标签:计算 基础 print 符号位 先后 方式 最大值 分享图片 xxx
1、1字节=8位,1024字节=1KB
2、16进制0x12345678,其二进制为00010010 00110100 01010110 01111000共4字节
3、字节序:两个或多个字节存放的先后顺序(Big Endian大端序,Little Endian小端序)。UTF-16编码的头2个字节里标记字节序: LE [0xFF, 0xFE], BE [0xFE, 0xFF]
4、0x12345678以Big Endian存储:0x12 0x34 0x56 0x78
5、0x12345678以Little Endian存储:0x78 0x56 0x34 0x12
6、字符集:Unicode
7、编码:UTF-8、UTF-16、UTF-16BE、UTF-16LE等等
8、编码是字符集的一种编码方式。
9、查看编码的网站:https://unicode-table.com
10、
计算机存储补码
+1
原码:0000 0001
反码:0000 0001
补码:0000 0001
-1
原码:1000 0001
反码(负数反码:在原码基础上,除符号位外,其余取反):1111 1110
补码(负数补码:在反码基础上,加1):1111 1111
java中byte类型占8位。带符号最大值是127,带符号最小值是-128。不带符号最大值是255,不带符号最小值是0。
十进制 十六进制 二进制
254 0xfe 11111110
将254(即00000000 00000000 00000000 11111110)赋值给一个byte类型的变量, 取低8位 11111110,直接当做补码存储,其反码是1111 1101,其原码是1000 0010(十进制-2)。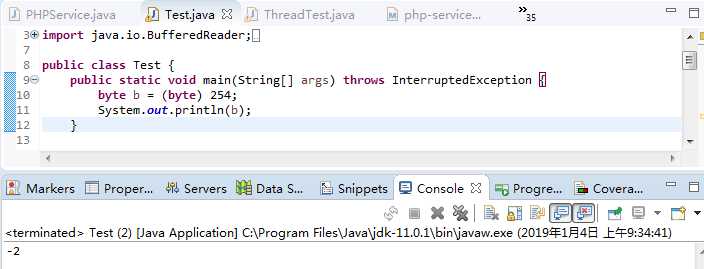
11、编码
UTF-8
没有字节序的概念。
所以1~4字节UTF-8编码看起来是这样的:
0xxxxxxx
110xxxxx 10xxxxxx
1110xxxx 10xxxxxx 10xxxxxx
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
单字节可编码的Unicode范围:\u0000~\u007F(0~127)
双字节可编码的Unicode范围:\u0080~\u07FF(128~2047)
三字节可编码的Unicode范围:\u0800~\uFFFF(2048~65535)
四字节可编码的Unicode范围:\u10000~\u1FFFFF(65536~2097151)
UTF-16
2字节或4字节
查看中文 “哈” 的编码:
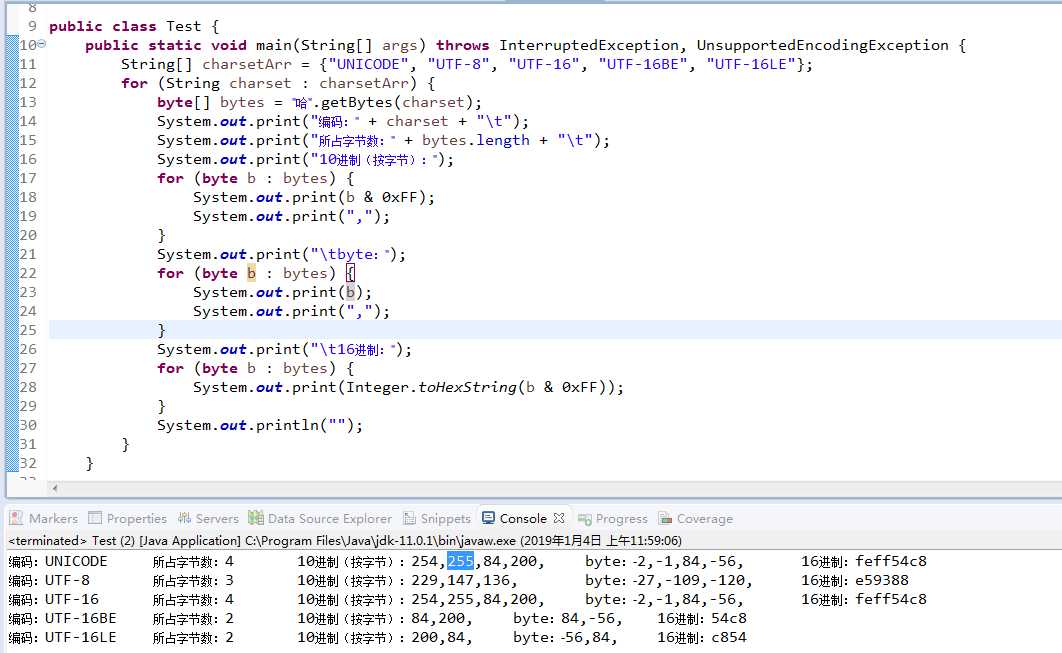
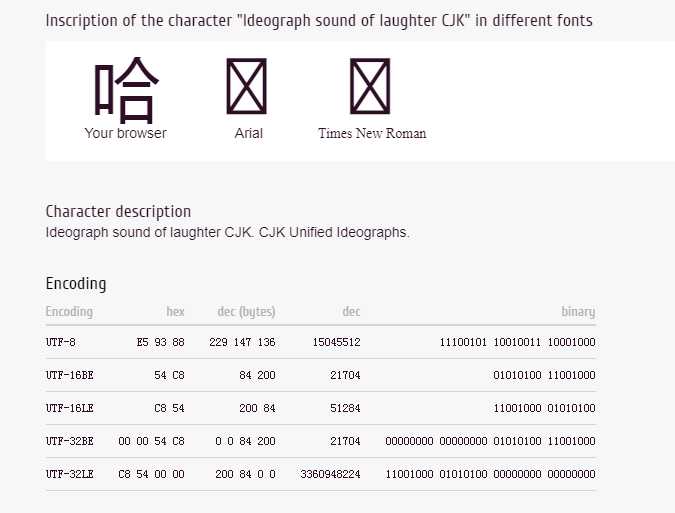
System.out.print(b & 0xFF);
b是byte类型,存储的是1000 0010(即10进制-2),当jvm检测到byte可能会转为 int,或byte与int类型进行计算时,会将byte的最高24位补1,扩充到32位,再参与计算。
1000 0010 扩充到32位:11111111 11111111 11111111 10000010。
b & 0xFF == 11111111 11111111 11111111 10000010 & 00000000 00000000 00000000 11111111
所以 b & 0xFF == 00000000 00000000 00000000 00000000 10000010 (即十进制254)
标签:计算 基础 print 符号位 先后 方式 最大值 分享图片 xxx
原文地址:https://www.cnblogs.com/natian-ws/p/10219171.html