标签:运算 os.walk init 统一 ima ogre ted star import
可以被for 循环的
list
dic
str
set
tuple
f = open()
range()
enumerate
print(die([])) 告诉我列表所拥有的所有方法
双下方法
print([1].__add__([2]))
print([1]+[2])
print(‘__iter__‘in dir (int))
print(‘__iter__‘ in dir(ennumerare([]))
只要能被for 循环的数据类型就一定拥有__iter__ 方法
什么叫迭代器?
一个列表执行了__iter__()之后的返回值就是一个迭代器
只要含有__iter__方法的都是可迭代的 ---可迭代协议
迭代器协议---- 内部含有__next__和__iter__方法的就是迭代器
cllections
Iterable
isinstance
迭代器协议和可迭代协议
可以被for循环的都是可迭代的
可迭代的内部都要__iter___方法
只要是迭代器 一定可迭代
可迭代的.__iter__()方法 就是可以得到一个迭代器
迭代器中的__next__()方法可以一个一个的获取值
for循环其实就是在使用迭代器
第一种情况已经明确的告诉你iterator
第二种可迭代对象
第三种直接给你内存函数
只有 是可迭代对象的时候 才能用for
当我们遇到一个新的变量,不确定能不能for循环的时候,就判断它是否可迭代
迭代器的好处:
从容器类型中一个一个的取值,会把所有的值都取到。
节省内存空间
------------------------------------------------------------------------
---------------------------------
生成器 —— 生成器的本质还是迭代器,只是自己写的函数
def generator():
print(1)
return ‘a‘
ret = generator()
print(ret)
只要含有yield关键字的函数都是生成器函数,yield只能写在函数里,yield不能和return共用
def generator():
print()
yield ‘a‘
生成器函数:执行之后会得到一个生成器作为返回值
ret = generator()
print(ret)
print(ret.__next__)

def generator():
print(1)
yield‘a‘
print(2)
yield‘b‘ 这里上面是一个生成器函数
g = generator() 这是一个生成器
ret = g.__next__()
print(ret)
ret = g.__next__()
print(ret)
for循环生成器
def generator():
print(1)
yield‘a‘
print(2)
yield‘b‘
yield‘c‘
g = gengerator()
for i in g:
print(i)
def wahaha():
for i in range(2000000):
yield ‘哇哈哈%s‘ %i
g = wahaha()
count = 0
for i in g:
count +=1
print(i)
if count > 50:
break
print(‘******‘, g.__next__())

各种取值都尝试一下。
day13 3/3
监听文件的输入
f = open(‘file‘, encoding= ‘utf-8‘) # 不能用for循环,不能用read readline等一次性往复读,一次性往复读的特点在后面没有输入
while True:
f.readline()
if line:
print(line)
def tail(filename):
f = open(filename,encoding=‘utf-8‘)
while True:
line = f.readline()
if line.strip():
yield line.strip()
g = tail(‘file‘)
for i in g:
print(i)
def tail(filename):
f =open(‘file‘,encoding=‘utf-8‘)
while True:
line = f.readline()
if line:
print(‘***‘,line.strip())
tail(‘file‘)
监听过滤def tail(filename f =open(‘file‘,encoding=‘utf-8‘ while True: line = f.readline() if line.strip():
yield line.strip() #不能用return 用return函数就停了
g = tail(‘file‘) #加个生成器
for i in g:
if ‘python‘ in i:
print(‘***‘, i)
-------------复习---------------------
迭代器和生成器
迭代器
双下方法 很少直接调用的方法,一般情况下,是通过其他语法触发的
可迭代的-- 可迭代协议 含有__iter__的方法(‘__iter__‘ in dir(数据))
可迭代的一定可以被for循环
迭代器协议:含有__iter__和__next__的方法
迭代器一定可迭代,可迭代的不一定是迭代器,可迭代的通过调用iter()方法就能的得到一个迭代器
迭代器的特点:
很方便使用,且只能取所有的数据取一次。一个迭代器只能从头到尾使用一次。
节省内存空间,只关心现在取的这个和下一个数据。
生成器
生成器的本质就是迭代器
生成器的表现形式
生成器函数
生成器表达式
生成器函数:
含有yield关键字的函数就是生成器函数
特点:
调用函数的之后函数不执行,返回一个生成器
调用next方法的时候会到一个值
直到取完最后一个,在执行next会报错
有一个文件,从文件里分段读取内容
readline 一行一行的读
read(10) 每次读10个
每次内容读出来之后,在前面加一个‘***‘,再返回给调用者。 (练习)
生成器的数据可以被别人反复使用
def generator():
for i in range(200000):
yield ‘哇哈哈%s‘ %i
g = generator()
ret = g.__next__()
print(ret)
num = 0
for i in g:
num += 1
if num > 50:
break
print(i)
从生成器中取值的几个方法
next
for
数据类型的强制转换:不够好,因为占内存
14.2
生成器函数进阶
def generator():
print(123)
yield 1
print(456)
yield 2
print(789) 有几个yield 就出几个值
g = generator()
ret = g.__next__()
print(‘***‘,ret)
ret = g.__next__()
print(‘***‘,ret)
ret = g.send(None) #send的效果和next一样
def generator():
print(123)
content = yield 1
print(‘======‘,content)
print(456)
yield 2
g = generator()
ret = g.__next__()
print(‘***‘,ret)
ret = g.send(‘hello‘)
print(‘*****‘,ret)
send 或许下一个值的使用效果和next基本一致
只是在获取下一个值得时候,给上一个yield值得位置传递一个数据
send 的注意事项
第一次使用生成器的时候是用的next获取下一个值
最后一个yield不能接收外部的值
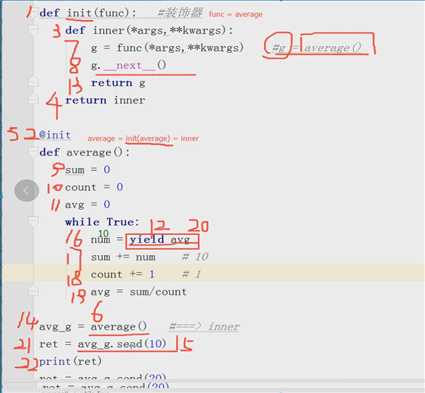
获取移动平均值
def average():
sum = 0
count = 0
avg =0
while True:
num = yield
sum += num
count += 1
avg = sum/count
yield avg
avg_g = average()
avg_g __next__()
avg1 = avg_g.send(10)
avg = avg_g.send(20)
print(avg1)
生成器起到什么作用。就是用到生成器之后运行了一步.__next__激活
其他就没做了。
为了使用生成器之后不断的send数据,就能得到结果
import os
def init(func):
def wrapper(*args,**kwargs):
g=func(*args,**kwargs)
next(g)
return g
return wrapper #五个生成器共用一个装饰器
@init
def list_files(target):
while 1:
dir_to_search=yield
for top_dir,dir,files in os.walk(dir_to_search):
for file in files:
target.send(os.path.join(top_dir,file))
@init
def opener(target):
while 1:
file=yield
fh=open(file)
target.senf((file,fn))
@init
def cat(target):
while 1:
file,fn=yield
for line in fn:
target.send((file,line))
@init
def grep(pattern,target):
while 1:
file, fn=yield
for line in fn:
target.send((file,line))
@init
def grep(pattern,target):
while 1:
file, line=yield
if pattern in line:
target.send(file)
@init
def printer():
while 1:
file=yield
if file:
print(file)
g=list_files(opener(cat(grep(‘python‘,printer()))))
g.send(‘/test1‘)
def generator():
a = ‘abcde‘
b = ‘12345‘
for i in a:
yield i
for i in b:
yield i
g= generator() #g是生成器
for i in g:
print(i)
def generator():
a = ‘abcde‘
b = ‘12345‘
yield from a
yield from b
g = generator()
for i in g:
print(i)
send
send 的作用范围和next一模一样
第一次不能send
函数中的最后一个yield不能接受新的值
计算移动平均值得例子
预计生成器的装饰器的例子
yield from
------------------
列表推导式和生成器表达式
egg_list = [‘鸡蛋%s‘ %i for in range(10)] 列表推导式
print(egg_list)
egg_list = []
for i in range(10):
egg_list.append(‘鸡蛋%s‘%i)
print(egg_list)
print([i*i for i in range(10)])
生成器表达式
(i for i in range(10)) 除了括号不一样,返回值不一样一样和列表表达式比其他都一样
g = (i for i in range(10))
print(g)
for i in g:
print(i)
生成器表达式不占内存
老母鸡 =(‘鸡蛋%s‘%i for i in range(10)) 生成器表达式
print(老母鸡)
for 蛋 in 老母鸡
print(蛋)
2.14.5
各种推导式
列表推导式
[每一个元素或者和元素相关的操作 for 元素 in 可迭代数据类型] # 遍历之后的挨个处理
[满足条件的元素相关操作 for 元素 in 可迭代数据类型 if 元素相关的条件] #筛选功能
集合推导式
字典推导式
30以内所有能被3整除的数
ret = [i for i in range(30) if i%3==0] 最前面的i就是结果 完整的列表推导式
print(ret)
30以内能被3整除的平方
ret=[i*i for i in range(30) if i%3==0 ]
print(ret)
例三:找到嵌套列表中名字含有两个‘e’的所有名字
names = [[‘Tom‘, ‘Billy‘, ‘Jefferson‘, ‘Andrew‘, ‘Wesley‘, ‘Steven‘, ‘Joe‘],
[‘Alice‘, ‘Jill‘, ‘Ana‘, ‘Wendy‘, ‘Jennifer‘, ‘Sherry‘, ‘Eva‘]]
ret = [ name for lst in names for name in lst if name.count(‘e‘) >=2] #for i in names 拿到i相当于列表 第二个for相当于拿到所有name
print(ret) 先for 外面 的大列表再for 里面的小列表
写在列表推导式里,打断点都不好使 简洁易读性
ret = [i for i in range(30) if i%3==0]
g = [i for i in range(30) if i%3==0) 从列表推导式转换到生成器 生成器需要for循环和next取值
字典推导式
例题一
#将一个字典的key 和value对调
mcase = {‘a‘: 10, ‘b‘:34} #对调必须是不可变数据类型且可哈希的
mcase_frequency = {mcase[k]: k for k in mcase}
print(mcase_frequency)
例题二
#合并大小写对应的value值,将k统一成小写
mcase ={‘a‘:10,‘b‘:34,‘A‘:7,‘Z‘:3}
mcase_frequency = {k.lower():mcase.get(k.lower(),0) + mcase.get(k.upper(),0) for k in mcase.keys()} 从后往前看从for开始看。for前面放一个键值对 字典.get 找一个什么
print(mcase_frequency) get找不到是不会报错的,给None
mcase.get(k.lower(),0) 拿不到小写字母就返回0
{k.lower():mcase.get(k.lower(),0)+ mcase.get(k.upper(),0) 小写10+大写的7都赋值给小a
集合推导式
集合最重要的特性就是去重
计算列表中每个值得平方,自带去重的功能
squared = {x**2 for x in [1,-1,2]}
print(squared)
唯独没有元组推导式,因为不能小括号,用了小括号就变成生成器了。
各种推导式:生成器 列表 字典 集合
遍历操作
筛选操作
推导式让你的代码更简洁
---------------
-----------
----------
本章小结
可迭代对象:
拥有__iter__方法
特点:惰性运算 打一个执行一个运算。生成器可以看得见,迭代器大部分看不见,你不找它要它 不干活。同一个迭代器从头到尾只能取一次值。
例如 range(),str,list.tuple,dict,set
迭代器Iterator:
拥有__iter__方法和__next__方法
例如:iter(range()),iter(str),iter(list),iter(tuple),iter(dict),reversed(list_O),map(func,list_o),filter(func,list_O),file_O
生成器Generator:
本质:迭代器,所有拥有__iter__方法和__next__方法
特点:惰性运算,开发者自定义
使用生成器的优点:
1.延迟计算,一次返回一个结果。也就是说,它不会一次生成所有的结果,这对于大数据处理,将会非常有用。
2.提高代码的可读性
迭代器
可迭代协议-- 含有iter 方法的都是可迭代的
迭代器协议 -- 含有next 和lter的都是迭代器
节省空间
方便逐个取值,一个迭代器只能取一个
生成器 所有 的生成器都是迭代器,迭代器的特性都满足
生成器函数
含有yield关键字的函数都是生成器函数
生成器函数的特点
调用之后函数内的代码不执行,返回生成器
每从生成器中取一个值就会执行一段代码,遇见yield就停止。
for for循环首选,满足不了再往下寻找其他方案,for 循环如果没有break会一直取值指导取完
next 每次只去一个
send 不能用在第一个,取下一个值得时候,给上一个位置传一个新的值
数据类型强制转换 会一次性把所有数据都取到内存里
生成器表达式
(条件成立想放在生成器中的值 for i in 可迭代的if条件)
没有函数之前都是面向过程编程,好处就是比较容易思考。
文件句柄:是翻译来的,handler。就是拿着这个就可以操作与其相关的东西。文件操作符,文件句柄
作业#处理文件,用户指定要检查的文件和内容,将文件中包含要查找内容的每一样都输出到屏幕
def check_file():
with open(‘1.复习‘,encoding=‘utf-8‘) as f: #读的方式打开,r不用写了。f是文件句柄
for i in f:
if ‘迭代器‘ in i:
yield i #这里写的是一个生成器函数,
g=check_file() #因为生成器函数 需要赋值调用不然没有效果
for i in g:
print(i.strip())
因为上面的是自己写的,如果需要给他人调用。这样还是不行的。
#处理文件,用户指定要检查的文件和内容,将文件中包含要查找内容的每一样都输出到屏幕
def check_file(filename,aim): #这个地方替换成参数就行了分别替换1.复习和迭代器
with open(filename,encoding=‘utf-8‘) as f:
for i in f:
if aim in i:
yield i
g=check_file(‘1.复习‘,‘生成器‘) # 我要查找的文件是1.复习,我要找的内容是迭代器
for i in g:
print(i.strip())
作业 写生成器,从文件中读取内容,在每一次读取的内容之前加上‘***‘之后返回给用户
#处理文件,用户指定要检查的文件和内容,将文件中包含要查找内容的每一样都输出到屏幕
def check_file(filename): #这个地方替换成参数就行了分别替换1.复习和迭代器
with open(filename,encoding=‘utf-8‘) as f:
for i in f:
yield ‘***‘+ i
for i in check_file(‘1.复习‘):
print(i.strip())
以上就是生成器和文件相结合的讲解
面试题讲解
def demo(): #定义了一个生成器函数
for i in range(4):
yield i
g= demo() g是生成器
g1 =(i for i in g) 这是表达式
g2 = (i for i in g1)
print(list(g1)) 这里是数据类型强转
print(list(g2))
------
g1=(i for i in g) 这个生成器表达式相当于生成器函数
def func(): 这里调用func相当于g1 ,后面的for循环没有执行
for i in g:
yield i
直到print(list(g1)) 才算执行了for循环
这就是惰性运算,print(list(g1))的时候找g1要 g1 = (i for i in g) 这时候g还没执行呢。找g要的时候
才执行 for i in range(4):
当执行
print(list(g2))的时候找g2
g2 = (i for i in g1) g2需要从g1里面取值
但是g1里所有的值,已经取出来赋值给了list
所以g1已经空了。所以g2取不到值
只要把# g1 g2就能取到值了
def demo():
for i in range(4):
yield i
g= demo()
g1 =(i for i in g)
g2 = (i for i in g1)
print(list(g))
print(list(g1))
print(list(g2))
如果是这样,g1 ,g2都是空值
所以只能取一次,取完了就空了。
-------------
def add(n,i): #这只是带返回值的普通函数
return n+i
def test(): 这是生成器函数
for i in range(4):
yield i
g=test() 调用生成器函数 调用g的时候 上面的for 循环还没执行呢
for n in [1,10]: 这是循环的列表
g=(add(n,i) for i in g) #for i in g 前面 调用了一个函数。这是可以的。就是从g里取出的每个i然后都会执行 add(n,i)
print(list(g))
---
n = 1 的时候执行了一句 g=(add(n,i) for i in g)
n = 10 的时候执行一句 g=(add(n,i) for i in g) #从n =1 到n =10 都没执行,内存留着的是n = 10的数据
从上到下 生成器函数都没有调用,从来也没有在生成器里去过值
没有取值,因为我用的是一个生成器表达式
生成器表达式和生成器函数一样懒,只要你不找它取,它就不干活
从头到尾都代码都没有执行过,直到print(list(g)) 才开始找g
替换关系转换后是这样的: g=(add(n,i) for i in (add(n,i) for i in tests())) test 就是0,1,2,3 add(n,i)中的n是10,因为n已经循环从1循环到10了,10之前都消失在内存中了
g =(add(n,i)for i in (10,11,12,13))
def add(n,i):
return n+i
def text():
for i in range(4):
yield i
g = test()
for n in [1,10.5]:
g = (add(n,i) for i in g) #只要在生成器相关的题 就把这个合起来,不看这个了
print(list(g))
n = 1
g = (add(n,i) for i in test()) 这里的g 是test
n = 10
g = (add(n,i) for i in(add(n,i) for i in test())) 这里的g是上面那个g
n = 5
g = (add(n,i) for i in (add(n,i) for i in(add(n,i) for i in test()))) =
g = (add(n,i) for i in (add(n,i) for i in(add(n,i) for i in (0,1,2,3)))) 然后此刻n=5,前面的都消失在内存了
执行的都是生成器表达式
生成器表达式只要我不调用它,它就不干活
等于什么都没干,只是赋值而已
list(g) 才开始干过 -------------------------------------
内置函数
作用域相关的 2个print(locals()) #返回本地作用域中的所有名字
print(globals()) #返回全局作用域中的所有名字
global 变量 global 是关键字
nonlocal 变量
迭代器/生成器相关 3个
range next iter
迭代器.__next__() 双下划线的函数不止一种调用方式
next(迭代器) 比较常用 比如 [].__len__() len([])
迭代器 = iter(可迭代的) 相当于__.iter__() 不常用的原因是比较麻烦
内部含有双下方法才能用,不含有不能用
range(1,11) range(1,11,2)
range是一个可迭代的,但是不是一个迭代器
其他 内置函数
dir 查看一个变量拥有的方法
print(dir{[]})
只能查变量,检测是不是一个函数
callable(func)
help 帮助 查看方法名和一些用法 返回一些关键信息
help(str)
import 模块相关
__import__() 需要赋个值
import time
t = __import__(‘time‘) 字符串 调用import就是调用__import__的内置函数
print(t.time)
某个方法属于某个数据类型的变量,就用 . 调用
如果某个方法不依赖于任何数据类型,就直接调用 ———— 内置函数 和 自定义函数
open 文件操作
f = open(‘file‘)
print(f.writable()) 能不能写 判断一下
print(f.readable()) 能不能读 判断
l = [1,2,3,4] # l 列表句柄
l.appand()
内存相关的
id 代表一个变量的内存地址
hash
print(hash(12345))
print(hash(‘jsdhjfjkaahfwui‘))
print(hash(‘jsdhjfjkaahfwui‘))
print(hash(‘jsdhjfjkdahfwui‘))
print(hash((‘1‘,‘aaa‘))) 元组都可hash
print(hash([])) 列表 集合 字典 不可hash
对于相同可hash的数据的hash值在一次程序的执行过程中总是不变的
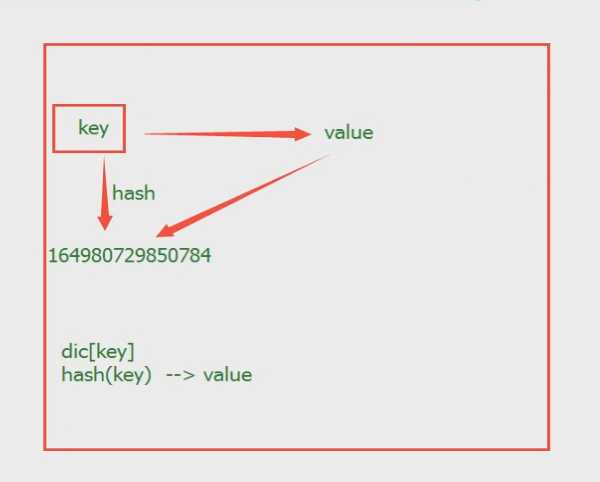
字典的寻址方式
字典的查找速度特别快
key必须可hash key必须不可重复
输入输出
input()
其实就是被 input 这个函数获取到了,并且作为返回值 返回,所以要在前面设立一个变量接收
ret = input(‘提示:‘)
print(ret)
print()
打印到屏幕就是一个文件的概念
print每次打印都会自动换行
print(‘受到好卡‘,end=‘‘) 指定输出的结束符
print(1,2,3,4,5,sep=‘|‘) 指定输出多个值之间的分隔符
f = open(‘file‘,‘w‘)
print(‘aaaa‘,file=f) 打印到文件里去
f.close()
2.15.4
打印进度条
import time
for i inrange(0,101,2):
time.sleep(0.1)
char_num = i//2 #打印多少个‘*‘
per_str = ‘\r%s%% : %s\n‘ % (i, ‘*‘ * char_num) if == 100 else ‘\r%s%% : %s‘%(i,‘*‘*char_num) #三元运算
print(per_str,end=‘‘, flush= True)
per_str = ‘\r%s%% : %s\n‘ % (i, ‘*‘ * char_num) if == 100 else ‘\r%s%% : %s‘%(i,‘*‘*char_num)
/r 表示 一直在句首 打印
%s%% 后面那个%号 表示转义
%s 表示百分之多少
%s\n %s 表示多少个*号 多少个*号是根据后面括号算出来的。
progress bar 专业打印进度条 封装成一个函数
flush: 立即把内容输出到流文件,不作缓存。
字符串类型代码的执行
eval exec compile
exec(‘print(123)‘)
eval(‘print(123)‘)
print(eval(‘1+2+3+4‘))
print(exec(‘1+2+3+4‘)) None 没有返回值
exec和eval 都可以执行 字符串类型的代码
eval有返回值 有结果的简单计算
exec 没有 简单的流程控制
eval只能用在你明确知道你要执行的代码是什么。大部分是写死的
code = ‘‘‘for i in range(10):
print(i*‘*‘)
‘‘‘
exec(code)
上面这个就是没有返回值的, 带流程的
compile 将字符串类型的代码编译。 代码对象能狗通过exec 语句来执行或者eval() 进行求值。
大段代码一次编译多次执行就会方便很多。compile就是编译用的
code1 = ‘for i in range in range(0,10):print (i)‘
copilel = compile(code1,‘‘,‘exec‘ )
exec (compile1)
single 交互类
code3 = ‘name = input("please in input yuour name:")‘ name #执行前name变量不存在
compile3 = compile(code3,‘‘,‘single‘)
exec(compile3)#执行时显示交互命令, 提示输入
name 执行后name变量有值
和数字相关 14个
数据类型(4)
bool int float complex
float 浮点数 =
实数 有理数和无理数
虚数 单位是j python里
复数 ———— complex
这4个数据类型相关的内置函数只在数据类型强制转换的时候使用
复合的数
进制转换(3)
bin 2进制 oct 八进制 hex 十六进制
print(bin(10))
print(oct(10))
print(hex(10))
数学运算(7)abs divmod round pow sum min max abs 求绝对值
div 接收2个参数 返回值也是2个参数 print(divmod(7,2)) div 除法 mod 取余 一般叫作除余方法 这个方法很有用。
抽屉 digchouti.com
round 小数的精确 精确到几位 会四舍五入
pow(pow(2,3)) = 2**3 只不过用函数运行 求幂运算 print(pow(2,3,1))可以输入三个参数,最后一个变量是取余
sum 求和 sum(iterable,start) 需要可迭代的
sum(1,2,3,4,5,6) 这样要报错,sum([1,2,3,4,5,6],10)这样可行
print(min(1,2,3,-4)key = abs) 依次传入绝对值后,找最小值
print(max(1,2,3,-4, key = abs)) 先绝对值再选最大的值 最后打印是-4
02 16 01
基础数据类型 38
数据类型 : int bool 。。。。。
数据结构 :dict list tuple set str 容器数据类型 特别是dict 和tuple 是python里特有的 str相当于字符的集合
列表和元组(2)
list
tuple
在强制转化数据类型的时候用,一个可变,一个不可变
相关内置函数(2)
reversed 反转
l = [1,2,3,4,5]
l.reverse()
print(l)
l = [1,2,3,4,5]
l2 = reversed(l) 这是保留且反转的操作 返回一个反向的迭代器
print(l2)
slice
切片你是不是只用过中括号是不是?其实函数也可以
l = (1,2,23,213,5612,342,43)
sli = slice(1,5,2)
print(l[sli]) 当你要切多个且规则同上的时候
print(l[1:5:2])
字符串(9)
str format bytes bytearray memoryview ord chr ascii repr
format函数功能将一个数值进行格式化显示
如果参数format_spec 未提供,则和调用str(value)效果相同,转换成字符串格式化。
3.对于不同的类型,参数format_spec可提供的值都不一样
ptint(format(‘test‘,‘<20‘))
bytes
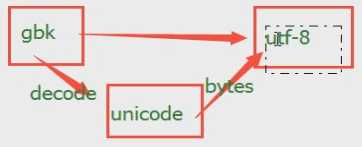
我拿到的是gbk 编码的,我想转成utf——8编码
print(byres(‘你好‘,)encoding=‘GBK‘).decode(‘GBK‘)) unicode转换成 GBK 的bytes
print(bytes(‘你好‘,encoding=‘utf-8‘)) #unicode转换成utf——8 的bytes
#网络编程 只能传二进制
文件重组 照片和视频 也是二进制存储
html网页爬去到也是二进制编码
b_array bytearray(‘你好‘,encoding=‘utf-8‘)
print(b_array)
print(b_array[0])
当一个字符串特别长,你可以改其中某些内存的字节 3个字节
memoryview
切片 -- 字节类型 不占内存
字节 --字符串 占内存
切了不给你,给你看看
ord 字符按照unicode转数字 print(ord(‘a‘))
chr 数字按照unicode转字符 print(chr(97))
ascii 只要是ascii码中的内容,就打印出来,不是就转换成\u
repr 用于%r格式化输出
name = ‘egg‘
print(‘你好%r‘ %name)
%r 打印带‘egg‘
print(repr(‘r‘))
%r调用了repr 的方法 可以让字符串原封不动的输出出来。
数据集合 (3)
字典 dict 集合 set frozenset
字典有value set 没有value
set就是字典的key,没有value 字典 set也要求可hash,就和字典的key要求一样,不重复
只要用大括号括起来的都是无序的
字典的key 不能和集合似的,不能求交集与集
frozenset 不可变的 可以作为字典的key
相关你内置函数
len enmerate all any zip filter map sorted
len
enumerate
all 判断是否有bool 值为False 的值 有一个False 就是False
any 判断是否bool值为True 的值 有一个True 结果就是True
zip 返回一个迭代器
l = [1,2,3]
l2 = [‘a‘,‘b‘,‘c‘]
print(zip(l,l2)) 内存地址
l =[1,2,3]
l2 = [‘a‘,‘b‘,‘c‘]
for i in zip(l,l2): #如果有很多个值的就很有可能是迭代器
print(i)
----------
l = [1,2,3]
l2 = [‘a‘,‘b‘,‘c‘]
l3 = (‘*‘,‘**‘,[1,2])
d = {‘k1‘:1,‘k2‘:2} 只有K 没有value key 是无序的
for i in zip (l,l2,l3,d)
print (i)
filter
def is_odd(x):
return x % 2 == 1 # 奇数就返回一个True 偶数就返回一个Flase 取余2=1就是一个判断句
return 一个bool值
filter(is_odd, [1,4,6,7,9,12,17]) #这个就是过滤后面这个列表。根据返回值得在不在我的筛选范围内
相当于 [i for i in [1,4,5,7,8,12,17] if i %2 ==1]
def is_odd(x):
return x% 2 == 1 #只有这个表达式为True才会留在结果里。
ret = filter(is_odd,[1,4,6,7,9,12,17]) 只能传一个函数名,不能调用(也就是不能加括号),因为不是自己调用,是filter给你调用。整个filter就是过滤方法。只是看不到for循环的过程
后面接收的是一个可迭代,效果就是循环执行前面的函数,如果函数的返回值是Ture那么返回在新的筛选结果里,如果是Flase的话就不要
print(ret)
for i in ret:
print(i)
且filter 可以做 更复杂的事(和for循环比)可以分装在函数里
def is_str(s):
if type(s) == str:
return True 可以简写成 return type(s) == str
ret = filter (is_str,[1,‘hello‘,6,7,‘world‘,12,17])
print(ret)
for i in ret:
print(i)
def is_str(s):
return type(s) == str
ret = filter (is_str,[1,‘hello‘,6,7,‘world‘,12,17])
print(ret)
for i in ret:
print(i)
----------------------
匿名函数
匿名函数都有lambda
def calc(n): 函数名 参数 关键是def
return n**n 返回值
print(calc(10))
calc = lambda n:n**n 匿名函数的关键字是lambda 冒号前面是参数 ,冒号后面的结果,直接是返回值 匿名函数允许换行
没有return这个返回值
printa(calc(10))
def add(x,y):
return X+y
add lambda x,y:x+y
print(add(1,2))
add就是这个匿名函数的函数名
dic={‘k1‘:10,‘k2‘:100,‘k3‘:30}
def func(key):
return dic[key]
print(max(dic,key=func))
如果我用匿名函数
print(max(dic,key=lambda k:dic[k])) k:的自然而然的是表示dic里面每个k,这里表示k1,k2,k3
这是max 和lambda函数合用
是根据lambda的返回值来排序
res = filer(lambda x:x>10,[5,8,11,9,15])
for i in res:
print(i)
转回函数
def func(x):
return x>10
res = filer(func,[5,8,11,9,15])
for i in res:
print(i)
带key 的内置函数一共有5个
min max filter map sorted 都可以带key 都可以和lambda合作
d = lambda p:P*2
d = lambda p:p*3
x = 2
x = d(x) # x =4
x = t(x) # x= 12
x = d(x) # x = 24
print(x)
考一个lambda 表达式 和重复赋值
现在两元组((‘a‘),(‘b‘)),((‘c‘),(‘d‘))使用python中函数生成列表[{‘a‘:‘c‘],{‘b‘:‘d‘}]
匿名函数
zip
ret = zep(((‘a‘),(‘b‘)),((‘c‘).(‘d‘)))
def func(tup):
return {tup[0]:tup[1]}
for i in ret: 去掉循环
print(i)
ret = zip(((‘a‘),(‘b‘)),((‘c‘),(‘d‘)))
def func(tup):
return{tup[0]:tup[1]}
res = map(func,ret)
print(list(res))
ret = zip(((‘a‘),(‘b‘)),((‘c‘),(‘d‘)))
res = map(lambda tup:{tup[0]:tup[1]},ret)
print(list(res))
最终
print(list(map(lambda tup:{tup[0]:tup[1]},zip(((‘a‘),(‘b‘)),((‘c‘),(‘d‘))))))
以下代码的输出是什么? 请给出答案并解释。
def multipliers():
return [lambda x:i*x for i in range(4)]
print(m(2) for m in multipliers()])
请修改multipiers的定义来产生期望的结果。
相当于
def multipliers():
return
print ([m(2) for m in [lambda x:i*x,lambda x:i*x,lambda x:i*x,lambda x:i*x]]}
每一个m都是lambda 表达式
i是多少
为什么i是3
在return的时候,range(4)已经执行完了 lambda还没调用 i 从头到尾没用到过
如果改一下
g = (lambda x:i*x for i in range(4)) 这就是一个生成器表达式。
i可以循环了
考了列表推导式,生成器表达式与匿名函数
--------------------------------------
初识函数 函数的定义,参数调用,返回值
函数进阶 命名空间,作用域 闭包的概念
装饰器函数 闭包的应用
迭代器和生成器 for循环,怎么写迭代器,生成器函数 和生成器表达式
内置函数和匿名函数 68个内置函数 lambda表达式 匿名与内置相结合
递归函数 函数体系,比较难
strip 的一个坑 ,strip(‘ab‘) 先strip a 再strip b 把整个字符串断的ab都会去除,去掉字符串不能用strip
标签:运算 os.walk init 统一 ima ogre ted star import
原文地址:https://www.cnblogs.com/timye607/p/10147286.html