标签:int 4行 技术 package 不同 高速缓存 虚拟机 特性 部分
目录
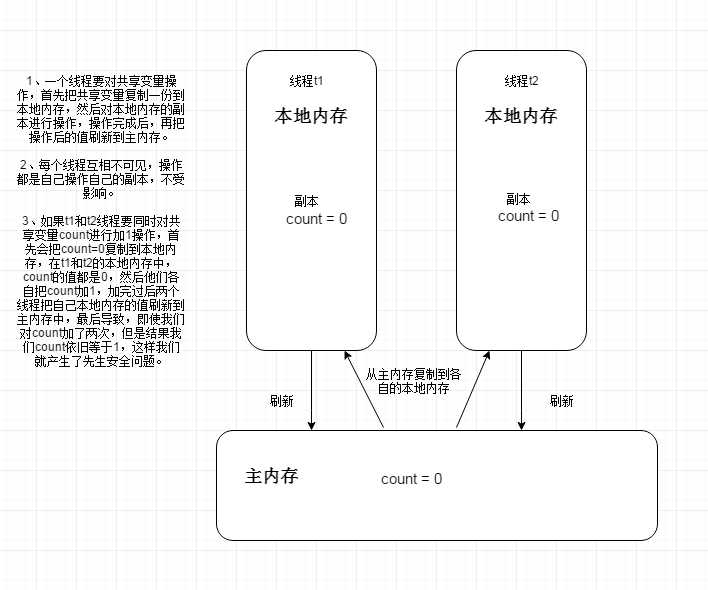
我们都知道,计算机在执行程序时,每条指令都是在CPU中执行的,而执行指令过程中,势必涉及到数据的读取和写入。由于程序运行过程中的临时数据是存放在主存(物理内存)当中的,这时就存在一个问题,由于CPU执行速度很快,而从内存读取数据和向内存写入数据的过程跟CPU执行指令的速度比起来要慢的多,因此如果任何时候对数据的操作都要通过和内存的交互来进行,会大大降低指令执行的速度。因此在CPU里面就有了高速缓存。
高速缓存就是,当程序在运行过程中,会将运算需要的数据从主存复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。举个简单的例子,比如i = i + 1,当线程执行这个语句时,会先从主存当中读取i的值,然后复制一份到高速缓存当中,然后CPU执行指令对i进行加1操作,然后将数据写入高速缓存,最后将高速缓存中i最新的值刷新到主存当中。
这个代码在单线程中运行是没有任何问题的,但是在多线程中运行就会有问题了。在多核CPU中,每条线程可能运行于不同的CPU中,因此每个线程运行时有自己的高速缓存(对单核CPU来说,其实也会出现这种问题,只不过是以线程调度的形式来分别执行的)。本文我们以多核CPU为例。
比如同时有2个线程执行这段代码,假如初始时i的值为0,那么我们希望两个线程执行完之后i的值变为2。但是事实可能存在下面这种情况:初始时,两个线程分别读取i的值存入各自所在的CPU的高速缓存当中,然后线程1进行加1操作,然后把i的最新值1写入到内存。此时线程2的高速缓存当中i的值还是0,进行加1操作之后,i的值为1,然后线程2把i的值写入内存。
? 最终结果i的值是1,而不是2。这就是缓存一致性问题。通常称这种被多个线程访问的变量为共享变量。
也就是说,如果一个变量在多个CPU中都存在缓存(一般在多线程编程时才会出现),那么就可能存在缓存不一致的问题。
为了解决缓存不一致性问题,通常来说有以下2种解决方法:
这2种方式都是硬件层面上提供的方式。
在早期的CPU当中,是通过在总线上加LOCK#锁的形式来解决缓存不一致的问题。因为CPU和其他部件进行通信都是通过总线来进行的,如果对总线加LOCK#锁的话,也就是说阻塞了其他CPU对其他部件访问(如内存),从而使得只能有一个CPU能使用这个变量的内存。比如上面例子中 如果一个线程在执行 i = i +1,如果在执行这段代码的过程中,在总线上发出了LCOK#锁的信号,那么只有等待这段代码完全执行完毕之后,其他CPU才能从变量i所在的内存读取变量,然后进行相应的操作。这样就解决了缓存不一致的问题。
但是上面的方式会有一个问题,由于在锁住总线期间,其他CPU无法访问内存,导致效率低下。
所以就出现了缓存一致性协议。最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取。
即一个操作或者多个操作 要么全部执行并且执行的过程不会被任何因素打断,要么就都不执行。
一个很经典的例子就是银行账户转账问题:
比如从账户A向账户B转1000元,那么必然包括2个操作:从账户A减去1000元,往账户B加上1000元。这2个操作必须要具备原子性才能保证不出现一些意外的问题。
我们操作数据也是如此,比如i = i+1;其中就包括,读取i的值,计算i,写入i。这行代码在Java中是不具备原子性的,则多线程运行肯定会出问题,所以也需要我们使用同步和lock这些东西来确保这个特性了。
原子性其实就是保证数据一致、线程安全一部分,
当多个线程访问同一个变量时,一个线程修改了这个变量的值,其他线程能够立即看得到修改的值。
若两个线程在不同的cpu,那么线程1改变了i的值还没刷新到主存,线程2又使用了i,那么这个i值肯定还是之前的,线程1对变量的修改线程没看到这就是可见性问题。
程序执行的顺序按照代码的先后顺序执行。
一般来说处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。如下:
int a = 10; //语句1
int r = 2; //语句2
a = a + 3; //语句3
r = a*a; //语句4
则因为重排序,他还可能执行顺序为 2-1-3-4,1-3-2-4
但绝不可能 2-1-4-3,因为这打破了依赖关系。
显然重排序对单线程运行是不会有任何问题,而多线程就不一定了,所以我们在多线程编程时就得考虑这个问题了。
主内存:共享变量
本地内存:共享变量副本
package com.fly.thread_demo.demo_2;
/**
* volatile 关键字
*/
public class VolatileDemo extends Thread{
private Boolean flag = true;
public void setFlag(Boolean flag){
this.flag = flag;
}
@Override
public void run(){
System.out.println("线程开始...");
while (flag){
}
System.out.println("线程结束...");
}
public static void main(String[] args) throws InterruptedException {
VolatileDemo vd = new VolatileDemo();
vd.start();
Thread.sleep(3000);
vd.setFlag(false);
Thread.sleep(1000);
System.out.println(vd.flag);
}
}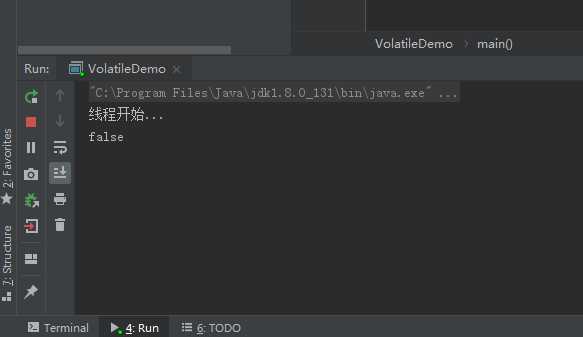
因为我在主线程中flag设置为false,但是子线程一直拿到的是本地内存中的副本,所以就算我们把flag设置为false,子线程依旧会一直运行下去。
https://blog.csdn.net/ft305977550/article/details/78769573 (System.out.println对线程安全的影响)
解决方案:private volatile Boolean flag = true; 在共享变量前加关键字volatile,修饰
上述案例如果把flag用volatile修饰过后就不一样了,第一:使用volatile关键字会强制将修改的值立即写入主存;第二:使用volatile关键字的话,当主线程进行修改时,会导致子线程的工作内存中缓存变量flag的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);第三:由于子线程的工作内存中缓存变量flag的缓存行无效,所以子线程再次读取变量flag的值时会去主存读取。那么在主线程修改flag值时(当然这里包括2个操作,修改主线程工作内存中的值,然后将修改后的值写入内存),会使得子线程的工作内存中缓存变量flag的缓存行无效,然后子线程读取时,发现自己的缓存行无效,它会等待缓存行对应的主存地址被更新之后,然后去对应的主存读取最新的值。那么子线程读取到的就是最新的正确的值。
int a = 1; //1
int b = 2; //2
int c = a+b;//3编译器重排序的典型就是通过调整指令顺序,在不改变程序语义的前提下,尽可能的减少寄存器的读取、存储次数,充分复用寄存器的存储值。重排序只会对没有依赖关系的指令进行重排序,并不会对有依赖关系的进行重排序
比如,我们第1行 和第2行 没有任何关系,所以先执行1 还是2 都不会影响语义,但是第3行就不一样了,他依赖1,2行,所以编译器不会对第3行就行重排序
package com.fly.thread_demo.demo_2;
/**
* 重排序
*/
public class SortThreadDemo {
/**
* 共享变量
*/
private int a = 0;
private boolean flag = false;
/**
* 线程1
*/
public void write(){
a = 1; //1
flag = true; //2
}
/**
* 线程2
*/
public void read(){
if(flag){ //3
a = a + a ;//4
}
}
}我们假设有两个线程 分别执行 write 方法和read方法,如果没有重排序,当flag是true是时候,a的值肯定是1,这个时候第4行代码结果是a = 2;但是第1行和第2行代码没有依赖关系,可能会发生重排序,如果发生了重排序,先执行了2 ,这个时候线程1挂起了,这个时候a=0;flag = true;线程2在执行的时候a = 0;这样就产生线程安全问题了,同样volatile可以禁止重排序,就不会发生这个问题了。
private volatile int a = 0;
private volatile boolean flag = false;标签:int 4行 技术 package 不同 高速缓存 虚拟机 特性 部分
原文地址:https://www.cnblogs.com/bigfly277/p/10202895.html