标签:style blog http color io os 使用 ar strong

LevelDB是Google开源的持久化KV单机数据库,具有很高的随机写,顺序读/写性能,但是随机读的性能很一般,也就是说,LevelDB很适合应用在查询较少,而写很多的场景。LevelDB应用了LSM (Log Structured Merge) 策略,lsm_tree对索引变更进行延迟及批量处理,并通过一种类似于归并排序的方式高效地将更新迁移到磁盘,降低索引插入开销,关于LSM,本文在后面也会简单提及。
根据Leveldb官方网站的描述,LevelDB的特点和限制如下:
特点:
1、key和value都是任意长度的字节数组;
2、entry(即一条K-V记录)默认是按照key的字典顺序存储的,当然开发者也可以重载这个排序函数;
3、提供的基本操作接口:Put()、Delete()、Get()、Batch();
4、支持批量操作以原子操作进行;
5、可以创建数据全景的snapshot(快照),并允许在快照中查找数据;
6、可以通过前向(或后向)迭代器遍历数据(迭代器会隐含的创建一个snapshot);
7、自动使用Snappy压缩数据;
8、可移植性;
限制:
1、非关系型数据模型(NoSQL),不支持sql语句,也不支持索引;
2、一次只允许一个进程访问一个特定的数据库;
3、没有内置的C/S架构,但开发者可以使用LevelDB库自己封装一个server;
LevelDB本身只是一个lib库,在源码目录make编译即可,然后在我们的应用程序里面可以直接include leveldb/include/db.h头文件,该头文件有几个基本的数据库操作接口,下面是一个测试例子:
#include <iostream> #include <string> #include <assert.h> #include "leveldb/db.h" using namespace std; int main(void) { leveldb::DB *db; leveldb::Options options; options.create_if_missing = true; // open leveldb::Status status = leveldb::DB::Open(options,"/tmp/testdb", &db); assert(status.ok()); string key = "name"; string value = "chenqi"; // write status = db->Put(leveldb::WriteOptions(), key, value); assert(status.ok()); // read status = db->Get(leveldb::ReadOptions(), key, &value); assert(status.ok()); cout<<value<<endl; // delete status = db->Delete(leveldb::WriteOptions(), key); assert(status.ok()); status = db->Get(leveldb::ReadOptions(),key, &value); if(!status.ok()) { cerr<<key<<" "<<status.ToString()<<endl; } else { cout<<key<<"==="<<value<<endl; } // close delete db; return 0; }
上面的例子演示了如何插入、获取、删除一条记录,编译代码:
g++ -o test test.cpp libleveldb.a -lpthread -Iinclude
执行./test后,会在/tmp下面生成一个目录testdb,里面包含若干文件:
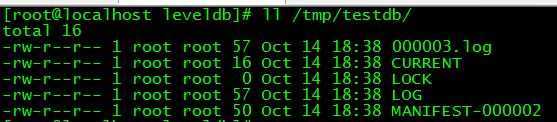
下面简要说下各个文件的含义:
1、CURRENT
2、LOG
3、LOCK
4、MANIFEST
写操作流程:
1、顺序写入磁盘log文件;
2、写入内存memtable(采用skiplist结构实现);
3、写入磁盘SST文件(sorted string table files),这步是数据归档的过程(永久化存储);
注意:在写memtable时,如果其达到check point(满员)的话,会将其改成immutable memtable(只读),然后等待dump到磁盘SST文件中,此时也会生成新的memtable供写入新数据。
从写流程可以发现,LevelDB的数据存在两个不同的地方——log文件和SST文件,前者表示新数据(包括删除操作),后者表示处理过的数据;
那么在读一条记录的时候,也需要分别在这两个不同的地方去查找,如果都不存在,才能说明该记录不存在。
读操作流程:
1、在内存中查找memtable(也包括immutable memtable);
2、如果配置了cache,查找cache;
3、根据mainfest索引文件,在磁盘中查找SST文件;

SST文件的一些实现细节:
1、每个SST文件大小上限为2MB,所以,LevelDB通常存储了大量的SST文件;
2、SST文件由若干个4K大小的blocks组成,block也是读/写操作的最小单元;
3、SST文件的最后一个block是一个index,指向每个data block的起始位置,以及每个block第一个entry的key值(block内的key有序存储);
4、使用Bloom filter加速查找,只要扫描index,就可以快速找出所有可能包含指定entry的block。
5、同一个block内的key可以共享前缀(只存储一次),这样每个key只要存储自己唯一的后缀就行了。如果block中只有部分key需要共享前缀,在这部分key与其它key之间插入"reset"标识。
SST的分层结构:
SST文件并不是平坦的结构,而是分层组织的,这也是LevelDB名称的来源。

由log直接读取的entry会写到Level 0的SST中(最多4个文件);
当Level 0的4个文件都存储满了,会选择其中一个文件Compact到Level 1的SST中;
Log:最大4MB (可配置), 会写入Level 0;
Level 0:最多4个SST文件,;
Level 1:总大小不超过10MB;
Level 2:总大小不超过100MB;
Level 3+:总大小不超过上一个Level ×10的大小。
比如:0 ? 4 SST, 1 ? 10M, 2 ? 100M, 3 ? 1G, 4 ? 10G, 5 ? 100G, 6 ? 1T, 7 ? 10T
在读操作中,要查找一条entry,先查找log,如果没有找到,然后在Level 0中查找,如果还是没有找到,再依次往更底层的Level顺序查找;如果查找了一条不存在的entry,则要遍历一遍所有的Level才能返回"Not Found"的结果。
在写操作中,新数据总是先插入开头的几个Level中,开头的这几个Level存储量也比较小,因此,对某条entry的修改或删除操作带来的性能影响就比较可控。
可见,SST采取分层结构是为了最大限度减小插入新entry时的开销;
参考文档:
http://dailyjs.com/2013/04/19/leveldb-and-node-1/
http://blog.csdn.net/qq112928/article/details/21275999
标签:style blog http color io os 使用 ar strong
原文地址:http://www.cnblogs.com/chenny7/p/4026447.html