标签:import fc7 code 符号 hello min 开始 贪婪 dfs
正则就是用一些具有特殊意义的符号组合到一起(正则表达式)来描述字符或者字符串的方法,在python中正则匹配时通过re模块来实现的
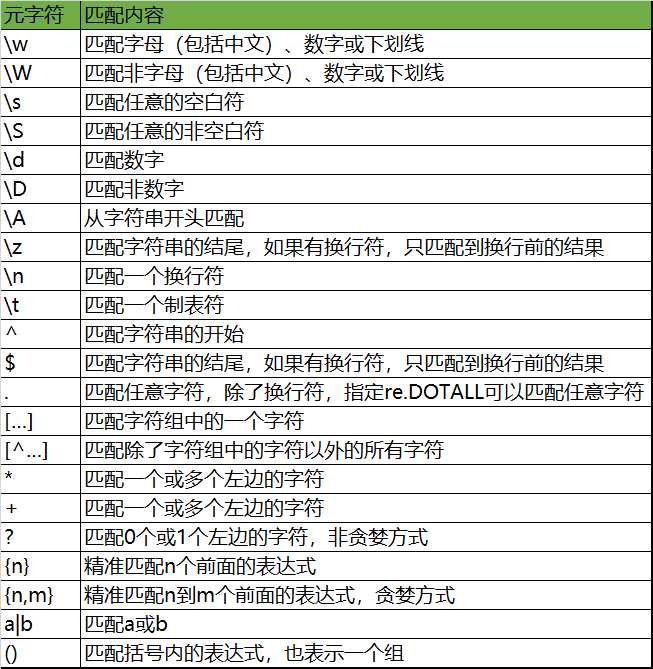
# \w与\W # s2 = "df当你 的_眼 睛眯|着/笑?sh29 sedn" # print(re.findall("\w", s2)) # [‘d‘, ‘f‘, ‘当‘, ‘你‘, ‘的‘, ‘_‘, ‘眼‘, ‘睛‘, ‘眯‘, ‘着‘, ‘笑‘, ‘s‘, ‘h‘, ‘2‘, ‘9‘, ‘s‘, ‘e‘, ‘d‘, ‘n‘] # print(re.findall("\W", s2)) # [‘ ‘, ‘ ‘, ‘ ‘, ‘|‘, ‘/‘, ‘?‘, ‘ ‘] # \s与\S # s3 = "df当\b 2\t眯|着/笑\r?sh\n29 d\nn" # print(re.findall("\s", s3)) # [‘ ‘, ‘ ‘, ‘\t‘, ‘\r‘, ‘\n‘, ‘ ‘, ‘\n‘] # print(re.findall("\S", s3)) # [‘d‘, ‘f‘, ‘当‘, ‘\x08‘, ‘2‘, ‘眯‘, ‘|‘, ‘着‘, ‘/‘, ‘笑‘, ‘?‘, ‘s‘, ‘h‘, ‘2‘, ‘9‘, ‘d‘, ‘n‘] # \d与\D # print(re.findall("\d", s3)) # [‘2‘, ‘2‘, ‘9‘] # print(re.findall("\D", s3)) # [‘d‘, ‘f‘, ‘当‘, ‘\x08‘, ‘ ‘, ‘ ‘, ‘\t‘, ‘眯‘, ‘|‘, ‘着‘, ‘/‘, ‘笑‘, ‘\r‘, ‘?‘, ‘s‘, ‘h‘, ‘\n‘, ‘ ‘, ‘d‘, ‘\n‘, ‘n‘] # \A与^ # print(re.findall("\Adf", s3)) # [‘df‘] # print(re.findall("\Ad", s3)) # [‘d‘] # print(re.findall("\A当", s3)) # [] # print(re.findall("^df", s3)) # [‘df‘] # print(re.findall("^当", s3)) # [] # s4 = "df当\b 你的眼 睛眯|着/?sh\n29 dn笑" # \Z $ \z不能用 # print(re.findall("笑\Z", s4)) # [‘笑‘] # print(re.findall("笑$", s4)) # [‘笑‘] # s5 = "s_\t\t\nhe\t哈哈\n\n 爱好 \ru\n" # \n与\t # print(re.findall("\n", s5)) # [‘\n‘, ‘\n‘, ‘\n‘, ‘\n‘] # print(re.findall("\t", s5)) # [‘\t‘, ‘\t‘, ‘\t‘]
# . ? * + {m,n} .* .*? # . 匹配任意字符,除了换行符(加上re.DOTALL这二个参数可以匹配\n) # s1 = "aa bbb aabb acb agb bba babbcb" # print(re.findall("a.b", s1)) # [‘a b‘, ‘aab‘, ‘acb‘, ‘agb‘, ‘a b‘, ‘abb‘] # print(re.findall("aa.b", s1)) """ 匹配逻辑 1. 读取三个字符 2. 进行匹配 3. 成功则返回这三个字符,并从最后一个字符下一个字符开始匹配 4. 失败则从第一个字符的下一个字符开始匹配 """ # s2 = "aa babb aabb aaab aaaab bab ba" # ? 匹配0个或多个左边(单个)字符表达式,满足贪婪规则 # print(re.findall("a?b", s2)) # [‘b‘, ‘ab‘, ‘b‘, ‘ab‘, ‘b‘, ‘b‘, ‘ab‘, ‘b‘, ‘b‘, ‘b‘] # * 匹配0个或多个左边(单个)字符的表达式 满足贪婪规则 # s3 = "aa babb aabb aacb aaab bba ba" # print(re.findall("aa*b", s3)) # [‘ab‘, ‘aab‘, ‘aaab‘] # print(re.findall("a*b", s3)) # [‘b‘, ‘ab‘, ‘b‘, ‘aab‘, ‘b‘, ‘b‘, ‘aaab‘, ‘b‘, ‘b‘, ‘b‘] # + 匹配一个或多个左边字符的表达式,满足贪婪规则 # print(re.findall("a+b", s3)) # [‘ab‘, ‘aab‘, ‘aaab‘] # print(re.findall("ab+b", s3)) # [‘abb‘, ‘abb‘] # {m,n} 匹配m个至n个左边表达式,满足贪婪规则 # s4 = ‘ab aab aaab aaaaabb‘ # print(re.findall("a{2,4}b", s4)) # [‘aab‘, ‘aaab‘, ‘aaaab‘] # .* 贪婪匹配(尽可能地多),从头到尾 s5 = "ab aa_b a*()b" # print(re.findall("a.*b", s5)) # [‘ab aa_b a*()b‘] 匹配以a开头以b结尾的任意长度的字符串 # 上式匹配逻辑:从a开始,找到最后一个b,停止 # print(re.findall("a.*_", s5)) # [‘ab aa_‘] # .*?从头到尾匹配,非贪婪 # print(re.findall("a.*?b", s5)) # [‘ab‘, ‘aa_b‘, ‘aa*()b‘] # 上式匹配逻辑:从a开始,找到第一个b,停止,继续下一轮匹配
# []
# [] 括号中可以放任意一个字符 # - 在括号中表示范围,如果你要匹配上-,那么这个不能放在中间 # s1 = ‘a1b a3b abb a*b acb a_b‘ # print(re.findall("a[abc]b", s1)) # [‘abb‘, ‘acb‘] # [abc]表示abc中的任意一个字符 # print(re.findall("a[1-9]b", s1)) # [‘a1b‘, ‘a3b‘] # s2 = ‘aAb aWb aeb a*b arb a_b‘ # print(re.findall("a[A-Z]b", s2)) # [‘aAb‘, ‘aWb‘] # print(re.findall("a[a-z]b", s2)) # [‘aeb‘, ‘arb‘] # print(re.findall("a[A-Za-z]b", s2)) # [‘aAb‘, ‘aWb‘, ‘aeb‘, ‘arb‘]
分组
# 分组 # ()制定一个规则,将满足规则的结果匹配出来 # 练习1:找到s4里面的hang juan min # s4 = "hang_1 hang_gr juan_1 min_1" # print(re.findall("(.*?)_1", s4)) # [‘hang‘, ‘ hang_gr juan‘, ‘ min‘] # print(re.findall("([a-z]+)_1", s4)) # [‘hang‘, ‘juan‘, ‘min‘] # 分析:都是以字母开头,以_1结尾,字母可以有多个 # 练习2:找到一个标签里的网址 # s5 = ‘<a href="http://www.baidu.com">点击</a>‘ # print(re.findall(‘href="([a-z].*?)"‘, s5)) # [‘http://www.baidu.com‘] # | 匹配左边或右边 # s6 = "hanser:149 yousa:148 mandy:160" # print(re.findall("hanser|yousa|mandy", s6)) # [‘hanser‘, ‘yousa‘, ‘mandy‘] # s7 = ‘Too many companies have gone bankrupt, and the next one is my company‘ # print(re.findall("compan(?:y|ies)", s7)) # [‘companies‘, ‘company‘] # ?:表示将整体匹配出来而不只是()你里面的内容
全部找到并返回一个列表
# 找到下面标签里面的网址
import re s1 = ‘<img src="https://pic3.zhimg.com/80/v2-1d1a5e4f422a77372514a57f38503f3e_hd.jpg" data-rawwidth="564" data-rawheight="699" data-size="normal" data-default-watermark-src="https://pic1.zhimg.com/v2-22b99e59d8efc7e7dec3faba8fbf2a24_b.jpg" class="origin_image zh-lightbox-thumb lazy" width="564" data-original="https://pic3.zhimg.com/v2-1d1a5e4f422a77372514a57f38503f3e_r.jpg" data-actualsrc="https://pic3.zhimg.com/v2-1d1a5e4f422a77372514a57f38503f3e_b.jpg">‘ print(re.findall(‘src="([a-z].*?)"‘, s1))
# 结果[‘https://pic3.zhimg.com/80/v2-1d1a5e4f422a77372514a57f38503f3e_hd.jpg‘, ‘https://pic1.zhimg.com/v2-22b99e59d8efc7e7dec3faba8fbf2a24_b.jpg‘, ‘https://pic3.zhimg.com/v2-1d1a5e4f422a77372514a57f38503f3e_b.jpg‘]
找到第一个并返回包含匹配信息的对象,该对象可以通过group()方法得到匹配的字符串,没找到返回None
s = "Hanser is a little girl in kindergarten" ret = re.search("[A-Z][a-z]*", "Hanser is a little girl in kindergarten") print(ret) # <_sre.SRE_Match object; span=(0, 6), match=‘Hanser‘> print(ret.group()) # Hanser
同search,区别在于从字符串开始处进行匹配,可以用search+^代替
s = "Hanser is a little girl in kindergarten" print(re.match("Hanser", s).group()) # Hanser
按照指定的分割符分割
s = "Hanser is a little girl in kindergarten" print(re.split(" ", s)) # [‘Hanser‘, ‘is‘, ‘a‘, ‘little‘, ‘girl‘, ‘in‘, ‘kindergarten‘]
s1 = "花褪残红青杏小,燕子飞时,绿水人家绕。枝上柳绵吹又少,天涯何处无芳草。" # 方法一: lst = re.split("[,。]", s1) # [‘花褪残红青杏小‘, ‘燕子飞时‘, ‘绿水人家绕‘, ‘枝上柳绵吹又少‘, ‘天涯何处无芳草‘, ‘‘] for i in lst: if i: # 过滤空字符 print(i[0]) # 花 燕 绿 枝 天 # 方法二: lst1 = re.findall(r"[,。]([^,。])", s1) print(lst1) # [‘燕‘, ‘绿‘, ‘枝‘, ‘天‘] 只能找到除去开头的短句首字
替换
s2 = "大家好,我是常山赵子龙" print(re.sub("常山", "石家庄", s2)) # 大家好,我是石家庄赵子龙
# compile 制定一个匹配规则 obj = re.compile("\d{2}") print(obj.search("sdfs14523sdf").group()) # 14 print(obj.findall("sdfs14523sdf")) # [‘14‘, ‘52‘]
返回一个存放匹配结果的迭代器
ret = re.finditer("\d", "sd283sef8w3o7sh") print(ret) # 迭代器 <callable_iterator object at 0x000001C37F3A9C50> print(next(ret)) # match对象 print(next(ret).group()) # 8 print(next(ret).group()) # 3 print(next(ret).group()) # 8 print([i.group() for i in ret]) # 查看剩余结果
# ret = re.search(r"<(?P<tag_name>\w+)>\w+</(?P=tag_name)>", "<h1>hello</h1>") # 在分组中利用?P<name>给分组起名字 # 获取的匹配结果可以直接用group("名字")拿到对应的值 # print(ret.group()) # <h1>hello</h1> # print(ret.group("tag_name")) # h1 # 如果不给组起名字,也可以用\序号来找到对应的组,获取的结果可以直接用group(序号)拿到对应的值 # ret = re.search(r"<(\w+)>\w+</\1>", "<h1>hello</h1>") # print(ret.group()) # <h1>hello</h1> # print(ret.group(1)) # h1 # ret = re.findall(r"<(?P<tag_name>\w+)>\w+</(?P=tag_name)>", "<h1>hello</h1>") # print(ret) # [‘h1‘]
标签:import fc7 code 符号 hello min 开始 贪婪 dfs
原文地址:https://www.cnblogs.com/zzliu/p/10257371.html