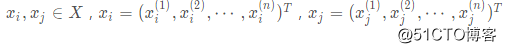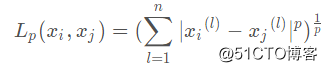标签:思想 pen ges 最大 test img 一个 学习方法 空间复杂度
1、算法介绍
k近邻算法是学习机器学习的入门算法,可实现分类与回归,属于监督学习的一种。算法的工作原理是:输入一个训练数据集,训练数据集包括特征空间的点和点的类别,可以是二分类或是多分类。预测时,输入没有类别的点,找到k个与该点距离最接近的点,使用多数表决的方法,得出最后的预测分类。
2、算法优缺点
优点:没有高深的数学思想,容易理解,精度高,对异常值不敏感,无数据输入假定;
缺点:计算复杂度高,空间复杂度高;
理解:因为knn算法是寻找与目标点接近的点,在计算时,异常值与目标点的“距离”会较远,所以对于异常值不敏感。但是,对于每一个目标点,都要计算一次。若是训练数据集数量很大,且数据集的点维度高,这样计算起来十分费时。因此,也诞生了kd树等优化算法。
3、算法三要素
knn算法三要素分别为:度量距离,k值,决策规则。
3.1、度量距离
特征空间中的两个实例点的距离是两个实例点相似程度的反映。K近邻法的特征空间一般是n维实数向量空间R^n。
对于两个样本点之间
距离(闵可夫斯基(Minkowski)距离)定义为
当p=1时,该距离称为曼哈顿距离,也称为街区距离;
当p=2时,该距离称为欧式距离,这也是高中数学中求二维空间或是三维空间中两点距离的方法;knn算法也一般取欧式距离。
当p为无穷大时,该距离称为切比雪夫距离。
3.2、k值
k值的选择会对k近邻法的结果产生重大影响。在应用中,k值一般取一个比较小的数值,通常采用交叉验证法来选取最优的k值。
3.3、决策规则
通常采用多数表决的方式,在k个距离较近的点中,哪一个分类较多即作为最后的预测结果。
4、数学例子
训练数据集
x1 x2 分类 1 1.1 A 1 1 A 0 0 B 0 0.2 B 测试数据集(0,0.1)
对于(0,0.1),取欧式距离,k=3:
L=[(1-0)^2+(1.1-0.1)^2]^0.5=√2
L=[(1-0)^2+(1-0.1)^2]^0.5=√1.81
L=[(0-0)^2+(0-0.1)^2]^0.5=√0.01
L=[(0-0)^2+(0.2-0.1)^2]^0.5=√0.01
取k=3,即取L=√1.81,A类;L=√0.01,B类;L=√0.01,B类;
根据多数表决规则,(0,0.1)属于B类
5、数据预处理:归一化数值
为了防止某一特征对结果的影响太大,故常采用数据归一化对数据进行预处理。
归一化是将特征数值转化为0到1之间的值
公式为:newValue = (oldValue - min)/(max - min)
6、knn算法代码实现
6.1、Python代码:
def calDistance(vector1, vector2, q):#定义计算闵可夫斯基距离的函数
distance = 0.0
n = len(vector1)
for i in range(n):
distance += pow(abs(vector1[i] - vector2[i]), q)
return round(pow(distance, 1.0 / q), 3)
def findNearestNeighbor(train_x,train_y,item,q=2,k=10):
neighbors = []#存储训练集与目标点的结果【训练集点,该点分类,距离】
k_neighbors = {}#存储十个近邻的结果及投票次数
for x,y in zip(train_x,train_y):#遍历训练集和目标点的距离,并存储在neighbors
distance = calDistance(x,item,q)
neighbors.append([x,y,distance])
neighbors.sort(key=lambda x:x[2])#根据距离进行排序
for i in range(k):#遍历结果,将k个最近邻的点的结果写成字典形式
k_neighbors.setdefault(neighbors[i][1],0)
k_neighbors[neighbors[i][1]] += 1
# 返回排序后的k个近邻键值对
nearest_neighbor = sorted(k_neighbors.items(),key=lambda x:x[1],reverse=True)
#返回最大的投票数那个key
return nearest_neighbor[0][0]
if __name__ == ‘__main__‘:
data_x = [[1,1],[1,1.1],[0,0],[0,0.2]]
data_y = [‘A‘,‘A‘,‘B‘,‘B‘]
item = [0,0]
q = 2
k = 3
result = findNearestNeighbor(train_x=data_x,train_y=data_y,item=item,q=q,k=k)
print(‘预测分类为:‘,result)6.2、sklearn库的实现
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn import datasets
iris = datasets.load_iris()#鸢尾花数据是一个字典,鸢尾花特征的key是data,类型的key是target
iris_X = iris.data# 拆分属性数据
iris_y = iris.target# 拆分类别数据
# 拆分测试集和训练集,并进行预测,其中训练集80%,测试集20%
iris_X_train , iris_X_test, iris_y_train ,iris_y_test = train_test_split(iris_X, iris_y, test_size=0.2,random_state=0)
knn = KNeighborsClassifier(n_neighbors=10,p=2)#创建knn算法
knn.fit(iris_X_train, iris_y_train)# 提供训练集进行训练
predict_result = knn.predict(iris_X_test)# 预测测试集鸢尾花类型
correct_rate = knn.score(iris_X_test, iris_y_test)#计算正确率
print(‘预测结果‘,predict_result)
print(‘预测准确率‘,str(correct_rate*100)+‘%‘)参考书籍:
《统计学习方法》--李航
《机器学习实战》--Peter
本次的学习就到此结束啦!感兴趣的读者或者想和我聊聊的请私信我,或者关注公众号:程序员吃橘子
标签:思想 pen ges 最大 test img 一个 学习方法 空间复杂度
原文地址:http://blog.51cto.com/14065757/2341445