标签:als 速度 towards bubuko function res 位置 简单 bat
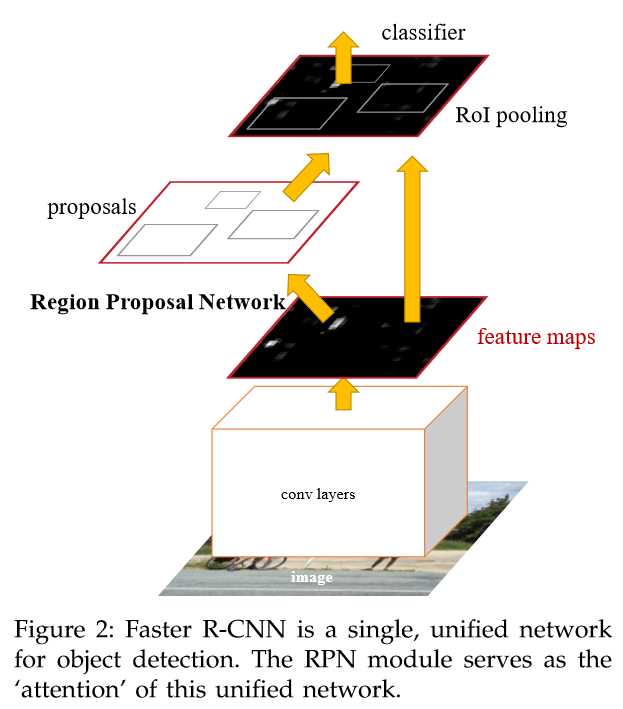
Faster R-CNN是很经典的two-stage的目标检测方法,前面看了Selective Search以为在这里可以用到,但是作者在这篇文章里面没有采用Selective Search方法得到候选框,而是采用了Edge Boxes方法得到的候选框,好吧,再去看看这个方法到底快在哪里。Faster R-CNN分为两个过程,第一个过程是通过RPN网络得到候选框,第二个过程是利用Fast RCNN网络进行分类,普遍two-stage网络的准确度比one-stage的高,但是速度很慢。
faster rcnn 大致流程图如下
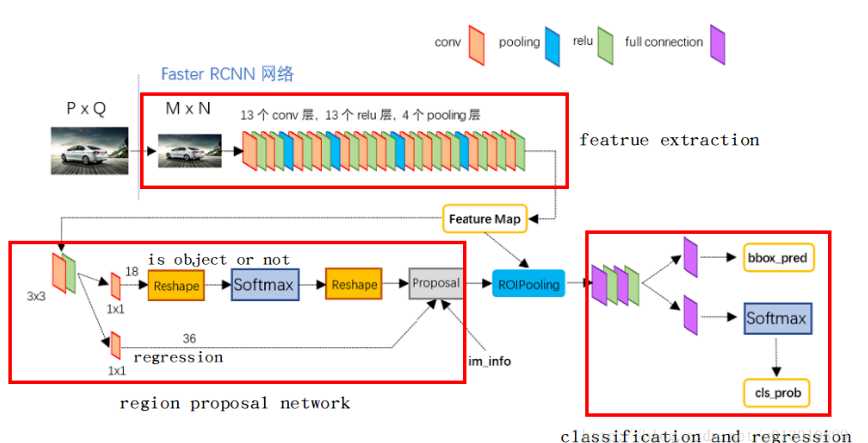
RPN网络是用来获取proposals的网络,将任意size的图片输入到网络中,得到多组proposals,这些proposals包含中心点的位置x、y和宽高w、h来唯一确定一个框,而怎么得到这些proposals呢?
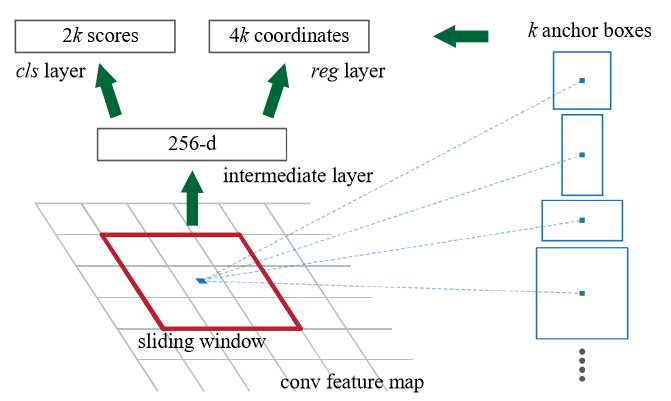
文中是先用一个小网络得到feature map,这个feature map是 13?13?256的,然后采用一个n?n的滑窗去滑这个feature map,得到一个256-d的向量,而文章中是使用的n=3的滑窗去滑的。这个滑动过程其实是用一个3?3?256?256的卷积核去卷积的过程。
在每个滑窗的区域,会同时预测多个region proposals,假定每个sliding window预测k种框,那么regression layer就输出4k个参数,很好理解,就是x、y、w、h;cls层输出2k个scores,即是背景还是不是背景。而文章中的anchor指的就是每个sliding window的中心,文章默认采用了3种scale和3种aspect ratio,也就是9种不同的长宽比放缩比,这样每个anchor对应的就是原图种的1种位置,也就是说一个feature map中的点对应9个anchor。假设feature map是W?H的,那么我们会得到9WH个anchor。
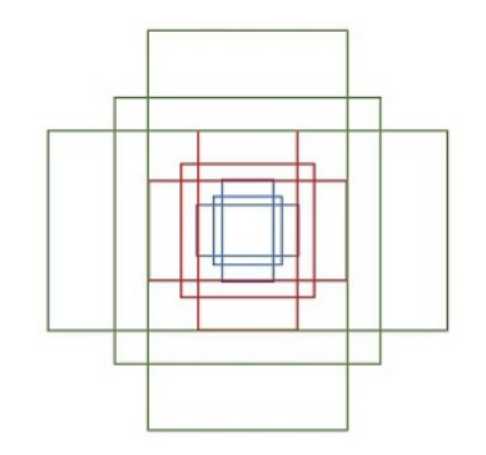
文中方法最终要的一点就是anchors具有平移不变性。也就是说,如果图像中的某一个物体发生了平移,那么我们应该能够通过同样的方法也能够准确的预测到这个proposal,无论它在任何位置。
最终应该生成这九种anchor box
我们可以知道,输出的是两部分,一部分是是不是背景的分类loss,另一部分是预测的bbox的坐标宽高的regression loss,于是很容易去理解作者下图中的loss function。

参数解释在上图中。其中Ncls和Nreg是归一化的,λ是用来调整两个loss之间权重分配的,也很好理解。
作者在文中采用的是Ncls=256,Nreg约等于2400,这样他的λ设置成了10,这是为了使得两者权重大致相等。而下面又解释了公式中t也就是变换是怎么计算的:

参数解释当然也在图中。
之所以需要求这个t,是因为实际预测到的框和ground-truth box之间是有一定差距的,比如下面这张图:
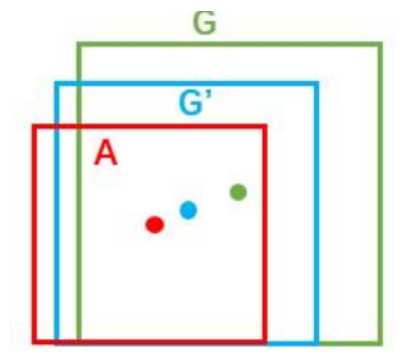
所以我们通过求得一个线性变换使得A框能够尽可能接近G框,变换的结果就是G‘框,这样可以使得结果更接近G。而上面公式的解释呢,我理解的就是分别计算anchor和预测的框之间的变换、anchor和ground truth 框之间的变换,通过这两个变换来计算loss,也就是上面那个公式里的Lreg部分。
我们知道,loss里面关于是不是背景也有个loss,标记规则很简单
然后就是训练RPN了。在训练RPN的时候呢,一个Mini batch是我们在一张图中随机选取的256个proposal组成的,正负样本的比例应该是1比1,正样本不足128,就补负样本,负样本不足就补正样本(一般负样本不会不足)。
一个非常透彻的理解:Faster R-CNN中RPN网络的理解
论文原文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
标签:als 速度 towards bubuko function res 位置 简单 bat
原文地址:https://www.cnblogs.com/aoru45/p/10203146.html