标签:character 字符 十进制 cli poi show ons iss code
UTF-16编码规则:

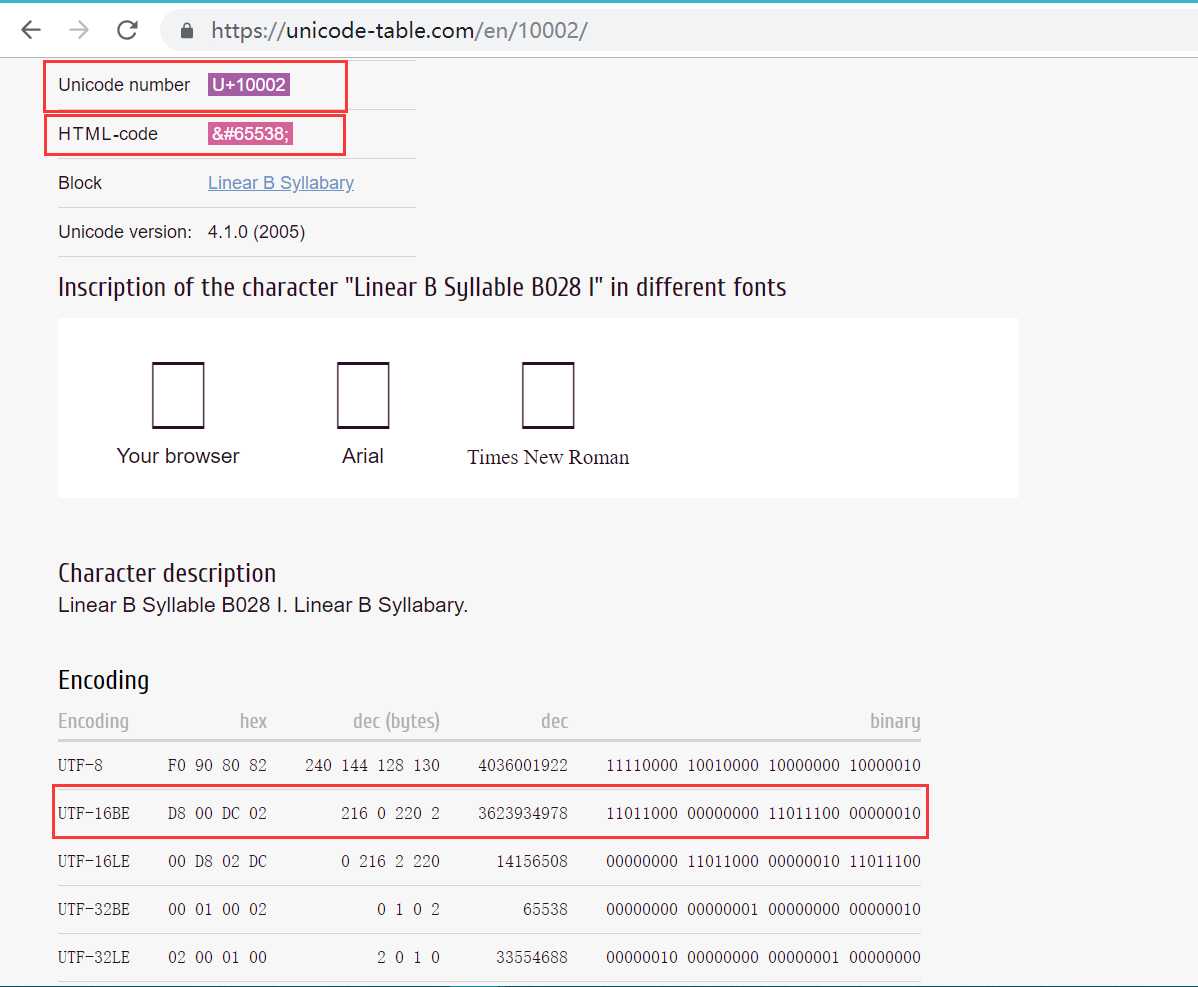
按照UTF-16编码规则计算下Unicode码位为 U+10002 (十进制:65538)的字符的UTF-16编码表示。
U+10002落在 [U+10000, U+10FFFF] 区间内。其UTF-16编码需要用四字节16位。
1、码位减去0x10000,0x10002 - 0x10000得到 0x02,即 0000000000 0000000010(20位比特)
2、高10位加上0xD800,0x00 + 0xD800得到 0xD800,即 1101 1000 0000 0000 (16位比特)
3、低10位加上0xDC00,0x02 + 0xDC00得到 0xDC02,即1101 1100 0000 0000 (16位比特)
4、所以U+10002的UTF-16编码表示位:0xD800DC02 ,即11011000 00000000 11011100 00000000(32位比特)
通过UTF-16编码,反推其Unicode码位:
1、UTF-16编码:0xD800DC02 ,即11011000 00000000 11011100 00000000(32位)。
2、前两个字节(16位)0xD800 减去 0xD800 得到 0x00,即 00 00000000(10位)
3、后两个字节(16位)0xDC02 减去 0xDC00 得到 0x02,即 00 00000010(10位)
4、0x00 和 0x02组合起来拼成0x02,即 0000 00000000 00000010(20位比特)
5、0x02 加上 0x10000 得到 0x10002,其Unicode码表示为U+10002,十进制即65538。
通过代码查看U+10002的utf-16be编码:
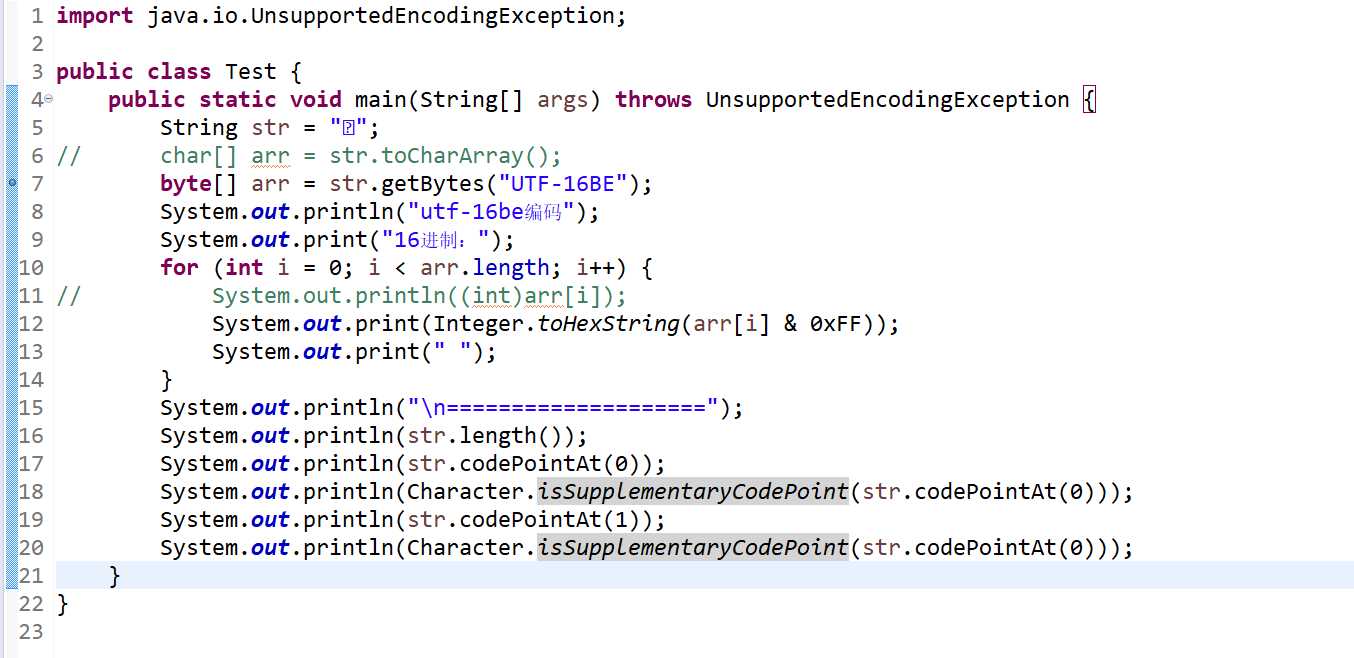
输出:
utf-16be编码
16进制:d8 0 dc 2
====================
2
65538
true
56322
true
由输出可只U+10002的UTF-16BE编码表示是:D8 00 DC 02,由4字节表示。
codePointAt()方法:

1 public int codePointAt(int index) { 2 if ((index < 0) || (index >= value.length)) { 3 throw new StringIndexOutOfBoundsException(index); 4 } 5 return Character.codePointAtImpl(value, index, value.length); 6 } 7 8 ============================================================================== 9 10 static int codePointAtImpl(char[] a, int index, int limit) { 11 char c1 = a[index]; 12 // utf-16四字节编码的字符,第一个码位(16位)的范围是 [‘\uD800‘, ‘\uDBFF‘) 13 if (isHighSurrogate(c1) && ++index < limit) { 14 char c2 = a[index]; 15 // 第二个码位(16位)的范围是 [‘\uDC00‘, ‘\uDFFF‘) 16 if (isLowSurrogate(c2)) { 17 return toCodePoint(c1, c2); 18 } 19 } 20 // 2字节UTF-16编码则直接返回该2字节。 21 // 4字节UTF-16编码的第二个codePoint则直接返回该4字节中的后2字节。 22 return c1; 23 } 24 25 ============================================================================== 26 27 public static final char MIN_HIGH_SURROGATE = ‘\uD800‘; 28 public static final char MAX_HIGH_SURROGATE = ‘\uDBFF‘; 29 30 public static final char MIN_LOW_SURROGATE = ‘\uDC00‘; 31 public static final char MAX_LOW_SURROGATE = ‘\uDFFF‘; 32 33 public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000; 34 35 ============================================================================== 36 37 public static boolean isHighSurrogate(char ch) { 38 // Help VM constant-fold; MAX_HIGH_SURROGATE + 1 == MIN_LOW_SURROGATE 39 return ch >= MIN_HIGH_SURROGATE && ch < (MAX_HIGH_SURROGATE + 1); 40 } 41 public static boolean isLowSurrogate(char ch) { 42 return ch >= MIN_LOW_SURROGATE && ch < (MAX_LOW_SURROGATE + 1); 43 } 44 45 ============================================================================== 46 47 // 根据4字节(32位)UTF-16编码求Unicode码位(通过UTF-16编码,反推其Unicode码位) 48 public static int toCodePoint(char high, char low) { 49 // Optimized form of: 50 // return ((high - MIN_HIGH_SURROGATE) << 10) 51 // + (low - MIN_LOW_SURROGATE) 52 // + MIN_SUPPLEMENTARY_CODE_POINT; 53 return ((high << 10) + low) + (MIN_SUPPLEMENTARY_CODE_POINT 54 - (MIN_HIGH_SURROGATE << 10) 55 - MIN_LOW_SURROGATE); 56 } 57 ==============================================================================
isSupplementaryCodePoint()方法:
1 public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000; 2 public static final int MAX_CODE_POINT = 0X10FFFF; 3 4 ================================================================= 5 // 根据Unicode number判断字符是否在增补字符范围 6 public static boolean isSupplementaryCodePoint(int codePoint) { 7 return codePoint >= MIN_SUPPLEMENTARY_CODE_POINT 8 && codePoint < MAX_CODE_POINT + 1; 9 }
小demo,输出字符的Unicode number的十进制形式:
1 public class Test { 2 public static void main(String[] args) throws UnsupportedEncodingException { 3 // str的第二个字符的Unicode码是U+10002 4 // 10进制65538 5 // UTF-16BE编码二进制11011000 00000000 11011100 00000010 6 String str = "A??a123"; 7 int i = 0, codePoint = 0; 8 int length = str.length(); 9 System.out.println("字符串所(" + str + ")占字节数" + str.length()*2); 10 while(i < length) { 11 codePoint = str.codePointAt(i++); 12 System.out.print(codePoint); 13 System.out.print(", "); 14 if(Character.isSupplementaryCodePoint(codePoint)) { 15 i++; 16 } 17 } 18 } 19 }
输出:

标签:character 字符 十进制 cli poi show ons iss code
原文地址:https://www.cnblogs.com/natian-ws/p/10226677.html
