标签:遍历 ati sources requests 官方网站 实体 北京 组成 时代
在高速发展的时代。乘车出远门是必不可少的,有些查询信息是要收费的。这里打造免费获取火车票信息
想要爬取12306火车票信息,访问12306官方网站,输入出发地,目的地 ,时间 之后点击确定,这是我们打开谷歌浏览器开发者模式找到 https://kyfw.12306.cn/otn/resources/js/framework/station_name.js 这里包含了所有城市的信息和所有城市的缩写字母。想要获取火车票信息 https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-19&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=SHH&purpose_codes=ADULT ,这是北京到上海 浏览器确定之后所抓的包 从中可以 看出 BJP =北京 而 SHH=上海 . 下图为 所有城市代号
现在把上面的js 数据转变为json数据 {“北京”:BJP ,"上海":SSH}
根据字符窜的 split ()方法 按照“=”进行拆分 取出等号后面的数据 “字符窜”.split("=")[1] 这样就获取到 等号后面的数据 如下图:

获得数据之后然后在根据 "|" 进行拆分 并去除 “@”得到如下

根据相邻俩个组成json数据,遍历数组 分为俩个数组 一个为 实体 一个为简写 然后再根据python强大的 函数 dict(zip(数组1,数组2)) 将其变为 json键值对之后将数据
https://kyfw.12306.cn/otn/leftTicket/queryZ?leftTicketDTO.train_date=2019-01-19&leftTicketDTO.from_station=BJP&leftTicketDTO.to_station=SHH&purpose_codes=ADULT 抓包获得是网址 之后利用selenium 进行定位 beautifulsoup解析数据 获取要的值然后进行 保存
以下是完整代码截图 仅供参考
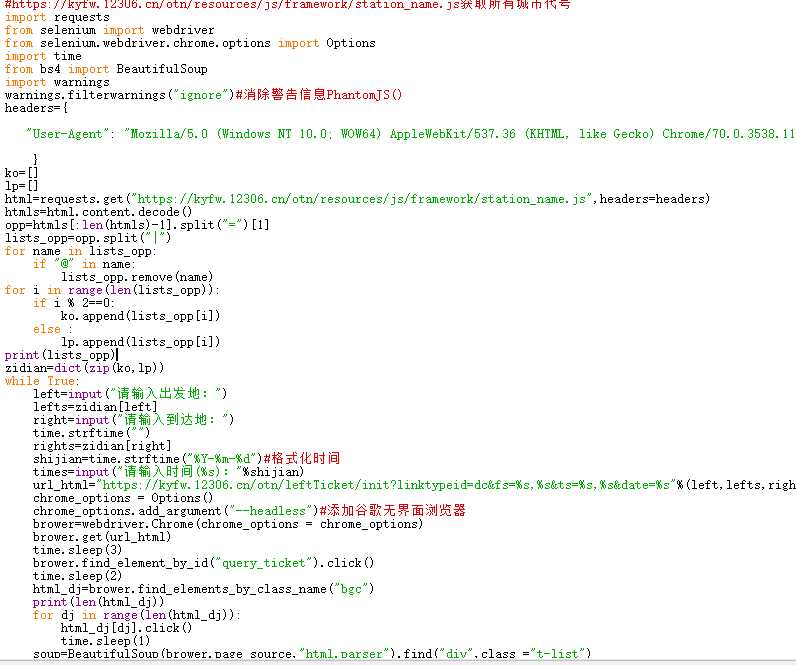
python利用selenium+requests+beautifulsoup爬取12306火车票信息
标签:遍历 ati sources requests 官方网站 实体 北京 组成 时代
原文地址:https://www.cnblogs.com/MaomaoWorld/p/10258404.html