标签:baidu content port string html 标签 css 分享图片 节点 col
记录下各种使用姿态
测试的 html 代码:
<html> <head> <title>Test</title> <body> <p class="title"> <b>Test</b> </p> <div name="ele" class="story"> "i‘m a div" <ul> <li> <a href="http://www.baidu.com" id="link1"> <img src="http://www.baidu.com" data-src=‘//www.baidu.com‘> </a> </li> <li> <a href="http://www.baidu.com" id="link2"> <img src="data:image/jpg;base64,covijfklawefonva..."> </a> </li> </ul> </div>
这里使用了 python 内置的解析器:
soup = BeautifulSoup(html, ‘html.parser‘)
开始输出
# 输出整个 html print ‘\n‘, soup.prettify()
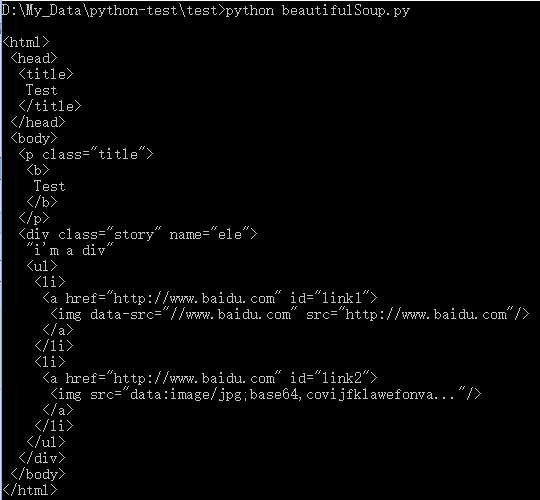
# title 标签 print ‘\n‘, soup.title

# title 标签名称 print ‘\n‘, soup.title.name

# title 标签内容 print ‘\n‘, soup.title.string

# title 标签的父级标签名称 print ‘\n‘, soup.title.parent.name

# p 标签(首个 p) print ‘\n‘, soup.p
# p 标签名称 print ‘\n‘, soup.p.name

# p 标签下的 b 标签 print ‘\n‘, soup.p.b

# p 标签的 class 属性值,类型、数组首个值 print ‘\n‘, soup.p["class"], type(soup.p["class"]), soup.p["class"][0]

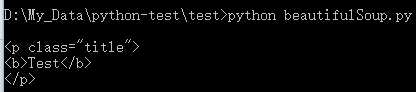
# 首个 a 标签 print ‘\n‘, soup.a

# 查找所有 a 标签, 类型数组 a_arr = soup.find_all(‘a‘) for value in a_arr: print value
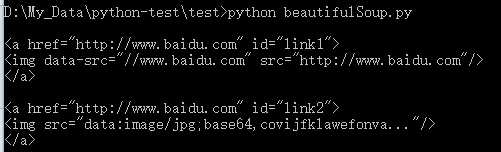
# 查找 id = link2 的标签(特殊的标签属性可以不写 attrs) print ‘\n‘, soup.find(id=‘link2‘)

# 查找 class 是 title 的标签 print ‘\n‘, soup.find(attrs={‘class‘: ‘title‘})
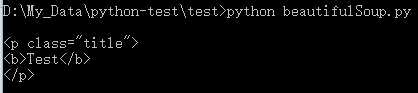
# 查找 name 是 ele 的标签 print ‘\n‘, soup.find(attrs={‘name‘: ‘ele‘})
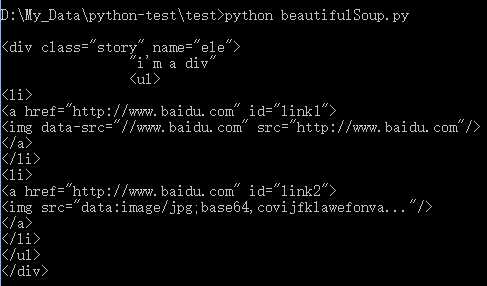
# 查找 img,获取相应属性值 img_arr = soup.find_all(‘img‘) for value in img_arr: print ‘\n ‘, value[‘src‘] attrs = value.attrs for attr in attrs: print ‘\n ‘, attr if attr == ‘data-src‘: print ‘\n ‘, value[attr]
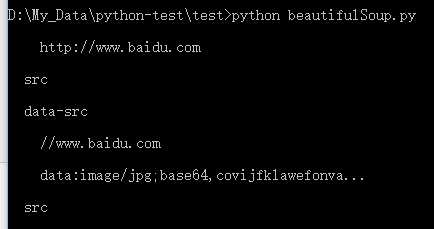
# 获取 div 标签下所有子节点 print ‘\n‘, soup.div.contents,

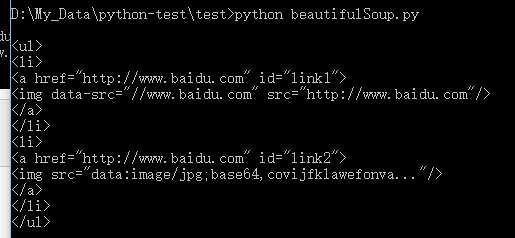
# 获取 div 下第二个子节点 print ‘\n‘, soup.div.contents[1]
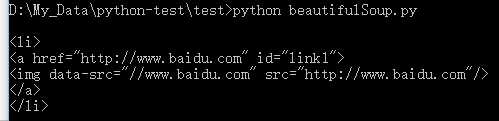
# 获取 div 下第二个子节点 print ‘\n‘, soup.div.contents[1].li
# 获取 b 标签的文本内容 print ‘\n‘, soup.b.get_text()

# 获取无值属性再判断是否None print ‘\n‘, soup.div.title, type(soup.div.title), soup.div.title == None, not soup.div.title

# css 选择器 select() print ‘\n‘, soup.select(‘b‘)

最后,贴上测试代码
# -*- coding: utf-8 -*- from bs4 import BeautifulSoup def main(): html = ‘‘‘ <html> <head> <title>Test</title> <body> <p class="title"> <b>Test</b> </p> <div name="ele" class="story"> "i‘m a div" <ul> <li> <a href="http://www.baidu.com" id="link1"> <img src="http://www.baidu.com" data-src=‘//www.baidu.com‘> </a> </li> <li> <a href="http://www.baidu.com" id="link2"> <img src="data:image/jpg;base64,covijfklawefonva..."> </a> </li> </ul> </div> ‘‘‘ soup = BeautifulSoup(html, ‘html.parser‘) # 输出整个 html # print ‘\n‘, soup.prettify() # title 标签 # print ‘\n‘, soup.title # title 标签名称 # print ‘\n‘, soup.title.name # title 标签内容 # print ‘\n‘, soup.title.string # title 标签的父级标签名称 # print ‘\n‘, soup.title.parent.name # p 标签(首个 p) # print ‘\n‘, soup.p # p 标签名称 # print ‘\n‘, soup.p.name # p 标签下的 b 标签 # print ‘\n‘, soup.p.b # p 标签的 class 属性值,类型、数组首个值 # print ‘\n‘, soup.p["class"], type(soup.p["class"]), soup.p["class"][0] # 首个 a 标签 # print ‘\n‘, soup.a # 查找所有 a 标签, 类型数组 # a_arr = soup.find_all(‘a‘) # for value in a_arr: # print ‘\n‘, value # 查找 id = link2 的标签(特殊的标签属性可以不写 attrs) # print ‘\n‘, soup.find(id=‘link2‘) # 查找 class 是 title 的标签 # print ‘\n‘, soup.find(attrs={‘class‘: ‘title‘}) # 查找 name 是 ele 的标签 # print ‘\n‘, soup.find(attrs={‘name‘: ‘ele‘}) # 查找 img,获取相应属性值 # img_arr = soup.find_all(‘img‘) # for value in img_arr: # print ‘\n ‘, value[‘src‘] # attrs = value.attrs # for attr in attrs: # print ‘\n ‘, attr # if attr == ‘data-src‘: # print ‘\n ‘, value[attr] # 获取 div 标签下所有子节点 # print ‘\n‘, soup.div.contents, # 获取 div 下首个子节点 # print ‘\n‘, soup.div.contents[0] # 获取 div 下第二个子节点 # print ‘\n‘, soup.div.contents[1] # 获取 div 下第二个子节点 # print ‘\n‘, soup.div.contents[1].li # 获取 b 标签的文本内容 # print ‘\n‘, soup.b.get_text() # 获取无值属性 # print ‘\n‘, soup.div.title, type(soup.div.title), soup.div.title == None, not soup.div.title # not 取反 # if not None: # print None # css 选择器 select() print ‘\n‘, soup.select(‘b‘) # file onload if __name__ == ‘__main__‘: main()
python 极好用的解析 html 标签的模块 - BeautifulSoup
标签:baidu content port string html 标签 css 分享图片 节点 col
原文地址:https://www.cnblogs.com/guofan/p/10255522.html