备份流程可见下图:
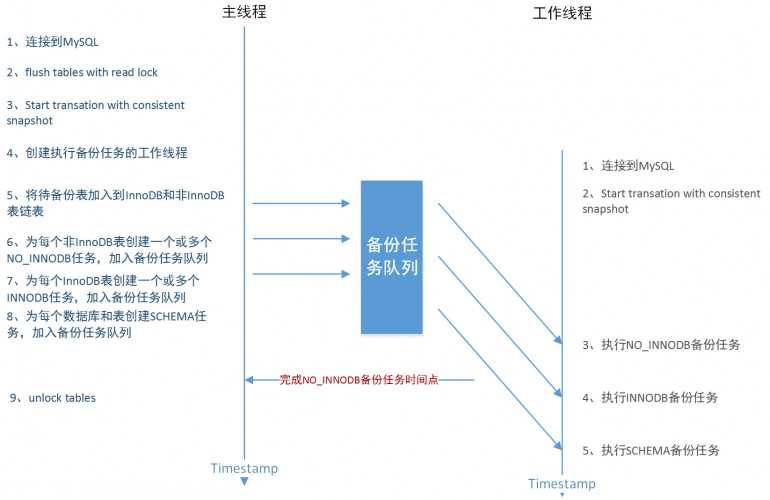
主线程负责建立数据一致性备份点、初始化工作线程和为工作线程推送备份任务:
工作线程负责将备份任务队列中的任务按顺序取出并完成备份:
mydumper的记录级备份由主线程负责任务拆分,由多个工作线程完成。主线程通过将表数据拆分为多个chunk,每个chunk作为一个备份任务。表数据拆分方式如下所述:mydumper优先选择主键索引的第一列作为chunk划分字段,若不存在主键索引,则选择第一个唯一索引作为划分依据,若还不存在,则选择区分度(Cardinality)最高的任意索引。如果还是无法满足,则只能进行表级的并行备份。在确定了chunk划分字段后,先获取该字段的最大和最小值,再通过执行“explain select field from db.table”来估计该表的记录数,最后根据所设的每个任务(文件)记录数来将该表划分为多个chunk。如下图所示:
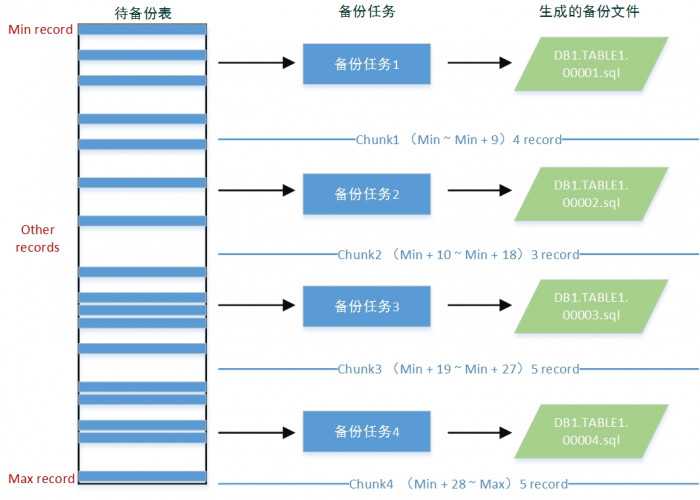
以上描述可知,mydumper并不能保证记录级备份时,每个备份任务中的记录数是相同的。另外,目前记录级备份存在一个bug:所用索引字段为负数时主线程会进入死循环无法退出,导致备份失败。
与mysqldump另一个不同是, mydumper为每个备份任务建立至少一个备份文件。在0.9.1版本中,文件类型包括schema-create、schema、schema-post文件等表元数据文件分别用保存建数据库语句、建表语句(包括触发器)、函数/存储过程/事件定义语句等;数据文件可以根据用户设置为固定大小或固定记录数的文件。这样便以进行更细粒度的数据恢复和数据删除,比如可以在myloader的时候仅选择某几个数据库/表进行恢复。
网易对mydumper的改进
mydumper是一款优秀的备份工具,但也存在不足,包括多线程导出数据对实例业务的影响、逻辑备份方式对热点数据污染和持锁时对业务的阻塞等。网易RDS在mydumper实践中对其进行了多方面的优化。
多线程备份固然好,但在进行备份时往往数据库还在正常提供对外服务,多线程全表select数据会占用很大部分的系统IO能力,导致正常的业务IO性能下降,严重时甚至会使数据库连接爆掉。通过为mydumper增加负载自适应能力来最大限度缓解对线上业务影响:工作线程在每次数据导出前,都会首先观察实例的当前负载情况,举MySQL状态Thread_connected为例,其反映的是目前已连接到该实例的请求数,如果该数值大于设定的阈值,则本次导出操作会暂停,直到数值小于阈值才会恢复,这样就起到了根据实例业务负载情况,灵活调整用于数据导出的线程数来适应线上业务负载的作用。
逻辑备份的全表select不可避免会污染InnoDB Buffer Pool的热点数据,缓存的热点数据被换出,降低了命中率的同时增大了业务的IO量,在使用mydumper时应尽量减小对Buffer Pool的影响;通过调整Buffer Pool的热点算法,使得热点数据尽可能不被换出。修改innodb_old_blocks_time和innodb_old_blocks_pct,用于将全表select进入Buffer Pool放在其old sublist中,同时减小old sublist块在Buffer Pool中的比例,起到最小化污染的作用。
在进行数据备份时,由于MyISAM表是非事务的,为了得到一致性的数据,导出MyISAM表需要全程持有读锁。在通常的MySQL实例中,MyISAM表数据都是很少的,所以持锁时间很短,但若有实例存在大量的MyISAM表数据,那么就会因持锁时间过长对业务的数据更新和插入造成影响。通过为mydumper增加持锁超时时间来避免该问题,所在数据备份过程中,持锁时间超过所设置时间,则mydumper返回失败,通过将MyISAM表转化为InnoDB表后再开始导出。
此外,在对大数据量数据库进行备份时,往往需要耗费较长时间,如果能够实时了解备份进度,相信是一个很好的体验,为此,给mydumper增加了进度查询功能,能够查询mydumper所需执行的所有备份任务数、当前已经完成的备份任务数及每个备份任务所花费时间。
备份工具的使用:

$ mydumper --help Usage: mydumper [OPTION...] multi-threaded MySQL dumping Help Options: -?, --help Show help options Application Options: -B, --database #需要备份的数据库,一个数据库一条命令备份,要不就是备份所有数据库,包括mysql. -T, --tables-list #需要备份的表,用逗号分隔. -o, --outputdir #备份文件目录. -s, --statement-size #生成插入语句的字节数,默认1000000,这个参数不能太小,不然会报Row bigger than statement_size for tools.t_serverinfo. -r, --rows #试图用行块来分割表,该参数关闭--chunk-filesize. -F, --chunk-filesize #行块分割表的文件大小,单位是MB. -c, --compress #压缩输出文件. -e, --build-empty-files #即使表没有数据,也产生一个空文件. -x, --regex #正则表达式匹配,如‘db.table‘. -i, --ignore-engines #忽略的存储引擎,用逗号分隔. -m, --no-schemas #不导出表结构. -d, --no-data #不导出表数据. -G, --triggers #导出触发器. -E, --events #导出事件. -R, --routines #导出存储过程. -k, --no-locks #不执行共享读锁,警告:这将导致不一致的备份. --less-locking #减到最小的锁在innodb表上. -l, --long-query-guard #设置长查询时间,默认60秒,超过该时间则会报错:There are queries in PROCESSLIST running longer than 60s, aborting dump. -K, --kill-long-queries #kill掉长时间执行的查询,备份报错:Lock wait timeout exceeded; try restarting transaction. -D, --daemon #启用守护进程模式. -I, --snapshot-interval #dump快照间隔时间,默认60s,需要在daemon模式下. -L, --logfile #使用日志文件,默认标准输出到终端. --tz-utc #备份的时候允许备份Timestamp,这样会导致不同时区的备份还原会出问题,默认关闭,参数:--skip-tz-utc to disable. --skip-tz-utc --use-savepoints #使用保存点记录元数据的锁信息,需要SUPER权限. --success-on-1146 #Not increment error count and Warning instead of Critical in case of table doesn‘t exist. --lock-all-tables #锁全表,代替FLUSH TABLE WITH READ LOCK. -U, --updated-since #Use Update_time to dump only tables updated in the last U days. --trx-consistency-only #Transactional consistency only. -h, --host #The host to connect to. -u, --user #Username with privileges to run the dump. -p, --password #User password. -P, --port #TCP/IP port to connect to. -S, --socket #UNIX domain socket file to use for connection. -t, --threads #备份执行的线程数,默认4个线程. -C, --compress-protocol #在mysql连接上使用压缩协议. -V, --version #Show the program version and exit. -v, --verbose #更多输出, 0 = silent, 1 = errors, 2 = warnings, 3 = info, default 2.
myloader --help Usage: myloader [OPTION...] multi-threaded MySQL loader Help Options: -?, --help Show help options Application Options: -d, --directory #备份文件所在的目录. -q, --queries-per-transaction #每个事务的query数量, 默认1000. -o, --overwrite-tables #如果表存在则先删除,使用该参数,需要备份时候要备份表结构,不然还原会找不到表. -B, --database #指定需要还原的数据库. -s, --source-db #还原的数据库. -e, --enable-binlog #启用二进制日志恢复数据. -h, --host #The host to connect to. -u, --user #Username with privileges to run the dump. -p, --password #User password. -P, --port #TCP/IP port to connect to. -S, --socket #UNIX domain socket file to use for connection. -t, --threads #使用的线程数量,默认4. -C, --compress-protocol #连接上使用压缩协议. -V, --version #Show the program version and exit. -v, --verbose #更多输出, 0 = silent, 1 = errors, 2 = warnings, 3 = info, default 2.
备份实例如下:
[root@test3 ~]# mydumper -u root -p 123456 -B employees -c -t 5 -l 300 -s 10000000 -o backup
#备份的库时MySQL官方给出的测试库,员工库大概有30万条数据,备份确实蛮快的。
因为之前已经开启了general log日志,因此我们来看一下general的记录!
2018-11-28T07:40:24.379010Z 38 Connect root@localhost on employees using Socket 2018-11-28T07:40:24.379281Z 38 Query SET SESSION wait_timeout = 2147483 2018-11-28T07:40:24.379403Z 38 Query SET SESSION net_write_timeout = 2147483 2018-11-28T07:40:24.379513Z 38 Query SHOW PROCESSLIST 2018-11-28T07:40:24.379718Z 38 Query FLUSH TABLES WITH READ LOCK 2018-11-28T07:40:24.380340Z 38 Query START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ 2018-11-28T07:40:24.380460Z 38 Query /*!40101 SET NAMES binary*/ 2018-11-28T07:40:24.380529Z 38 Query SHOW MASTER STATUS 2018-11-28T07:40:24.380647Z 38 Query SHOW SLAVE STATUS 2018-11-28T07:40:24.381204Z 39 Connect root@localhost on using Socket 2018-11-28T07:40:24.381289Z 39 Query SET SESSION wait_timeout = 2147483 2018-11-28T07:40:24.381376Z 39 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ 2018-11-28T07:40:24.381417Z 39 Query START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ 2018-11-28T07:40:24.381484Z 39 Query /*!40103 SET TIME_ZONE=‘+00:00‘ */ 2018-11-28T07:40:24.381568Z 39 Query /*!40101 SET NAMES binary*/ 2018-11-28T07:40:24.381956Z 40 Connect root@localhost on using Socket 2018-11-28T07:40:24.382055Z 40 Query SET SESSION wait_timeout = 2147483 2018-11-28T07:40:24.382122Z 40 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ 2018-11-28T07:40:24.382161Z 40 Query START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ 2018-11-28T07:40:24.382213Z 40 Query /*!40103 SET TIME_ZONE=‘+00:00‘ */ 2018-11-28T07:40:24.382263Z 40 Query /*!40101 SET NAMES binary*/ 2018-11-28T07:40:24.382864Z 41 Connect root@localhost on using Socket 2018-11-28T07:40:24.382948Z 41 Query SET SESSION wait_timeout = 2147483 2018-11-28T07:40:24.383001Z 41 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ 2018-11-28T07:40:24.383049Z 41 Query START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ 2018-11-28T07:40:24.383102Z 41 Query /*!40103 SET TIME_ZONE=‘+00:00‘ */ 2018-11-28T07:40:24.383163Z 41 Query /*!40101 SET NAMES binary*/ 2018-11-28T07:40:24.383607Z 42 Connect root@localhost on using Socket 2018-11-28T07:40:24.383682Z 42 Query SET SESSION wait_timeout = 2147483 2018-11-28T07:40:24.383750Z 42 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ 2018-11-28T07:40:24.383810Z 42 Query START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ 2018-11-28T07:40:24.383871Z 42 Query /*!40103 SET TIME_ZONE=‘+00:00‘ */ 2018-11-28T07:40:24.383932Z 42 Query /*!40101 SET NAMES binary*/ 2018-11-28T07:40:24.384357Z 43 Connect root@localhost on using Socket 2018-11-28T07:40:24.384431Z 43 Query SET SESSION wait_timeout = 2147483 2018-11-28T07:40:24.384502Z 43 Query SET SESSION TRANSACTION ISOLATION LEVEL REPEATABLE READ 2018-11-28T07:40:24.384563Z 43 Query START TRANSACTION /*!40108 WITH CONSISTENT SNAPSHOT */ 2018-11-28T07:40:24.384625Z 43 Query /*!40103 SET TIME_ZONE=‘+00:00‘ */ 2018-11-28T07:40:24.384691Z 43 Query /*!40101 SET NAMES binary*/ 2018-11-28T07:40:24.384823Z 38 Init DB employees 2018-11-28T07:40:24.384887Z 38 Query SHOW TABLE STATUS 2018-11-28T07:40:24.387205Z 38 Query SHOW CREATE DATABASE `employees` 2018-11-28T07:40:24.387556Z 38 Query UNLOCK TABLES /* FTWRL */ 2018-11-28T07:40:24.387601Z 38 Quit 2018-11-28T07:40:24.387668Z 41 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘departments‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.388306Z 41 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`departments` 2018-11-28T07:40:24.388730Z 40 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘dept_manager‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.389322Z 39 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘dept_emp‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.389691Z 40 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`dept_manager` 2018-11-28T07:40:24.389902Z 41 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘test1‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.390335Z 39 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`dept_emp` 2018-11-28T07:40:24.390442Z 43 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘employees‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.392348Z 41 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`test1` 2018-11-28T07:40:24.392785Z 41 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘test3‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.393125Z 41 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`test3` 2018-11-28T07:40:24.392740Z 43 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`employees` 2018-11-28T07:40:24.393450Z 41 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘titles‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.393871Z 42 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘salaries‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.393926Z 40 Query select COLUMN_NAME from information_schema.COLUMNS where TABLE_SCHEMA=‘employees‘ and TABLE_NAME=‘test2‘ and extra like ‘%GENERATED%‘ 2018-11-28T07:40:24.394142Z 41 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`titles` 2018-11-28T07:40:24.394276Z 42 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`salaries` 2018-11-28T07:40:24.395416Z 40 Query SELECT /*!40001 SQL_NO_CACHE */ * FROM `employees`.`test2` 2018-11-28T07:40:24.395663Z 40 Query SHOW CREATE TABLE `employees`.`departments` 2018-11-28T07:40:24.395918Z 40 Query SHOW CREATE TABLE `employees`.`dept_emp` 2018-11-28T07:40:24.396169Z 40 Query SHOW CREATE TABLE `employees`.`dept_manager` 2018-11-28T07:40:24.396391Z 40 Query SHOW CREATE TABLE `employees`.`employees` 2018-11-28T07:40:24.396621Z 40 Query SHOW CREATE TABLE `employees`.`salaries` 2018-11-28T07:40:24.396874Z 40 Query SHOW CREATE TABLE `employees`.`test1` 2018-11-28T07:40:24.397103Z 40 Query SHOW CREATE TABLE `employees`.`test2` 2018-11-28T07:40:24.397314Z 40 Query SHOW CREATE TABLE `employees`.`test3` 2018-11-28T07:40:24.397518Z 40 Query SHOW CREATE TABLE `employees`.`titles` 2018-11-28T07:40:24.397700Z 40 Init DB employees 2018-11-28T07:40:24.400045Z 40 Query SHOW FIELDS FROM `employees`.`current_dept_emp` 2018-11-28T07:40:24.400717Z 40 Query SHOW CREATE VIEW `employees`.`current_dept_emp` 2018-11-28T07:40:24.404682Z 40 Init DB employees 2018-11-28T07:40:24.405962Z 40 Query SHOW FIELDS FROM `employees`.`dept_emp_latest_date` 2018-11-28T07:40:24.406279Z 40 Query SHOW CREATE VIEW `employees`.`dept_emp_latest_date` 2018-11-28T07:40:24.406574Z 40 Quit 2018-11-28T07:40:25.541960Z 39 Quit 2018-11-28T07:40:26.073962Z 41 Quit 2018-11-28T07:40:26.162078Z 43 Quit 2018-11-28T07:40:34.942780Z 42 Quit
可以看到备份使用了5个线程!查看备份之后的备份文件如下:
[root@test3 ~]# cd backup/ [root@test3 backup]# ls employees.current_dept_emp-schema.sql.gz employees.dept_emp-schema.sql.gz employees.salaries-schema.sql.gz employees.titles-schema.sql.gz employees.current_dept_emp-schema-view.sql.gz employees.dept_emp.sql.gz employees.salaries.sql.gz employees.titles.sql.gz employees.departments-schema.sql.gz employees.dept_manager-schema.sql.gz employees-schema-create.sql.gz metadata employees.departments.sql.gz employees.dept_manager.sql.gz employees.test1-schema.sql.gz employees.dept_emp_latest_date-schema.sql.gz employees.employees-schema.sql.gz employees.test2-schema.sql.gz employees.dept_emp_latest_date-schema-view.sql.gz employees.employees.sql.gz employees.test3-schema.sql.gz
[root@test3 backup]# cat metadata #查看元信息
Started dump at: 2018-11-28 15:50:18 #备份开始时间
SHOW MASTER STATUS: #备份时候,日志的位置
Log: test3-bin.000001
Pos: 21126
GTID: #因为没有开启gtid,因此gtid为空
Finished dump at: 2018-11-28 15:50:29 #备份结束时间
元数据信息:元数据记录备份开始和结束时间,以及master binlog position点(默认记录),如果在slave上备份默认会记录master binlog position及
slave binlog position点,并且不会关闭SQL线程,这个很友好,比mysqldump及mysqlpump都强。
mydumper把数据和表结构分开备份,并且把二进制日志备份出来单独放到一个文件中。
从上面的备份文件可以看到,每个表一个文件,表数据存在单独的文件中!
注意文件的命名规则:DB.TABLE.sql.gz 或者 DB.TABLE-schema.sql.gz
恢复的时候,也是多线程进行恢复的!
需要先创建恢复的数据库
标签:不一致 初始化 mysql 5.7 解压 表结构 灵活 轻量级 数据一致性 索引
原文地址:https://www.cnblogs.com/wxzhe/p/10032428.html
