最后
关注公众号:七夜安全博客

- 回复【1】:领取 Python数据分析 教程大礼包
- 回复【2】:领取 Python Flask 全套教程
- 回复【3】:领取 某学院 机器学习 教程
- 回复【4】:领取 爬虫 教程
- 回复【5】:领取 编译原理 教程
- 回复【6】:领取 渗透测试 教程
- 回复【7】:领取 人工智能数学基础 教程
标签:系统 语言 trace tcp 网络流 无法 令行 应用 命令行
原文地址:https://www.cnblogs.com/qiyeboy/p/10262441.html
标签:系统 语言 trace tcp 网络流 无法 令行 应用 命令行
在上一篇中,我们讲解了哈勃沙箱的技术点,详细分析了静态检测和动态检测的流程。本篇接着对动态检测的关键技术点进行分析,包括strace,sysdig,volatility。volatility的介绍不会太深入,内存取证这部分的研究还需要继续。
上一篇讲到了strace和ltrace都是基于ptrace机制,但是对ptrace机制和strace/ltrace是如何利用ptrace监控系统调用,没有进行详细的讲解。
那什么是ptrace机制呢?
ptrace机制是操作系统提供了一种标准的服务来让程序员实现对底层硬件和服务的控制。
当一个程序需要作系统调用的时候,它将相关参数放进系统调用相关的寄存器,然后调用软中断0x80,这个中断就像一个让程序得以接触到内核模式的窗口,程序将参数和系统调用号交给内核,内核来完成系统调用的执行。
ptrace会在什么时候出现呢?
在执行系统调用之前,内核会先检查当前进程是否处于被“跟踪”(traced)的状态。如果是的话,内核暂停当前进程并将控制权交给跟踪进程,使跟踪进程得以察看或者修改被跟踪进程的寄存器。
strace监控系统调用
下面就以strace为例,如下图所示,在第2步和第3步是关键。
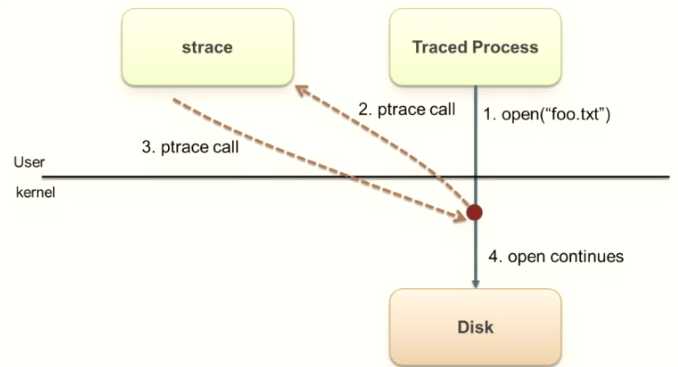
strace使用ptrace机制来检测目标进程并“监听”该进程的系统调用,strace可以在每次调用系统调用时中断跟踪的进程,捕获调用,解码它,然后继续执行跟踪的进程。
大家可能知道,每次调用系统调用(例如,打开,读取,写入,关闭)时,都需要从用户级别到内核级别的转换 - 这称为上下文切换。这取决于CPU系列和型号,以不同的方式实现,但它往往复杂且相对较慢。
sysdig是一个开源系统发掘工具,用于系统级别的勘察和排障,可以看作system(系统)+dig(挖掘)的组合。我们可以把它看作一系列传统的 unix 系统工具的组合,主要包括:
strace:追踪某个进程产生和接收的系统调用。
tcpdump:分析网络数据,监控原始网络通信。
lsof: 列出打开的文件。
top:监控系统性能工具。
htop :交互式的进程浏览器,可以用来替换 top 命令。
iftop :主要用来显示本机网络流量情况及各相互通信的流量集合。
lua:一个小巧的脚本语言。该语言的设计目的是为了嵌入应用程序中,从而为应用程序提供灵活的扩展和定制功能。
sysdig工作方式分成用户空间和内核空间两个部分,结构如下图所示(附件画图画的):
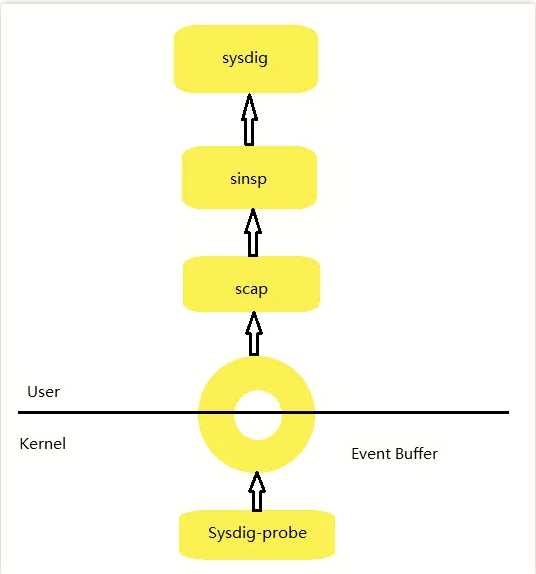
数据的捕获流程分为如下5部分:
在内核有一个组件叫 sysdig-probe,也可以把它称为数据探头,它通过跟踪 linux 内核来进行数据抓获。
事件缓冲器(event buffer)用来把存储器映射到用户空间。
scap 组件:用来进行捕获控制和转储文件,以及数据的状态采集。
sinsp 组件:用来进行事件分析、执行凿子(chisel),设置过滤和输出格式化。
最后 sysdig 工具在命令行解析采集的数据。
从整体架构上来看,sysdig与libpcap / tcpdump / wireshark的架构非常相似,都是先捕获大量的数据,然后使用过滤器获取自己想要的数据。
希望大家注意到一个问题, sysdig-probe从内核捕获的数据会非常大的,用户空间里的scap,sinsp,sysdig组件能处理过来吗?假如处理不过来,sysdig会采用什么机制呢?sysdig会像strace一样放慢程序速度吗?
答案是否定的。在这种情况下,事件缓冲区填满,sysdig-probe开始丢弃传入的事件。因此,将丢失一些跟踪信息,但机器上运行的其他进程不会减慢速度,这是sysdig架构的关键优势,意味着跟踪开销可预测。既然sysdig这么强大,下面讲解一下sysdig的基本用法。
sysdig 基本用法
我以ubuntu系统中的操作为例,直接在shell输入sudo sysdig 就能开始捕获系统信息,执行后你会看到终端有持续不断的输出流。
$ sudo sysdig
因为系统每时每刻都有大量的系统调用产生,这样是没办法看清更无法分析输出信息的,可以先使用 ctrl + c 来退出命令。输出如下图所示:
先来解释一下它的输出格式:
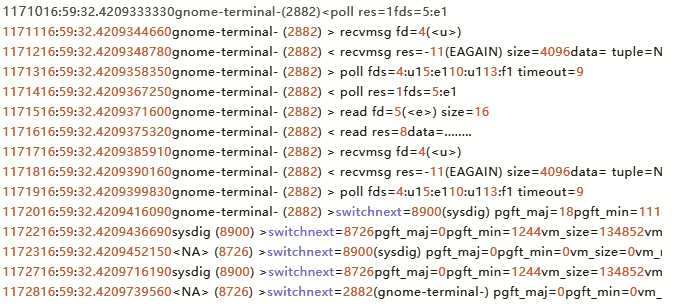
所有的输入都是按照行来分割的,每行都是一条记录,由多个列组成,默认的格式是:
%evt.num %evt.outputtime %evt.cpu %proc.name (%thread.tid) %evt.dir %evt.type %evt.info
各个字段的含义如下:
evt.num: 递增的事件号
evt.time: 事件发生的时间
evt.cpu: 事件被捕获时所在的 CPU,也就是系统调用是在哪个 CPU 执行的。比较上面的例子中,值 0 代表机器的第一个 CPU
proc.name: 生成事件的进程名字,也就是哪个进程在运行
thread.tid: 线程的 id,如果是单线程的程序,这也是进程的 pid
evt.dir: 事件的方向(direction),> 代表进入事件,< 代表退出事件
evt.type: 事件的名称,比如 open、stat等,一般是系统调用
evt.args: 事件的参数。如果是系统调用,这些对应着系统调用的参数
过滤
完整的 sysdig 使用方法:
sysdig [option]... [filter]
sysdig 的过滤功能很强大,不仅支持的过滤项很多,而且还能够自由地进行逻辑组合。
过滤项
sysdig 的过滤器也是分成不同类别的,比如:
fd: 对文件描述符(file descriptor)进行过滤,比如 fd 标号(fd.num)、fd 名字(fd.name)
process: 进程信息的过滤,比如进程 id(proc.id)、进程名(proc.name)
evt: 事件信息的过滤,比如事件编号、事件名
user: 用户信息的过滤,比如用户 id、用户名、用户 home 目录、用户的登录 shell(user.shell)
syslog: 系统日志的过滤,比如日志的严重程度、日志的内容
fdlist: poll event 的文件描述符的过滤
完整的过滤器列表可以使用sysdig -l来查看,比如可以查看建立 TCP 连接的事件:
sudo sysdig evt.type=accept
过滤器组合
过滤器除了直接的相等比较之外,还有其他操作符,包括=、!=、>=、>、<、<=、contains、in 和 exists,
比如:
$ sysdig fd.name contains /etc
$ sysdig "evt.type in ( ‘select‘, ‘poll‘ )"
$ sysdig proc.name exists
多个过滤条件还可以通过 and、or 和 not 进行逻辑组合,比如:
$ sysdig "not (fd.name contains /proc or fd.name contains /dev)"
到这发现已经写了4千多字,volatility这里简要描述一下,详细的分析,等我之后对内存取证有了一个整体的框架再说。
Volatility是一个Python编写的跨平台,用于内存分析的法证工具,其目的是为了在数据犯罪中提取易失性数据 ,也可以用来进行Rootkit的检测和协助清除。Volatility分析主要依赖的是profile文件,profile文件是由两部分合成。以linux为例,大致如下:
Linux的System.map文件列出了详细的系统调用(syscall),而kernel-header源码通过dwarfdump生成的module.dwarf文件中会包含很多内核数据结构,将以上2个文件打包为profile文件。
再用这个profile文件解析dump下来的物理内存,就很容易找到植入Rootkit的机器活动时的进程(linux_psaux)、网络通信(linux_netstat)、活动文件(linux_lsof)、驱动模块(linux_lsmod)等等
关注公众号:七夜安全博客
标签:系统 语言 trace tcp 网络流 无法 令行 应用 命令行
原文地址:https://www.cnblogs.com/qiyeboy/p/10262441.html