标签:简单 over 记录 好的 工具 窗口类型 数据 书籍 sha
目录
@
本博客只记录工作中的一次oracle sql调优记录,因为数据量过多导致的查询缓慢,一方面是因为业务太过繁杂,关联了太多表。面对复杂的业务场景,确实有些情况是需要关联很多表的。当然有些情况是可以将业务实现放在Java代码里,有些情况可以不要关联很多表。
对于SQL调优,不要马上就说加索引什么的,加索引不一定就能解决问题的,加错索引,反而会导致查询变慢,注意加索引的同时也会影响数据库写数据的速度。
对于SQL调优,可以通过Oracle的执行计划来分析。oracle的执行计划确实是对sql进行分析的一种很好的方法。
下面介绍一下oracle的执行计划。
oracle要使用执行计划的sql为:
explain plan for select 1 from 表格不过如果是使用PLSQL的话,那就可以使用PLSQL提供的查询执行计划了,PLSQL安装有问题可以参数我以前写的博客:https://blog.csdn.net/u014427391/article/details/56479085
打开PLSQL
工具 -> 首选项 -> 窗口类型 -> 计划窗口 ,在这里加入执行计划需要的参数
找个SQL,用PLSQL执行一下,这是plsql的简单使用
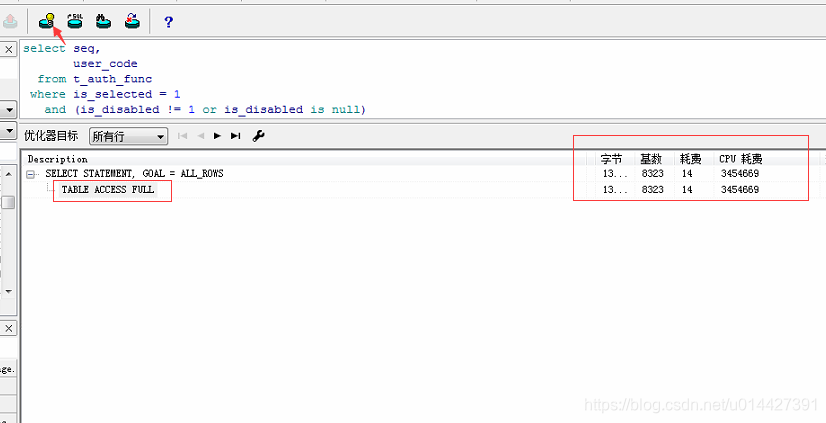
解释一下这些参数的意思:
基数(Rows):Oracle估计的当前步骤的返回结果集行数
字节(Bytes):执行SQL对应步骤返回的字节数
耗费(COST)、CPU耗费:Oracle估计的该步骤的执行耗费和CPU耗费
时间(Time):Oracle估计的执行sql对于步骤需要的时间
表访问的几种方法:
TABLE ACCESS FULL(全表扫描)
TABLE ACCESS BY ROWID(通过ROWID的表存取)
TABLE ACCESS BY INDEX SCAN(索引扫描)
...
oracle执行计划其实就是看一下那些表是按索引扫描的,通过加一些索引实现,TABLE ACCESS BY INDEX SCAN(索引扫描)。
下面给出一篇很详细介绍oracle执行计划的博客
https://www.cnblogs.com/Dreamer-1/p/6076440.html
在加一些索引的过程,有时候会遇到索引失效的情况,这时候可以加强制索引试试
强制索引
/*+ index(表名别名 索引名称)*/ 假如select *from 表格 a,然后加了个索引i,那么就是
/*+ index(a i)*/之前同事有遇到一种加了索引还是不起效的情况,后来听他说是是一种基数反馈机制导致的,解决方法是在sql加上,意思是关了基数反馈机制
基数反馈机制
/*+ opt_param(‘_optimizer_use_feedback‘,‘false‘)*/比如
select /*+ opt_param(‘_optimizer_use_feedback‘,‘false‘)*/ a from 表格 用oracle开窗函数替换group by,oracle的group by有时候是很耗查询的,今天遇到一个sql查询很慢的问题,用oracle开窗函数进行替换group by提高速度。当然这些都是根据实践业务场景来调优的。我遇到的业务场景是适合的。因为关联的表数据量很大。
原来SQL,简单写一下,举个例子,实际的业务场景不是这么简单的sql
select max(to_number(aa.seq))
from t_info aa
where aa.id = ?
group by aa.seq改造sql:
select seq from (select aa.seq,
row_number() over(partition by aa.seq order by aa.date desc nulls last)rn
from t_info aa
) where rn=1 然后推荐一本oracle调优书籍《收获,不止SQL优化》一书
标签:简单 over 记录 好的 工具 窗口类型 数据 书籍 sha
原文地址:https://www.cnblogs.com/mzq123/p/10201044.html