标签:文件的 基本 自动 批量上传 后缀 png 高峰 comm 代码实现
点击流日志每天都10T,在业务应用服务器上,需要准实时上传至(Hadoop HDFS)上
点击流日志每天都10T,在业务应用服务器上,需要准实时上传至(Hadoop HDFS)上
一般上传文件都是在凌晨24点操作,由于很多种类的业务数据都要在晚上进行传输,为了减轻服务器的压力,避开高峰期。
如果需要伪实时的上传,则采用定时上传的方式
HDFS SHELL: hadoop fs –put xxxx.log /data 还可以使用 Java Api
满足上传一个文件,不能满足定时、周期性传入。
定时调度器:
Linux crontab
crontab -e
*/5 * * * * $home/bin/command.sh //五分钟执行一次
系统会自动执行脚本,每5分钟一次,执行时判断文件是否符合上传规则,符合则上传
日志产生程序将日志生成后,产生一个一个的文件,使用滚动模式创建文件名。
日志生成的逻辑由业务系统决定,比如在log4j配置文件中配置生成规则,如:当xxxx.log 等于10G时,滚动生成新日志
log4j.logger.msg=info,msg
log4j.appender.msg=cn.maoxiangyi.MyRollingFileAppender
log4j.appender.msg.layout=org.apache.log4j.PatternLayout
log4j.appender.msg.layout.ConversionPattern=%m%n
log4j.appender.msg.datePattern=‘.‘yyyy-MM-dd
log4j.appender.msg.Threshold=info
log4j.appender.msg.append=true
log4j.appender.msg.encoding=UTF-8
log4j.appender.msg.MaxBackupIndex=100
log4j.appender.msg.MaxFileSize=10GB
log4j.appender.msg.File=/home/hadoop/logs/log/access.log
细节:
1、 如果日志文件后缀是1\2\3等数字,该文件满足需求可以上传的话。把该文件移动到准备上传的工作区间。
2、 工作区间有文件之后,可以使用hadoop put命令将文件上传。
阶段问题:
1、 待上传文件的工作区间的文件,在上传完成之后,是否需要删除掉。
使用ls命令读取指定路径下的所有文件信息,
ls | while read line
//判断line这个文件名称是否符合规则
if line=access.log.* (
将文件移动到待上传的工作区间
)
//批量上传工作区间的文件
hadoop fs –put xxx
脚本写完之后,配置linux定时任务,每5分钟运行一次。
代码第一版本,实现基本的上传功能和定时调度功能
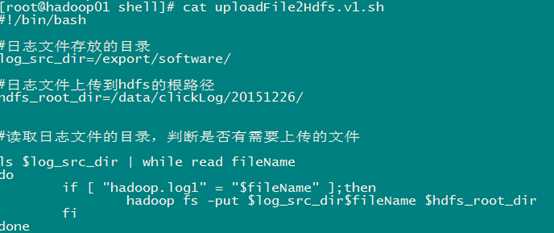
代码第二版本:增强版V2(基本能用,还是不够健全)

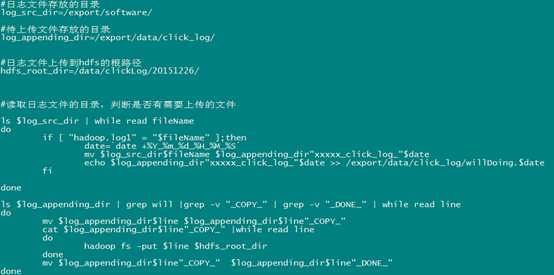
1、日志收集文件收集数据,并将数据保存起来,效果如下:

2、上传程序通过crontab定时调度

3、程序运行时产生的临时文件

4、Hadoo hdfs上的效果

大数据学习——点击流日志每天都10T,在业务应用服务器上,需要准实时上传至(Hadoop HDFS)上
标签:文件的 基本 自动 批量上传 后缀 png 高峰 comm 代码实现
原文地址:https://www.cnblogs.com/feifeicui/p/10217090.html