标签:code rom cpu info 进程 imp display stop reading
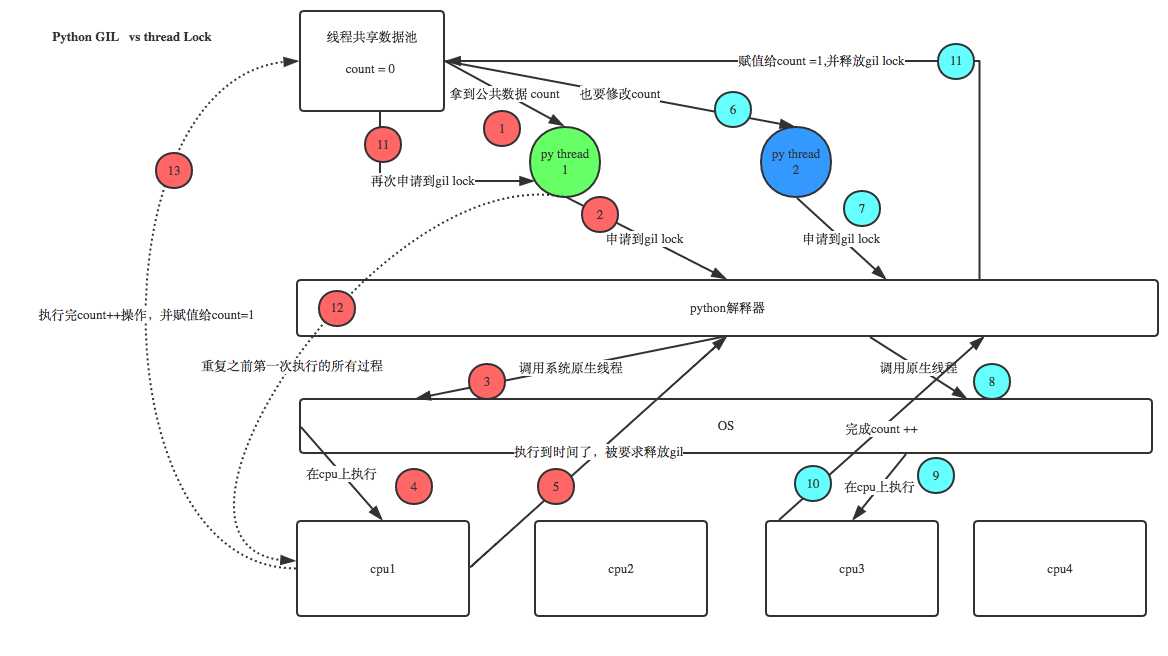
Python中的线程是操作系统的原生线程,Python虚拟机使用一个全局解释器锁(Global Interpreter Lock)来互斥线程对Python虚拟机的使用。为了支持多线程机制,一个基本的要求就是需要实现不同线程对共享资源访问的互斥,所以引入了GIL。由于GLI的存在,一个线程拥有了解释器的访问权之后,其他的所有线程都必须等待它释放解释器的访问权,即使这些线程的下一条指令并不会互相影响。在调用任何Python C API之前,都要先获得GIL。
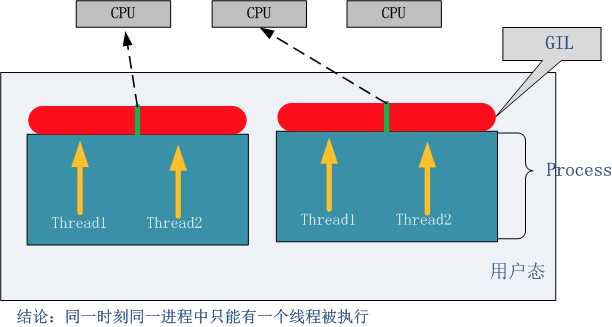
无论你启多少个线程,你有多少个cpu, Python在执行一个进程的时候会淡定的在同一时刻只允许一个线程运行。所以,python是无法利用多核CPU实现多线程的。这样,python对于计算密集型的任务开多线程的效率甚至不如串行(没有大量切换),但是对于IO密集型的任务效率还是有显著提升的。
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处
python解释器因为GIL的存在,在同一时刻同一进程中只有一个线程被执行。如何解决这一问题
首先明确一下三点:
举例:一个工人相当于cpu,此时计算相当于工人在干活,I/O阻塞相当于为工人干活提供所需原材料的过程,工人干活的过程中若没有原材料,则工人干活的过程需要停止,直到等待原材料的到来。如果你的工厂干的大多数任务都要有准备原材料的过程(I/O密集型),则有再多的工人,意义也不大,还不如一个人,在等材料的过程然后让工人去做别的事情,反过来讲,如果你的工厂原材料都齐全,那当然是工人越多,效率越高。由此可以得出结论:对计算来说,cpu越多越好,但是对于I/O来说,再多的cpu也没用当然对运行一个程序来说,随着cpu的增多执行效率肯定会有所提高(不管提高幅度多大,总会有所提高),这是因为一个程序基本上不会是纯计算或者纯I/O,所以我们只能相对的去看一个程序到底是计算密集型还是I/O密集型,从而进一步分析python的多线程到底有无用武之地.

from multiprocessing import Process from threading import Thread import os,time def work(): res=0 for i in range(100000000): res*=i if __name__ == ‘__main__‘: l=[] print(os.cpu_count()) #本机为4核 start=time.time() for i in range(4): p=Process(target=work) #耗时5s多 p=Thread(target=work) #耗时18s多 l.append(p) p.start() for p in l: p.join() stop=time.time() print(‘run time is %s‘ %(stop-start))
from multiprocessing import Process from threading import Thread import threading import os,time def work(): time.sleep(2) print(‘===>‘) if __name__ == ‘__main__‘: l=[] print(os.cpu_count()) #本机为4核 start=time.time() for i in range(400): # p=Process(target=work) #耗时12s多,大部分时间耗费在创建进程上 p=Thread(target=work) #耗时2s多 l.append(p) p.start() for p in l: p.join() stop=time.time() print(‘run time is %s‘ %(stop-start))
ps:并发的关键是你有处理多个任务的能力,不一定要同时。并行的关键是你有同时处理多个任务的能力。因而并行是并发的子集.
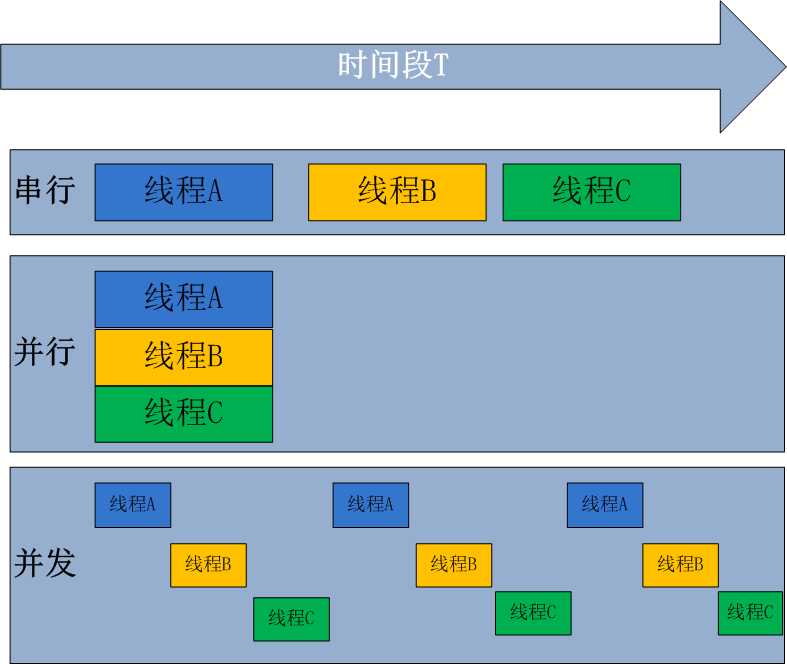
ps:打电话时就是同步通信,发短息时就是异步通信。
标签:code rom cpu info 进程 imp display stop reading
原文地址:https://www.cnblogs.com/dragon-123/p/10247252.html
