标签:declare 覆盖 mapped 指定位置 com spinlock 应用 isa void
尽管vmalloc函数族可用于从高端内存域向内核映射页帧(这些在内核空间中通常是无法直接看到的), 但这并不是这些函数的实际用途.
重要的是强调以下事实 : 内核提供了其他函数用于将ZONE_HIGHMEM页帧显式映射到内核空间, 这些函数与vmalloc机制无关. 因此, 这就造成了混乱.
而在高端内存的页不能永久地映射到内核地址空间. 因此, 通过alloc_pages()函数以__GFP_HIGHMEM标志获得的内存页就不可能有逻辑地址.
在x86_32体系结构总, 高于896MB的所有物理内存的范围大都是高端内存, 它并不会永久地或自动映射到内核地址空间, 尽管X86处理器能够寻址物理RAM的范围达到4GB(启用PAE可以寻址64GB), 一旦这些页被分配, 就必须映射到内核的逻辑地址空间上. 在x86_32上, 高端地址的页被映射到内核地址空间(即虚拟地址空间的3GB~4GB)
内核地址空间的最后128 MiB用于何种用途呢?
该部分有3个用途。
虚拟内存中连续、但物理内存中不连续的内存区,可以在vmalloc区域分配. 该机制通常用于用户过程, 内核自身会试图尽力避免非连续的物理地址。内核通常会成功,因为大部分大的内存块都在启动时分配给内核,那时内存的碎片尚不严重。但在已经运行了很长时间的系统上, 在内核需要物理内存时, 就可能出现可用空间不连续的情况. 此类情况, 主要出现在动态加载模块时.
持久映射用于将高端内存域中的非持久页映射到内核中
固定映射是与物理地址空间中的固定页关联的虚拟地址空间项,但具体关联的页帧可以自由选择. 它与通过固定公式与物理内存关联的直接映射页相反,虚拟固定映射地址与物理内存位置之间的关联可以自行定义,关联建立后内核总是会注意到的.
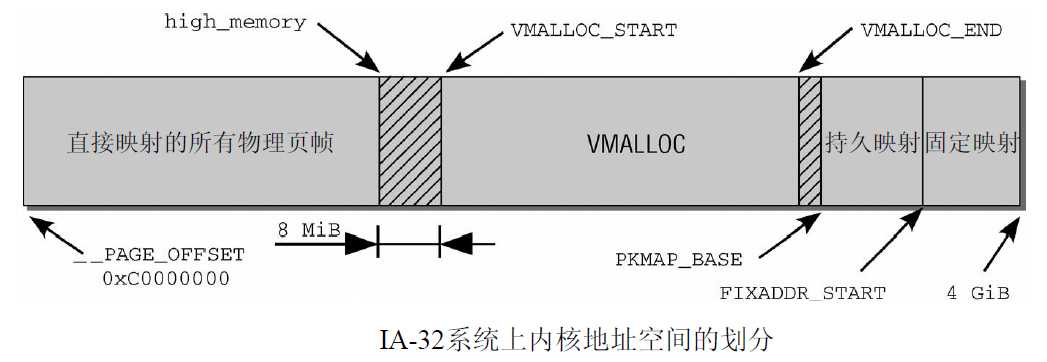
在这里有两个预处理器符号很重要 __VMALLOC_RESERVE设置了vmalloc区域的长度, 而MAXMEM则表示内核可以直接寻址的物理内存的最大可能数量.
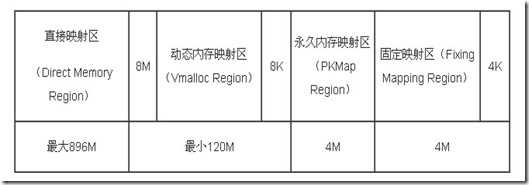
内核中, 将内存划分为各个区域是通过图3-15所示的各个常数控制的。根据内核和系统配置, 这些常数可能有不同的值。直接映射的边界由high_memory指定。
线性空间中从3G开始最大896M的区间, 为直接内存映射区,该区域的线性地址和物理地址存在线性转换关系:线性地址=3G+物理地址。
该区域由内核函数vmalloc来分配, 特点是 : 线性空间连续, 但是对应的物理空间不一定连续. vmalloc分配的线性地址所对应的物理页可能处于低端内存, 也可能处于高端内存.
该区域可访问高端内存. 访问方法是使用alloc_page(_GFP_HIGHMEM)分配高端内存页或者使用kmap函数将分配到的高端内存映射到该区域.
该区域和4G的顶端只有4k的隔离带,其每个地址项都服务于特定的用途,如ACPI_BASE等。
说明
注意用户空间当然可以使用高端内存,而且是正常的使用,内核在分配那些不经常使用的内存时,都用高端内存空间(如果有),所谓不经常使用是相对来说的,比如内核的一些数据结构就属于经常使用的,而用户的一些数据就属于不经常使用的。用户在启动一个应用程序时,是需要内存的,而每个应用程序都有3G的线性地址,给这些地址映射页表时就可以直接使用高端内存。
而且还要纠正一点的是:那128M线性地址不仅仅是用在这些地方的,如果你要加载一个设备,而这个设备需要映射其内存到内核中,它也需要使用这段线性地址空间来完成,否则内核就不能访问设备上的内存空间了.
总之,内核的高端线性地址是为了访问内核固定映射以外的内存资源。进程在使用内存时,触发缺页异常,具体将哪些物理页映射给用户进程是内核考虑的事情. 在用户空间中没有高端内存这个概念.
即内核对于低端内存, 不需要特殊的映射机制, 使用直接映射即可以访问普通内存区域, 而对于高端内存区域, 内核可以采用三种不同的机制将页框映射到高端内存 : 分别叫做永久内核映射、临时内核映射以及非连续内存分配
如果需要将高端页帧长期映射(作为持久映射)到内核地址空间中, 必须使用kmap函数. 需要映射的页用指向page的指针指定,作为该函数的参数。该函数在有必要时创建一个映射(即,如果该页确实是高端页), 并返回数据的地址.
如果没有启用高端支持, 该函数的任务就比较简单. 在这种情况下, 所有页都可以直接访问, 因此只需要返回页的地址, 无需显式创建一个映射.
如果确实存在高端页, 情况会比较复杂. 类似于vmalloc, 内核首先必须建立高端页和所映射到的地址之间的关联. 还必须在虚拟地址空间中分配一个区域以映射页帧, 最后, 内核必须记录该虚拟区域的哪些部分在使用中, 哪些仍然是空闲的.
内核在IA-32平台上在vmalloc区域之后分配了一个区域, 从PKMAP_BASE到FIXADDR_START. 该区域用于持久映射. 不同体系结构使用的方案是类似的.
永久内核映射允许内核建立高端页框到内核地址空间的长期映射。 他们使用着内核页表中一个专门的页表, 其地址存放在变量pkmap_page_table中, 页表中的表项数由LAST_PKMAP宏产生. 因此,内核一次最多访问2MB或4MB的高端内存.
#define PKMAP_BASE (PAGE_OFFSET - PMD_SIZE)页表映射的线性地址从PKMAP_BASE开始. pkmap_count数组包含LAST_PKMAP个计数器,pkmap_page_table页表中的每一项都有一个。
// http://lxr.free-electrons.com/source/mm/highmem.c?v=4.7#L126
static int pkmap_count[LAST_PKMAP];
static __cacheline_aligned_in_smp DEFINE_SPINLOCK(kmap_lock);
pte_t * pkmap_page_table;高端映射区逻辑页面的分配结构用分配表(pkmap_count)来描述,它有1024项,对应于映射区内不同的逻辑页面。当分配项的值等于0时为自由项,等于1时为缓冲项,大于1时为映射项。映射页面的分配基于分配表的扫描,当所有的自由项都用完时,系统将清除所有的缓冲项,如果连缓冲项都用完时,系统将进入等待状态。
// http://lxr.free-electrons.com/source/mm/highmem.c?v=4.7#L126
/*
高端映射区逻辑页面的分配结构用分配表(pkmap_count)来描述,它有1024项,
对应于映射区内不同的逻辑页面。当分配项的值等于零时为自由项,等于1时为
缓冲项,大于1时为映射项。映射页面的分配基于分配表的扫描,当所有的自由
项都用完时,系统将清除所有的缓冲项,如果连缓冲项都用完时,系
统将进入等待状态。
*/
static int pkmap_count[LAST_PKMAP];pkmap_count(在mm/highmem.c?v=4.7, line 126定义)是一容量为LAST_PKMAP的整数数组, 其中每个元素都对应于一个持久映射页。它实际上是被映射页的一个使用计数器,语义不太常见.
内核可以通过get_next_pkmap_nr获取到pkmap_count数组中元素的个数, 该函数定义在mm/highmem.c?v=4.7, line 66
/*
* Get next index for mapping inside PKMAP region for page with given color.
*/
static inline unsigned int get_next_pkmap_nr(unsigned int color)
{
static unsigned int last_pkmap_nr;
last_pkmap_nr = (last_pkmap_nr + 1) & LAST_PKMAP_MASK;
return last_pkmap_nr;
}为了记录高端内存页框与永久内核映射包含的线性地址之间的联系,内核使用了page_address_htable散列表.
该表包含一个page_address_map数据结构,用于为高端内存中的每一个页框进行当前映射。而该数据结构还包含一个指向页描述符的指针和分配给该页框的线性地址。
/*
* Describes one page->virtual association
*/
struct page_address_map
{
struct page *page;
void *virtual;
struct list_head list;
};该结构用于建立page-->virtual的映射(该结构由此得名).
| 字段 | 描述 |
|---|---|
| page | 是一个指向全局mem_map数组中的page实例的指针 |
| virtual | 指定了该页在内核虚拟地址空间中分配的位置 |
为便于组织, 映射保存在散列表中, 结构中的链表元素用于建立溢出链表,以处理散列碰撞. 该散列表通过page_address_htable数组实现, 定义在mm/highmem.c?v=4.7, line 392
static struct page_address_slot *page_slot(const struct page *page)
{
return &page_address_htable[hash_ptr(page, PA_HASH_ORDER)];
}page_address是一个前端函数, 使用上述数据结构确定给定page实例的线性地址, 该函数定义在mm/highmem.c?v=4.7, line 408)
/**
* page_address - get the mapped virtual address of a page
* @page: &struct page to get the virtual address of
*
* Returns the page's virtual address.
*/
void *page_address(const struct page *page)
{
unsigned long flags;
void *ret;
struct page_address_slot *pas;
/*如果页框不在高端内存中*/
if (!PageHighMem(page))
/*线性地址总是存在,通过计算页框下标
然后将其转换成物理地址,最后根据相应的
/物理地址得到线性地址*/
return lowmem_page_address(page);
/*从page_address_htable散列表中得到pas*/
pas = page_slot(page);
ret = NULL;
spin_lock_irqsave(&pas->lock, flags);
if (!list_empty(&pas->lh)) {{/*如果对应的链表不空,
该链表中存放的是page_address_map结构*/
struct page_address_map *pam;
/*对每个链表中的元素*/
list_for_each_entry(pam, &pas->lh, list) {
if (pam->page == page) {
/*返回线性地址*/
ret = pam->virtual;
goto done;
}
}
}
done:
spin_unlock_irqrestore(&pas->lock, flags);
return ret;
}
EXPORT_SYMBOL(page_address);page_address首先检查传递进来的page实例在普通内存还是在高端内存.
page在mem_map数组中的位置计算. 这个工作可以通过lowmem_page_address调用page_to_virt(page)来完成为通过page指针建立映射, 必须使用kmap函数.
不同体系结构的定义可能不同, 但是大多数体系结构的定义都如下所示, 比如arm上该函数定义在arch/arm/mm/highmem.c?v=4.7, line 37, 如下所示
/*高端内存映射,运用数组进行操作分配情况
分配好后需要加入哈希表中;*/
void *kmap(struct page *page)
{
might_sleep();
if (!PageHighMem(page)) /*如果页框不属于高端内存*/
return page_address(page);
return kmap_high(page); /*页框确实属于高端内存*/
}
EXPORT_SYMBOL(kmap);kmap函数只是一个page_address的前端,用于确认指定的页是否确实在高端内存域中. 否则, 结果返回page_address得到的地址. 如果确实在高端内存中, 则内核将工作委托给kmap_high
kmap_high的实现在函数mm/highmem.c?v=4.7, line 275中, 定义如下
/**
* kmap_high - map a highmem page into memory
* @page: &struct page to map
*
* Returns the page's virtual memory address.
*
* We cannot call this from interrupts, as it may block.
*/
void *kmap_high(struct page *page)
{
unsigned long vaddr;
/*
* For highmem pages, we can't trust "virtual" until
* after we have the lock.
*/
lock_kmap(); /*保护页表免受多处理器系统上的并发访问*/
/*检查是否已经被映射*/
vaddr = (unsigned long)page_address(page);
if (!vaddr) )/* 如果没有被映射 */
/*把页框的物理地址插入到pkmap_page_table的
一个项中并在page_address_htable散列表中加入一个
元素*/
vaddr = map_new_virtual(page);
/*分配计数加一,此时流程都正确应该是2了*/
pkmap_count[PKMAP_NR(vaddr)]++;
BUG_ON(pkmap_count[PKMAP_NR(vaddr)] < 2);
unlock_kmap();
return (void*) vaddr; ;/*返回地址*/
}
EXPORT_SYMBOL(kmap_high);上文讨论的page_address函数首先检查该页是否已经映射. 如果它不对应到有效地址, 则必须使用map_new_virtual映射该页.
该函数定义在mm/highmem.c?v=4.7, line 213, 将执行下列主要的步骤.
static inline unsigned long map_new_virtual(struct page *page)
{
unsigned long vaddr;
int count;
unsigned int last_pkmap_nr;
unsigned int color = get_pkmap_color(page);
start:
count = get_pkmap_entries_count(color);
/* Find an empty entry */
for (;;) {
last_pkmap_nr = get_next_pkmap_nr(color); /*加1,防止越界*/
/* 接下来判断什么时候last_pkmap_nr等于0,等于0就表示1023(LAST_PKMAP(1024)-1)个页表项已经被分配了
,这时候就需要调用flush_all_zero_pkmaps()函数,把所有pkmap_count[] 计数为1的页表项在TLB里面的entry给flush掉
,并重置为0,这就表示该页表项又可以用了,可能会有疑惑为什么不在把pkmap_count置为1的时候也
就是解除映射的同时把TLB也flush呢?
个人感觉有可能是为了效率的问题吧,毕竟等到不够的时候再刷新,效率要好点吧。*/
if (no_more_pkmaps(last_pkmap_nr, color)) {
flush_all_zero_pkmaps();
count = get_pkmap_entries_count(color);
}
if (!pkmap_count[last_pkmap_nr])
break; /* Found a usable entry */
if (--count)
continue;
/*
* Sleep for somebody else to unmap their entries
*/
{
DECLARE_WAITQUEUE(wait, current);
wait_queue_head_t *pkmap_map_wait =
get_pkmap_wait_queue_head(color);
__set_current_state(TASK_UNINTERRUPTIBLE);
add_wait_queue(pkmap_map_wait, &wait);
unlock_kmap();
schedule();
remove_wait_queue(pkmap_map_wait, &wait);
lock_kmap();
/* Somebody else might have mapped it while we slept */
if (page_address(page))
return (unsigned long)page_address(page);
/* Re-start */
goto start;
}
}
/*返回这个页表项对应的线性地址vaddr.*/
vaddr = PKMAP_ADDR(last_pkmap_nr);
/*设置页表项*/
set_pte_at(&init_mm, vaddr,
&(pkmap_page_table[last_pkmap_nr]), mk_pte(page, kmap_prot));
/*接下来把pkmap_count[last_pkmap_nr]置为1,1不是表示不可用吗,
既然映射已经建立好了,应该赋值为2呀,其实这个操作
是在他的上层函数kmap_high里面完成的(pkmap_count[PKMAP_NR(vaddr)]++).*/
pkmap_count[last_pkmap_nr] = 1;
/*到此为止,整个映射就完成了,再把page和对应的线性地址
加入到page_address_htable哈希链表里面就可以了*/
set_page_address(page, (void *)vaddr);
return vaddr;
}从最后使用的位置(保存在全局变量last_pkmap_nr中)开始,反向扫描pkmap_count数组, 直至找到一个空闲位置. 如果没有空闲位置,该函数进入睡眠状态,直至内核的另一部分执行解除映射操作腾出空位. 在到达pkmap_count的最大索引值时, 搜索从位置0开始. 在这种情况下, 还调用 flush_all_zero_pkmaps函数刷出CPU高速缓存(读者稍后会看到这一点)。
修改内核的页表,将该页映射在指定位置。但尚未更新TLB.
新位置的使用计数器设置为1。如上所述,这意味着该页已分配但无法使用,因为TLB项未更新.
set_page_address将该页添加到持久内核映射的数据结构。 该函数返回新映射页的虚拟地址. 在不需要高端内存页的体系结构上(或没有设置CONFIG_HIGHMEM),则使用通用版本的kmap返回页的地址,且不修改虚拟内存
用kmap映射的页, 如果不再需要, 必须用kunmap解除映射. 照例, 该函数首先检查相关的页(由page实例标识)是否确实在高端内存中. 倘若如此, 则实际工作委托给mm/highmem.c中的kunmap_high, 该函数的主要任务是将pkmap_count数组中对应位置在计数器减1
该机制永远不能将计数器值降低到小于1. 这意味着相关的页没有释放。因为对使用计数器进行了额外的加1操作, 正如前文的讨论, 这是为确保CPU高速缓存的正确处理.
也在上文提到的flush_all_zero_pkmaps是最终释放映射的关键. 在map_new_virtual从头开始搜索空闲位置时, 总是调用该函数.
它负责以下3个操作。
flush_cache_kmaps在内核映射上执行刷出(在需要显式刷出的大多数体系结构上,将使用flush_cache_all刷出CPU的全部的高速缓存), 因为内核的全局页表已经修改.
pkmap_count数组. 计数器值为1的项设置为0,从页表删除相关的项, 最后删除该映射。最后, 使用flush_tlb_kernel_range函数刷出所有与PKMAP区域相关的TLB项.
同kmap类似, 每个体系结构都应该实现自己的kmap函数, 大多数体系结构的定义都如下所示, 参见arch/arm/mm/highmem.c?v=4.7, line 46
void kunmap(struct page *page)
{
BUG_ON(in_interrupt());
if (!PageHighMem(page))
return;
kunmap_high(page);
}
EXPORT_SYMBOL(kunmap);内核首先检查待释放内存区域是不是在高端内存区域
kunmap_high函数定义在mm/highmem.c?v=4.7, line 328
#ifdef CONFIG_HIGHMEM
/**
* kunmap_high - unmap a highmem page into memory
* @page: &struct page to unmap
*
* If ARCH_NEEDS_KMAP_HIGH_GET is not defined then this may be called
* only from user context.
*/
void kunmap_high(struct page *page)
{
unsigned long vaddr;
unsigned long nr;
unsigned long flags;
int need_wakeup;
unsigned int color = get_pkmap_color(page);
wait_queue_head_t *pkmap_map_wait;
lock_kmap_any(flags);
vaddr = (unsigned long)page_address(page);
BUG_ON(!vaddr);
nr = PKMAP_NR(vaddr); /*永久内存区域开始的第几个页面*/
/*
* A count must never go down to zero
* without a TLB flush!
*/
need_wakeup = 0;
switch (--pkmap_count[nr]) { /*减小这个值,因为在映射的时候对其进行了加2*/
case 0:
BUG();
case 1:
/*
* Avoid an unnecessary wake_up() function call.
* The common case is pkmap_count[] == 1, but
* no waiters.
* The tasks queued in the wait-queue are guarded
* by both the lock in the wait-queue-head and by
* the kmap_lock. As the kmap_lock is held here,
* no need for the wait-queue-head's lock. Simply
* test if the queue is empty.
*/
pkmap_map_wait = get_pkmap_wait_queue_head(color);
need_wakeup = waitqueue_active(pkmap_map_wait);
}
unlock_kmap_any(flags);
/* do wake-up, if needed, race-free outside of the spin lock */
if (need_wakeup)
wake_up(pkmap_map_wait);
}
EXPORT_SYMBOL(kunmap_high);
#endif刚才描述的kmap函数不能用于中断处理程序, 因为它可能进入睡眠状态. 如果pkmap数组中没有空闲位置, 该函数会进入睡眠状态, 直至情形有所改善.
void *kmap_atomic(struct page *page)
{
unsigned int idx;
unsigned long vaddr;
void *kmap;
int type;
preempt_disable();
pagefault_disable();
if (!PageHighMem(page))
return page_address(page);
#ifdef CONFIG_DEBUG_HIGHMEM
/*
* There is no cache coherency issue when non VIVT, so force the
* dedicated kmap usage for better debugging purposes in that case.
*/
if (!cache_is_vivt())
kmap = NULL;
else
#endif
kmap = kmap_high_get(page);
if (kmap)
return kmap;
type = kmap_atomic_idx_push();
idx = FIX_KMAP_BEGIN + type + KM_TYPE_NR * smp_processor_id();
vaddr = __fix_to_virt(idx);
#ifdef CONFIG_DEBUG_HIGHMEM
/*
* With debugging enabled, kunmap_atomic forces that entry to 0.
* Make sure it was indeed properly unmapped.
*/
BUG_ON(!pte_none(get_fixmap_pte(vaddr)));
#endif
/*
* When debugging is off, kunmap_atomic leaves the previous mapping
* in place, so the contained TLB flush ensures the TLB is updated
* with the new mapping.
*/
set_fixmap_pte(idx, mk_pte(page, kmap_prot));
return (void *)vaddr;
}
EXPORT_SYMBOL(kmap_atomic);这个函数不会被阻塞, 因此可以用在中断上下文和起亚不能重新调度的地方. 它也禁止内核抢占, 这是有必要的, 因此映射对每个处理器都是唯一的(调度可能对哪个处理器执行哪个进程做变动).
可以通过函数kunmap_atomic取消映射
/*
* Prevent people trying to call kunmap_atomic() as if it were kunmap()
* kunmap_atomic() should get the return value of kmap_atomic, not the page.
*/
#define kunmap_atomic(addr) do { BUILD_BUG_ON(__same_type((addr), struct page *)); __kunmap_atomic(addr); } while (0)这个函数也不会阻塞. 在很多体系结构中, 除非激活了内核抢占, 否则kunmap_atomic根本无事可做, 因为只有在下一个临时映射到来前上一个临时映射才有效. 因此, 内核完全可以”忘掉”kmap_atomic映射, kunmap_atomic也无需做什么实际的事情. 下一个原子映射将自动覆盖前一个映射.
高端内存映射之kmap持久内核映射--Linux内存管理(二十)
标签:declare 覆盖 mapped 指定位置 com spinlock 应用 isa void
原文地址:https://www.cnblogs.com/linhaostudy/p/10201104.html