标签:erro 构造 junit 类设计 dex 编码 bugs stc 有一个
百分制转五分制:
如果成绩小于60,转成“不及格”
如果成绩在60与70之间,转成“及格”
如果成绩在70与80之间,转成“中等”
如果成绩在80与90之间,转成“良好”
如果成绩在90与100之间,转成“优秀”
其他,转成“错误”
伪代码不需要说明具体的调用方法名,甚至不需要强调你打算使用哪种语言去编程,理清思路即可。
接下来,选择一种语言把伪代码实现,也就成了产品代码。产品代码如下:
public class MyUtil{
public static String percentage2fivegrade(int grade){
//如果成绩小于0,转成“错误”
if ((grade < 0))
return "错误";
//如果成绩小于60,转成“不及格”
else if (grade < 60)
return "不及格";
//如果成绩在60与70之间,转成“及格”
else if (grade < 70)
return "及格";
//如果成绩在70与80之间,转成“中等”
else if (grade < 80)
return "中等";
//如果成绩在80与90之间,转成“良好”
else if (grade < 90)
return "良好";
//如果成绩在90与100之间,转成“优秀”
else if (grade <= 100)
return "优秀";
//如果成绩大于100,转成“错误”
else
return "错误";
}
}
产品代码是为用户提供的,为了保证产品代码的正确性,我们需要对自己的程序来进行测试,测试时要尽量去考虑所有可能的情况,来判断结果是否合乎要求。即:我们需要去编写测试代码。
根据我现在的理解,测试代码就是用if 语句在加上在各个对应的if语句中去调用System.out.println(),来判断输出是否合乎预期,所以测试代码如下:测试代码的特点是:①if和elseif中放着的是错误情况的条件,而结果正确是只放在最后的else分支中;②不仅仅要编写正确情况下的测试代码,也得编写错误情况下的测试代码,还得编写边界情况对应的测试代码,这三个情况必不可少!具体见以下代码。
public class MyUtilTest {
public static void main(String[] args) {
//测试正常情况
if(MyUtil.percentage2fivegrade(55) != "不及格")
System.out.println("test failed!In right situation.");
else if(MyUtil.percentage2fivegrade(65) != "及格")
System.out.println("test failed!In right situation.");
else if(MyUtil.percentage2fivegrade(75) != "中等")
System.out.println("test failed!In right situation.");
else if(MyUtil.percentage2fivegrade(85) != "良好")
System.out.println("test failed!In right situation.");
else if(MyUtil.percentage2fivegrade(95) != "优秀")
System.out.println("test failed!In right situation.");
else
System.out.println("test passed!In right situation.");
//测试出错情况
if(MyUtil.percentage2fivegrade(-10) != "错误")
System.out.println("test failed 1! In error situation.");
else if(MyUtil.percentage2fivegrade(115) != "错误")
System.out.println("test failed 2! In error situation.");
else
System.out.println("test passed!In error situation.");
//测试边界情况
if(MyUtil.percentage2fivegrade(0) != "不及格")
System.out.println("test failed 1!In border situation.");
else if(MyUtil.percentage2fivegrade(60) != "及格")
System.out.println("test failed 2!In border situation.");
else if(MyUtil.percentage2fivegrade(70) != "中等")
System.out.println("test failed 3!In border situation.");
else if(MyUtil.percentage2fivegrade(80) != "良好")
System.out.println("test failed 4!In border situation.");
else if(MyUtil.percentage2fivegrade(90) != "优秀")
System.out.println("test failed 5!In border situation.");
else if(MyUtil.percentage2fivegrade(100) != "优秀")
System.out.println("test failed 6!In border situation.");
else
System.out.println("test passed!In border situation.");
}
}建筑工人人是“先把墙砌好的,再用绳子测一下墙平不平,直不直,如果不平或不直拆了重砌”,还是“先用绳子给出平和直的标准,然后靠着绳子砌墙,从而保证了墙砌出来就是又平又直的”呢?答案是不言而喻的了。
拿编程做对比,我们是该“先写产品代码,然后再写测试代码,通过测试发现了一些Bugs,修改代码”,还是该“先写测试代码,然后再写产品代码,从而写出来的代码就是正确的”呢?当然先写测试代码了。这种先写测试代码,然后再写产品代码的开发方法叫“测试驱动开发”(TDD)。TDD的一般步骤如下:
①明确当前要完成的功能,记录成一个测试列表
②快速完成编写针对此功能的测试用例
③测试代码编译不通过(没产品代码呢)
④编写产品代码
⑤测试通过
⑥对代码进行重构,并保证测试通过(重构下次实验练习)
⑦循环完成所有功能的开发
于TDD,我们不会出现过度设计的情况,需求通过测试用例表达出来了,我们的产品代码只要让测试通过就可以了。
回到目录
任务二:以TDD的方式研究学习StringBuffer
这个任务主要锻炼我们自己写JUnit测试用例的能力。给出的程序如下:
public static void main(String [] args){
StringBuffer buffer = new StringBuffer();
buffer.append(‘S‘);
buffer.append("tringBuffer");
System.out.println(buffer.charAt(1));
System.out.println(buffer.capacity());
System.out.println(buffer.length());
System.out.println(buffer.indexOf("tring"));
System.out.println("buffer = " + buffer.toString());首先,需要对这个程序进行改写,写成上面的产品代码那种类型的(有返回值的),以便于进行测试。
那么如何来进行改写呢,参考狄同学的博客可知,思路就是:先思考哪些方法需要测试?
有四个:charAt()、capacity()、length()、indexOf()。明确了哪些方法需要测试之后,接下来就开始改写产品代码,即:在产品代码中,分别为这四个方法来加上各自的返回值,这样就可以与测试代码中的断言来进行比较了。修改后的产品代码如下:
public class StringBufferDemo{
StringBuffer buffer = new StringBuffer();
public StringBufferDemo(StringBuffer buffer){
this.buffer = buffer;
}
public Character charAt(int i){
return buffer.charAt(i);
}
public int capacity(){
return buffer.capacity();
}
public int length(){
return buffer.length();
}
public int indexOf(String buf) {
return buffer.indexOf(buf);
}
}从代码上我们可以看到,我们想要测试的方法都有一个返回值,这个返回值是通过调用我们想要测试的方法得到的。测试代码如下所示:
public class StringBufferDemoTest {
StringBuffer a = new StringBuffer("StringBuffer");// Test a string which has 12 character
StringBuffer b = new StringBuffer("StringBufferStringBuffer");// Test a string which has 24 character
StringBuffer c = new StringBuffer("StringBufferStringBufferStringBuffer");// Test a string which has 36 character
@Test
public void testcharAt() {
assertEquals(‘S‘,a.charAt(0));
assertEquals(‘g‘,b.charAt(5));
assertEquals(‘r‘,c.charAt(11));
}
@Test
public void testcapacity() {
assertEquals(28,a.capacity());
assertEquals(40,b.capacity());
assertEquals(52,c.capacity());
}
@Test
public void testlength() {
assertEquals(12,a.length());
assertEquals(24,b.length());
assertEquals(36,c.length());
}
@Test
public void testindexOf() {
assertEquals(0,a.indexOf("Str"));
assertEquals(5,b.indexOf("gBu"));
assertEquals(10,c.indexOf("er"));
}
}面向对象(Object-Oriented)的三要素包括:封装、继承、多态。面向对象的思想涉及到软件设计开发的各个方面,如:面向对象分析(OOA)、面向对象设计(OOD)、面向对象编程实现(OOP)。其中:OOA根据抽象关键的问题域来分解问题,即:关注是什么(what)。OOD是一种提供符号设计系统的面向对象的实现过程,用非常接近问题域术语的方法把系统构造成“现实世界”的对象,即:关注怎么做,通过模型来实现功能规范。OOP则在设计的基础上用编程语言如:JAVA来编码。贯穿OOA、OOD、OOP的主线正是抽象。抽象一词的本意是指人在认识思维活动中对事物表象因素的舍弃和对本质因素的抽取。抽象是人类认识复杂事物和现象时经常使用的思维工具,抽象思维能力在程序设计中非常重要,"去粗取精、化繁为简、由表及里、异中求同"的抽象能力很大程度上决定了程序员的程序设计能力。
抽象就是抽出事物的本质特征而暂时不考虑他们的细节。对于复杂系统问题人们借助分层次抽象的方法进行问题求解;在抽象的最高层,可以使用问题环境的语言,以概括的方式叙述问题的解。在抽象的较低层,则采用过程化的方式进行描述。在描述问题解时,使用面向问题和面向实现的术语。
程序设计中,抽象包括两个方面,一是过程抽象,二是数据抽象。编程的重要原则之一:DRY
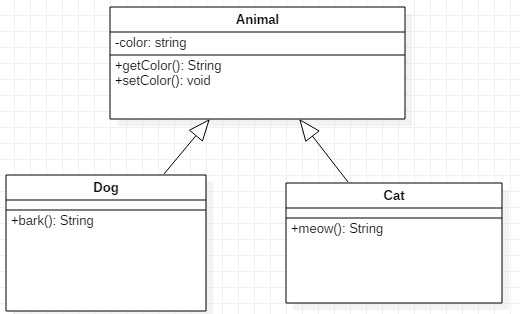
UML是一种通用的建模语言,可以非常直观的表示出各个结构之间的关系。
下面,通过具体的题目来学习设计模式。
abstract class Data{
public abstract void DisplayValue();
}
class Integer extends Data {
int value;
Integer(){
value=100;
}
public void DisplayValue(){
System.out.println(value);
}
}
class Document {
Data pd;
Document() {
pd=new Integer();
}
public void DisplayData(){
pd.DisplayValue();
}
}
public class MyDoc {
static Document d;
public static void main(String[] args) {
d = new Document();
d.DisplayData();
}
}设计模式初学者容易过度使用它们,导致过度设计,也就是说,遵守DRY和OCP当然好,但会出现YAGNI(You aren‘t gonna need it, 你不会需要它)问题。
DRY原则和YAGNI原则并非完全兼容。前者追求"抽象化",要求找到通用的解决方法;后者追求"快和省",意味着不要把精力放在抽象化上面,因为很可能"你不会需要它"。怎么平衡呢?有一个Rule of three (三次原则):第一次用到某个功能时,你写一个特定的解决方法;第二次又用到的时候,你拷贝上一次的代码(违反了DRY);第三次出现的时候,你才着手"抽象化",写出通用的解决方法。
设计模式学习先参考一下《深入浅出设计模式》,这本书可读性非常好。改写后的代码如下:支持了Long类
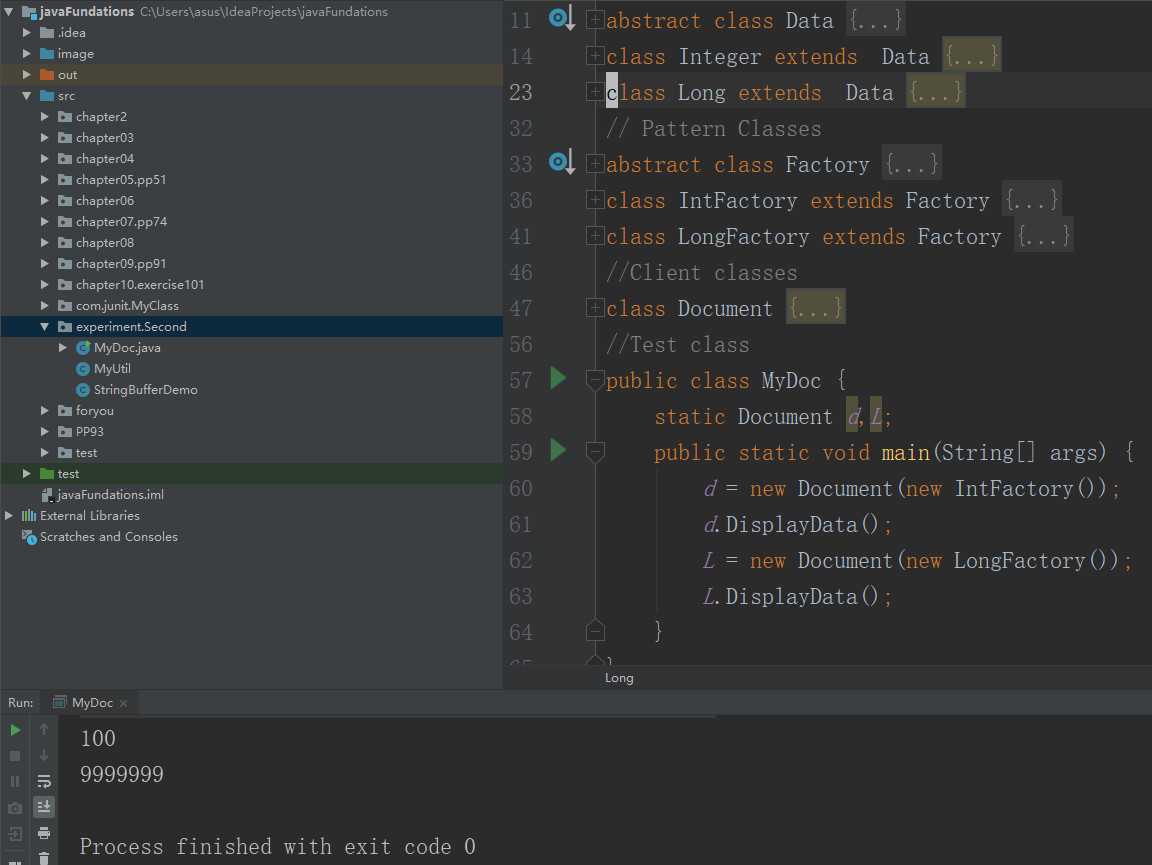
我们看到,通过增加一层抽象层代码:Factory(),使得代码符号了OCP 原则,即:没有对源代码进行修改,在源代码的基础上增加抽象层代码,实现多态,由多态来实现需求。
// 定义属性并生成getter,setter
double RealPart;
double ImagePart;
// 定义构造函数
public Complex()
public Complex(double R,double I)
//Override Object
public boolean equals(Object obj)
public String toString()
// 定义公有方法:加减乘除
Complex ComplexAdd(Complex a)
Complex ComplexSub(Complex a)
Complex ComplexMulti(Complex a)
Complex ComplexDiv(Complex a)
首先,我们来写伪代码:
①要有属性:RealPart以及ImagePart;
②要有方法:setter and getter;
③define the Constructor;(There are two kinds of Constructor);
④Override object: equals() and toString();
⑤Define method:add();subtract();multiple();divide();
接下来,测试代码如下:
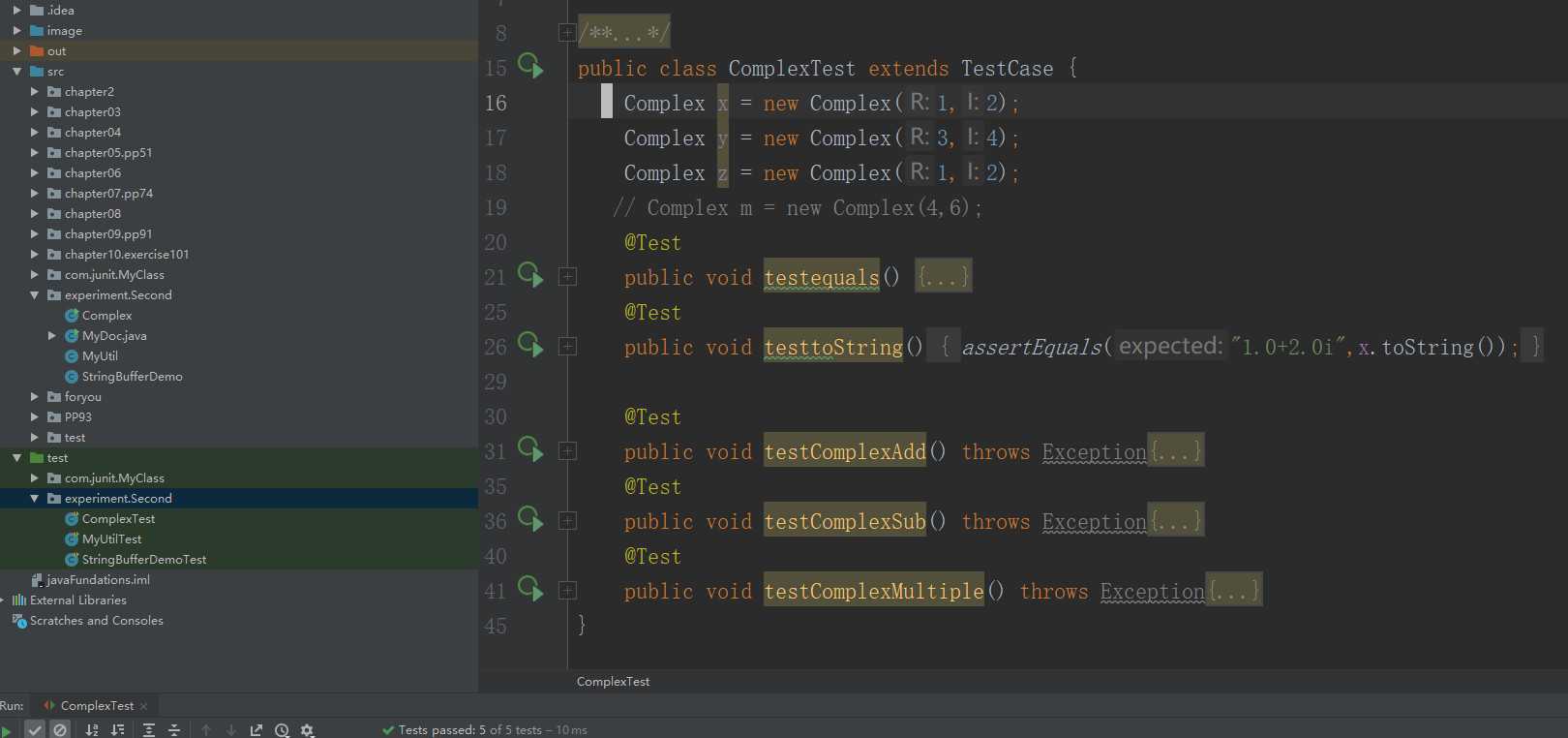
接下来,产品代码如下:
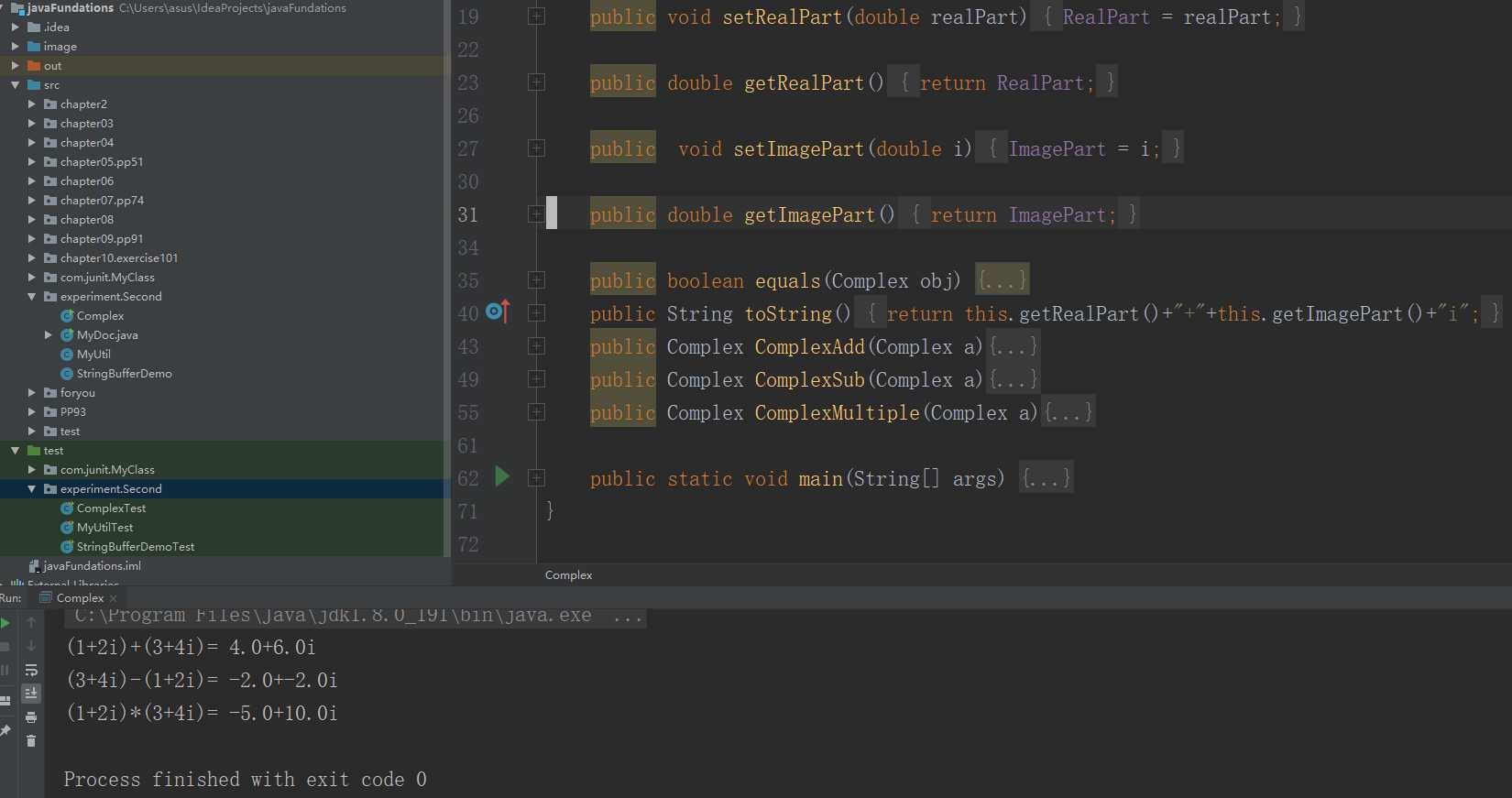
我觉得,在实际过程中,反倒是要先写出产品代码里面的函数名,就是,先想话你要测试哪些函数,具体的函数体可以先不写,然后再一键去生成JUnit测试代码,这样方便一些。就是得去解决下面这个,测试函数名不规范的问题!
标签:erro 构造 junit 类设计 dex 编码 bugs stc 有一个
原文地址:https://www.cnblogs.com/alan6y/p/10226391.html