标签:redis。 数据 压力 最好 关于我 相关 内容 hba rdbms
大数据时代,企业对于DBA也提出更高的需求。同时,NoSQL作为近几年新崛起的一门技术,也受到越来越多的关注。本文将基于个推SRA孟显耀先生所负责的DBA工作,和大数据运维相关经验,分享两大方向内容:一、公司在KV存储上的架构演进以及运维需要解决的问题;二、对NoSQL如何选型以及未来发展的一些思考。
据官方统计,截止目前(2018年4月20日)NoSQL有225个解决方案,具体到每个公司,使用的都是其中很小的一个子集,下图中蓝色标注的产品是当前个推正在使用的。
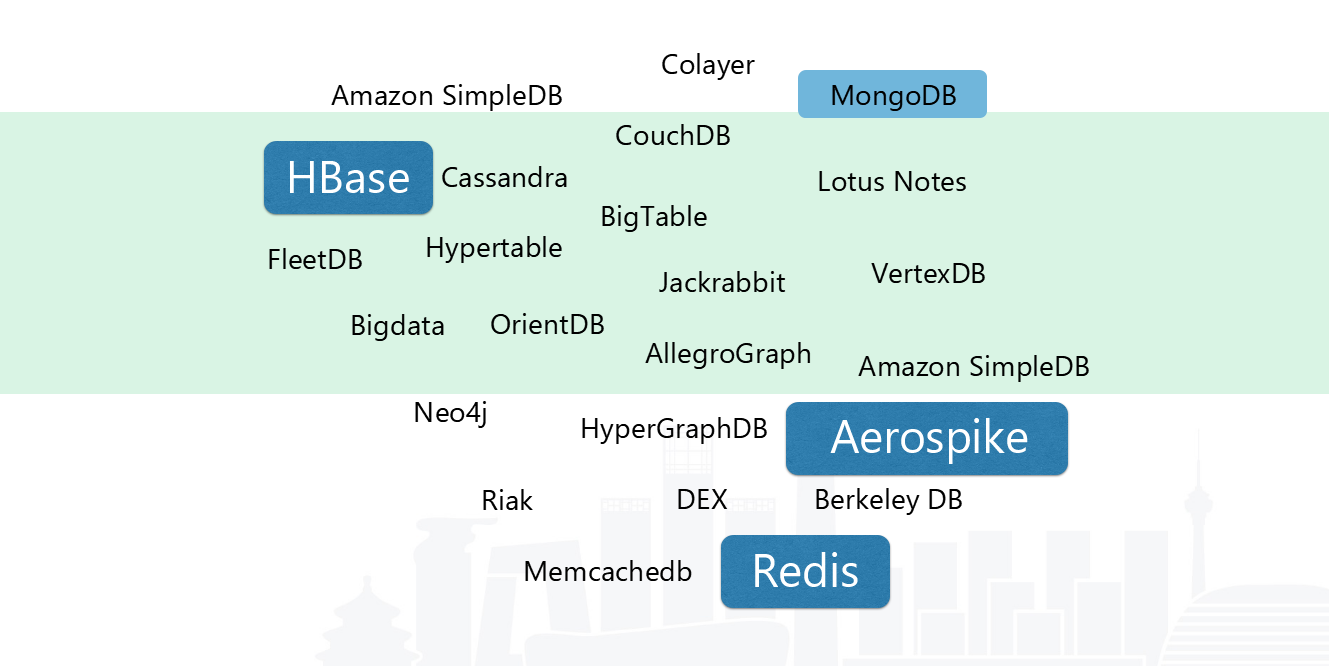
NoSQL的由来
1946年,第一台通用计算机诞生。但一直到1970年RDMBS的出现,大家才找到通用的数据存储方案。到21世纪,DT时代让数据容量成为最棘手的问题,对此谷歌和亚马逊分别提出了自己的NoSQL解决方案,比如谷歌于2006年提出了Bigtable。2009年的一次技术大会上,NoSQL一词被正式提出,到现在共有225种解决方案。
NoSQL与RDMBS的区别主要在两点:第一,它提供了无模式的灵活性,支持很灵活的模式变更;第二,可伸缩性,原生的RDBMS只适用于单机和小集群。而NoSQL一开始就是分布式的,解决了读写和容量扩展性问题。以上两点,也是NoSQL产生的根本原因。
实现分布式主要有两种手段:副本(Replication)和分片(Sharding)。Replication能解决读的扩展性问题和HA(高可用),但是无法解决读和容量的扩展性。而Sharding可以解决读写和容量的扩展性。一般NoSQL解决方案都是将二者组合起来。
Sharding主要解决数据的划分问题,主要有基于区间划分(如Hbase的Rowkey划分)和基于哈希的划分。为了解决哈希分布式的单调性和平衡性问题,目前业内主要使用虚拟节点。后文所述的Codis也是用虚拟节点。虚拟节点相当于在数据分片和托管服务器之间建立了一层虚拟映射的关系。
目前,大家主要根据数据模型和访问方式进行NoSQL分类。
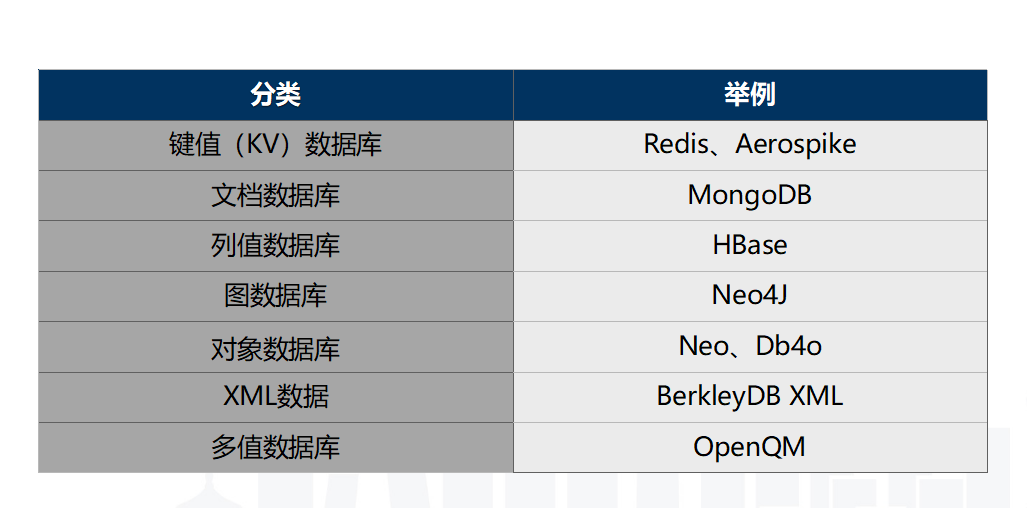
个推常用的几种NoSQL解决方案
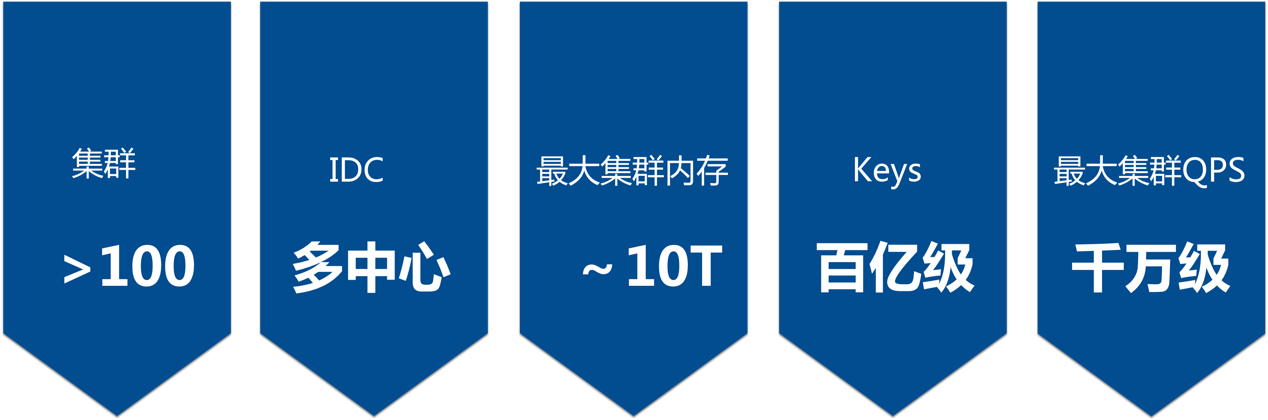
个推Redis系统规模如下图。下面介绍一下运维过程遇到的几个问题。
首先是技术架构演进过程。个推以面向APP开发者提供消息推送服务起家,在2012年之前,个推的业务量相对较小,当时我们用Redis做缓存,用MySQL做持久化。在2012-2016年,随着个推业务的高速发展,单节点已经无法解决问题。在MySQL无法解决高QPS、TPS的情况下,我们自研了Redis分片方案。此外,我们还自研了Redis客户端,用它来实现基本的集群功能,支持自定义读写比例,同时对故障节点的监测和隔离、慢监控以及每个节点健康性进行检查。但这种架构没有过多考虑运维效率的问题,缺少运维工具。
当我们计划完善运维工具的时候,发现豌豆荚团队将Codis开源,给我们提供了一个不错的选项。
个推Codis+的优势
Codis是proxy-based架构,支持原生客户端,支持基于web的集群操作和监控,并且也集成了Redis Sentinel。可以提高我们运维的工作效率,且HA也更容易落地。
但是在使用过程中,我们也发现一些局限。因此我们提出了Codis+,即对Codis做一些功能增强。
第一、 采用2N+1副本方案,解决故障期间Master单点的问题。
第二、Redis准半同步。设置一个阈值,比如slave仅在5秒钟之内可读。
第三、资源池化。能通过类似HBase增加RegionServer的方式去进行资源扩容。
此外,还有机架感知功能和跨IDC的功能。Redis本身是为了单机房而设置的,没有考虑到这些问题。
那么,为什么我们不用原生的rRedis cluster?这里有三个原因:一、原生的集群,它把路由转发的功能和实际上的数据管理功能耦合在一个功能里,如果一个功能出问题就会导致数据有问题;二、在大集群时,P2P的架构达到一致性状态的过程比较耗时,codis是树型架构,不存在这个问题。三、集群没有经过大平台的背书。
此外,关于Redis,我们最近还在看一个新的NoSQL方案Aerospike,我们对它的定位是替换部分集群Redis。Redis的问题在于数据常驻内存,成本很高。我们期望利用Aerospike减少TCO成本。Aerospike有如下特性:
一、Aerospike数据可以放内存,也可以放SSD,并对SSD做了优化。
二、资源池化,运维成本继续降低。
三、支持机架感知和跨IDC的同步,但这属于企业级版本功能。
目前我们内部现在有两个业务在使用Aerospike,实测下来,发现单台物理机搭载单块Inter SSD 4600,可以达到接近10w的QPS。对于容量较大,但QPS要求不高的业务,可以选择Aerospike方案节省TCO。
在NoSQL演进的过程中,我们也遇到一些运维方面的问题。
标准化安装
我们共分了三个部分:OS标准化、Redis文件和目录标准、Redis参数标准化,全部用saltstack + cmdb实现;
扩容和缩容
在技术架构不断演进过程中,扩容和缩容的难度也在变低,原因之一在于codis缓解了一部分问题。当然,如果选择Aerospike,相关操作就会非常轻松。
做好监控,降低运维成本
大部分的运维同学都应该认真阅读《SRE:Google运维揭秘》,它在理论层面和实践层面提出了很多非常有价值的方法论,强烈推荐。
个推Redis监控复杂性
三种集群架构:自研、codis2和codis3,这三种架构采集数据的方式并不相同。
三类监控对象:集群、实例、主机,需要有元数据维护逻辑关系,并在全局做聚合。
三种个性化配置:个推的Redis集群,有的集群需要有多副本,有的不需要。有的节点允许满做缓存,有的节点不允许满。还有持久化策略,有的不做持久化,有的做持久化,有的做持久化+异地备份,这些业务特点对我们监控灵活性提出很高的要求。
Zabbix是一个非常完备的监控系统,约三年多的时间里,我都把它作为主要的监控系统平台。但是它有两个缺陷:一是它使用MySQL作为后端存储,TPS有上限;二是不够灵活。比如:一个集群放在一百台机器上,要做聚合指标,就很困难。
小米的open-falcon解决了这个问题,但是也会产生一些新问题。比如告警函数很少,不支持字符串,有时候会增加手工的操作等等。后来我们对它进行功能性补充,便没有遇到大的问题。
下图是个推运维平台。
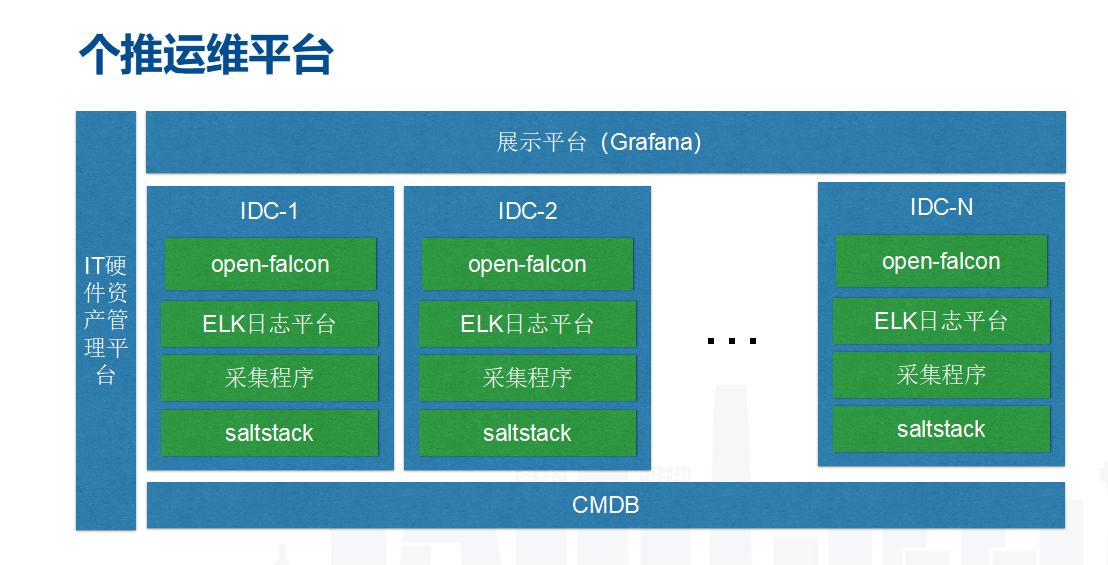
第一个是IT硬件资源平台,主要维护主机维度的物理信息。比如说主机在哪个机架上接的哪个交换机,在哪个机房的哪一个楼层等等,这是做机架感知和跨IDC等等的基础。
第二个是CMDB,这个是维护主机上的软件信息,主机上装了哪些实例,实例属于哪些集群,我们用了哪些端口,这些集群有什么个性化的参数配置,包括告警机制不一样,全是通过CMDB实现。CMDB的数据消费方包含grafana监控系统和监控采集程序,采集程序由我们自己开发。这样CMDB数据会活起来。如果只是一个静态数据没有消费方,数据就会不一致。
grafana监控系统聚合了多个IDC数据,我们运维每天只需看一下大屏就够了。
Slatstack,用于实现自动化发布,实现标准化并提高工作效率。
采集程序是我们自行研发的,针对公司的业务特点定制化程度很高。还有ELK(不用logstach,用filebeat)做日志中心。
通过以上这些,我们搭建出个推整个监控体系。
下面讲一下搭建过程中遇到的几个坑。
一、主从重置,会导致主机节点压力爆增,主节点无法提供服务。
主从重置有很多原因。
Redis版本低,主从重置的概率很高。Redis3主从重置的概率比Redis2大大减少,Redis4支持节点重启以后也能增量同步,这是Redis本身进行了很多改进。
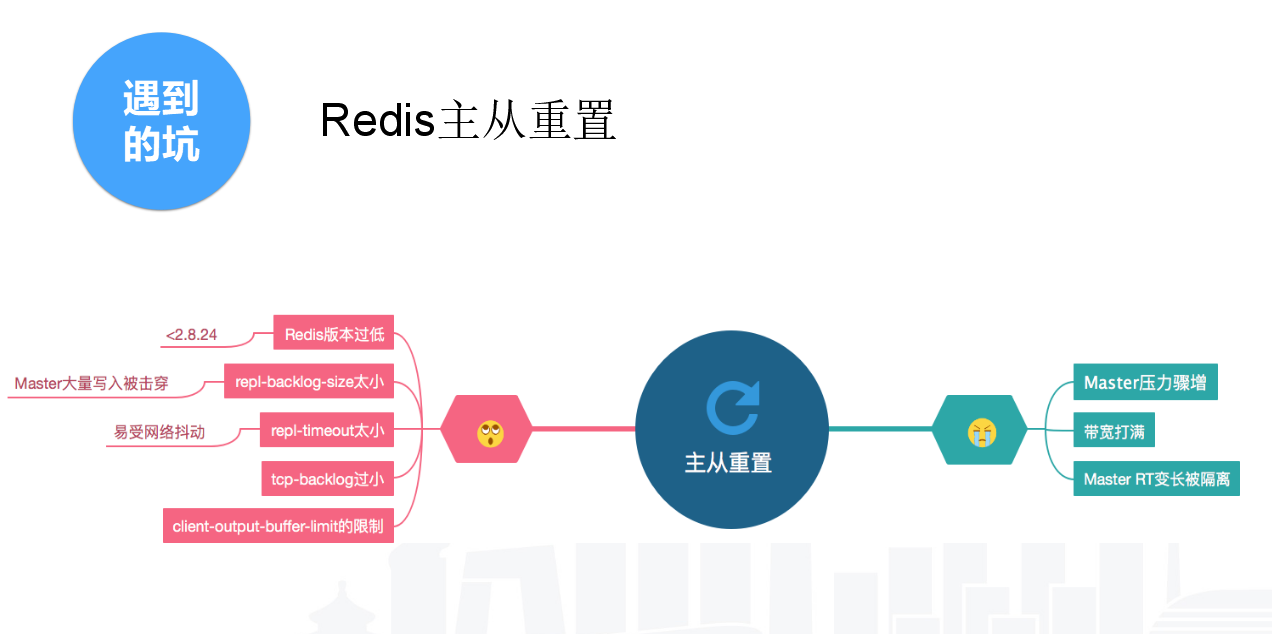
我们现在主要使用的是2.8.20,属于比较容易能产生主从重置。
Redis的主从重置一般是触发了如下条件中的一个。
1、repl-backlog-size太小,默认是1M,如果你有大量的写入,很容易击穿这个缓冲区;2、repl-timeout,Redis主从默认每十秒钟ping一次,60秒钟ping不推就会主从重置,原因可能是网络抖动、总节点压力过大,无法响应这个包等;3、tcp-baklog,默认是511。操作系统的默认是限制到128,这个可以适度提高,我们提高到2048,这个能对网络丢包现象进行一定容错。
以上都是导致主从重置的原因,主从重置的后果很严重。Master压力爆增无法提供服务,业务就把这个节点定为不可用。响应时间变长 Master所在所有主机的节点都会受到影响。
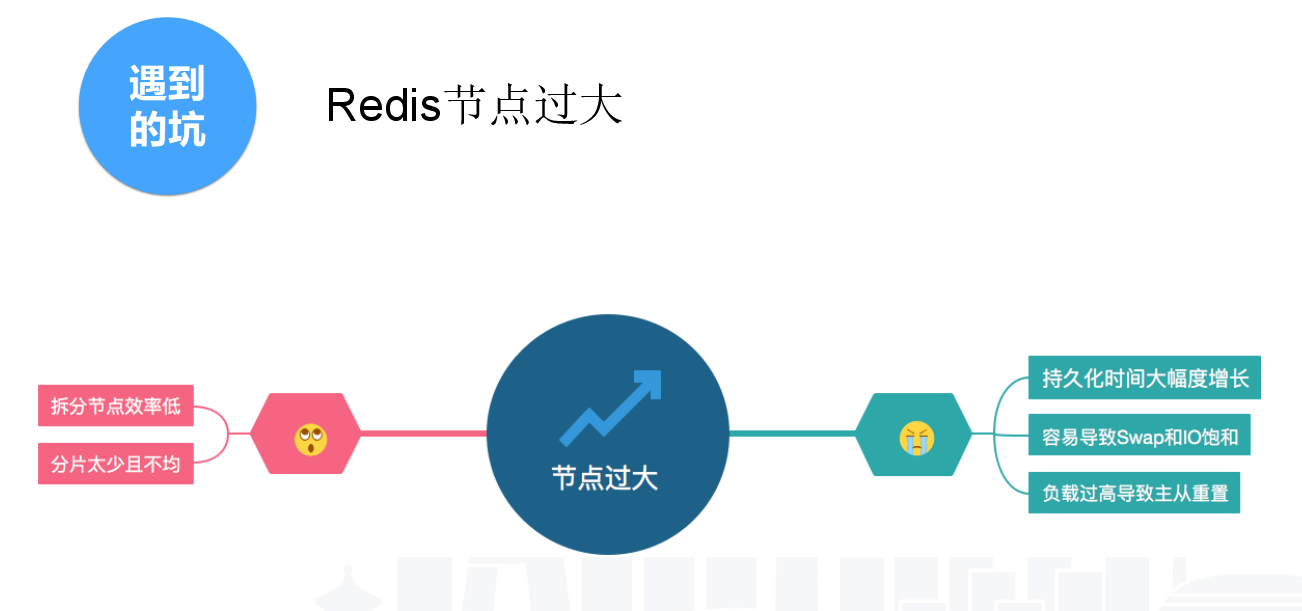
二、节点过大,部分是人为原因造成的。第一是拆分节点的效率较低,远远慢于公司业务量的增长。此外,分片太少。我们的分片是500个,codis是1024,codis原生是16384个,分片太少也是个问题。如果做自研的分布式方案,大家一定要把分片数量,稍微设大一点,避免业务发展超过你预期的情况。节点过大之后,会导致持久化的时间增长。我们30G的节点要持久化,主机剩余内存要大于30G,如果没有,你用Swap导致主机持久化时间大幅增长。一个30G的节点持久化可能要4个小时。负载过高也会导致主从重置,引起连锁反应。
关于我们遇到的坑,接下来分享几个实际的案例。
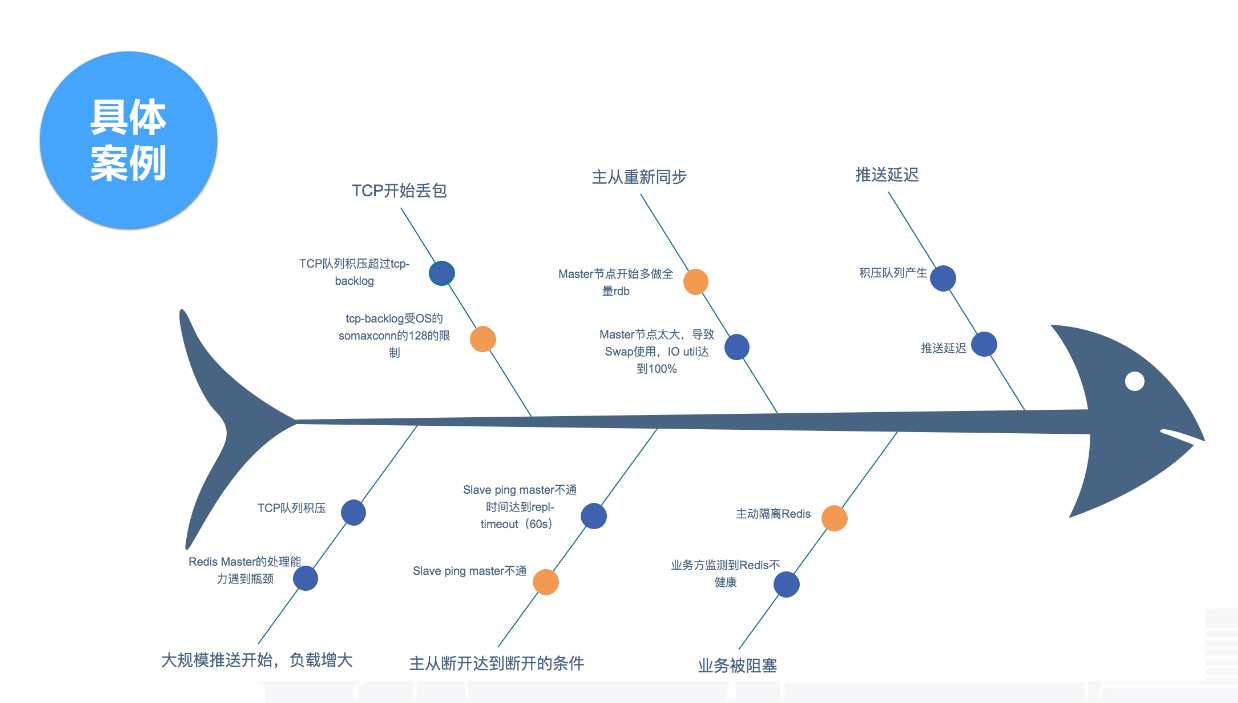
第一个案例是一次主从重置。这个情况是在春节前两天出现的,春节前属于消息推送业务高峰期。我们简单还原一下故障场景。首先是大规模的消息下发导致负载增加;然后,Redis Master压力增大,TCP包积压,OS产生丢包现象,丢包把Redis主从ping的包给丢了,触发了repl-timeout 60秒的阈值,主从就重置了。同时由于节点过大,导致Swap和IO饱和度接近100%。解决的方法很简单,我们先把主从断开。故障原因首先是参数不合理,大都是默认值,其次是节点过大让故障效果进行放大。
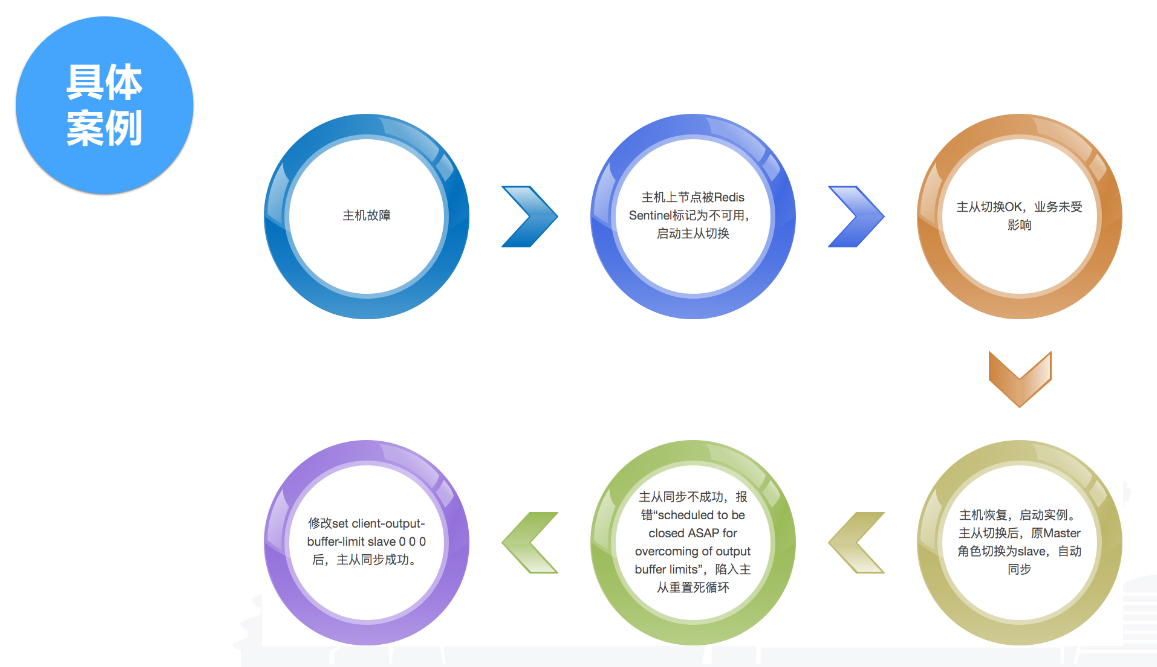
第二个案例是codis最近遇到的一个问题。这是一个典型的故障场景。一台主机挂掉后,codis开启了主从切换,主从切换后业务没有受影响,但是我们去重新接主从时发现接不上,接不上就报了错。这个错也不难查,其实就是参数设置过小,也是由于默认值导致。Slave从主节点拉数据的过程中,新增数据留在Master缓冲区,如果Slave还没拉完,Master缓冲区就超过上限,就会导致主从重置,进入一个死循环。
基于这些案例,我们整理了一份最佳实践。

一、配置CPU亲和。Redis是单机点的结构,不亲和会影响CPU的效率。
二、节点大小控制在10G。
三、主机剩余内存最好大于最大节点大小+10G。主从重置需要有同等大小的内存,这个一定要留够,如果不留够,用了Swap,就很难重置成功。
四、尽量不要用Swap。500毫秒响应一个请求还不如挂掉。
五、tcp-backlog、repl-backlog-size、repl-timeout适度增大。
六、Master不做持久化,Slave做AOF+定时重置。
最后是个人的一些思考和建议。选择适合自己的NoSQL,选择原则有五点:
1、业务逻辑。首先要了解自身业务特点,比如是KV型就在KV里面找;如果是图型就在图型里找,这样范围一下会减少70%-80%。
2、负载特点,QPS、TPS和响应时间。在选择NoSQL方案时,可以从这些指标去衡量,单机在一定配置下的性能指标能达到多少?Redis在主机足够剩余情况下,单台的QPS40-50万是完全OK的。
3、数据规模。数据规模越大,需要考虑的问题就越多,选择性就越小。到了几百个TB或者PB级别,几乎没太多选择,就是Hadoop体系。
4、运维成本和可不可监控,能否方便地进行扩容、缩容。
5、其它。比如有没有成功案例,有没有完善的文档和社区,有没有官方或者企业支持。可以让别人把坑踩过之后我们平滑过去,毕竟自己踩坑的成本还是蛮高的。
结语:关于NoSQL的释义,网络上曾有一个段子:从1980年的know SQL,到2005年的Not only SQL,再到今日的No SQL!互联网的发展伴随着技术概念的更新与相关功能的完善。而技术进步的背后,则是每一位技术人的持续的学习、周密的思考与不懈的尝试。
原文链接:https://my.oschina.net/u/1782938/blog/1812240
标签:redis。 数据 压力 最好 关于我 相关 内容 hba rdbms
原文地址:https://www.cnblogs.com/qixidi/p/10260134.html