标签:fun 打印 from none 使用 bin https 转化 pycha
urllib,urllib2是客户端http协议的实现,urllib2底层使用httplib,socket库,它主要包含urlopen, build_opener, install_opener等func。python2.7使用urllib2库中的urlopen会出现内存泄漏的现象,可以通过gc模块来视察内存泄漏情况。
# -*- coding: utf-8 -*-
#!usr/bin/python
import urllib2
import socket
import gc
# check memory on memory leaks
def get_unreachable_memory_len():
#当设置DEBUG_SAVEALL后,所有unreachable对象会append到garbage中,不会被销毁,从而进行视察,测试时使用。
gc.set_debug(gc.DEBUG_SAVEALL)
gc.collect()
unreachableL = []
for it in gc.garbage:
unreachableL.append(it)
#print(str(it))
print str(unreachableL)
def task():
try:
req = urllib2.urlopen(‘http://www.baidu.com/‘, timeout=3)
text = req.read()
#req.fp._sock.recv = None
req.close()
except urllib2.HTTPError, e:
print e.code
except urllib2.URLError, e:
print e.reason
else:
print("urlopen success")
if __name__ == ‘__main__‘:
get_unreachable_memory_len()
print("-------------------------")
task()
print("-------------------------")
get_unreachable_memory_len()
运行程序确定urlopen存在内存泄漏:
python垃圾回收机制基于对象的引用计数,所以先找到造成循环引用的代码。采用objgraph模块打印出增加的对象。示例代码如下:
# -*- coding: utf-8 -*-
#!usr/bin/python
import urllib2
import socket
import gc
import objgraph
# check memory on memory leaks
def get_unreachable_memory_len():
#当设置DEBUG_SAVEALL后,所有unreachable对象会append到garbage中,不会被销毁,从而进行视察,测试时使用。
gc.set_debug(gc.DEBUG_SAVEALL)
gc.collect()
unreachableL = []
for it in gc.garbage:
unreachableL.append(it)
#print(str(it))
print str(unreachableL)
def task():
try:
req = urllib2.urlopen(‘http://www.baidu.com/‘, timeout=3)
text = req.read()
#req.fp._sock.recv = None
req.close()
except urllib2.HTTPError, e:
print e.code
except urllib2.URLError, e:
print e.reason
else:
print("urlopen success")
#class HTTPResponse(object):
# pass
if __name__ == ‘__main__‘:
gc.set_debug(gc.DEBUG_SAVEALL)
objgraph.show_growth()
print("-------------------------")
for i in range(5):
task()
print("-------------------------")
objgraph.show_growth()
看到引用计数加5的三个字段,以及观察到上一次运行结果首先出现的是httplib.HTTPResponse。
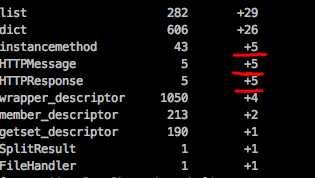
使用objgraph.show_backrefs对httplib.HTTPResponse进行分析:
# -*- coding: utf-8 -*-
#!usr/bin/python
import urllib2
import socket
import gc
import objgraph
# check memory on memory leaks
def get_unreachable_memory_len():
#当设置DEBUG_SAVEALL后,所有unreachable对象会append到garbage中,不会被销毁,从而进行视察,测试时使用。
gc.set_debug(gc.DEBUG_SAVEALL)
gc.collect()
unreachableL = []
for it in gc.garbage:
unreachableL.append(it)
#print(str(it))
print str(unreachableL)
def task():
try:
req = urllib2.urlopen(‘http://www.baidu.com/‘, timeout=3)
text = req.read()
#req.fp._sock.recv = None
req.close()
except urllib2.HTTPError, e:
print e.code
except urllib2.URLError, e:
print e.reason
else:
print("urlopen success")
#class HTTPResponse(object):
# pass
if __name__ == ‘__main__‘:
gc.set_debug(gc.DEBUG_SAVEALL)
print("-------------------------")
for i in range(5):
task()
print("-------------------------")
objgraph.show_backrefs(objgraph.by_type(‘HTTPResponse‘)[0], max_depth = 10, filename = ‘obj.dot‘)
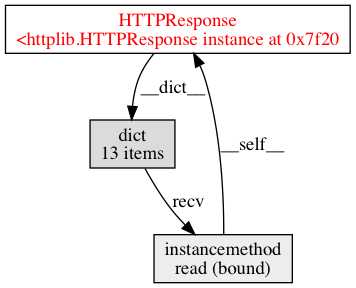
将生成的obj.dot转化为obj.png(使用命令dot obj.dot -Tpng -o obj.png)图示如下,记录下造成循环引用的recv引用和read方法。
查看urllib2类图可以使用pycharm自动生成UML类图,这里需要分析urllib2.urlopen的调用流程,可以引入pycallgraph模块来分析,示例代码入下:
# -*- coding: utf-8 -*-
#!usr/bin/python
import urllib2
import socket
import gc
from pycallgraph import PyCallGraph
from pycallgraph.output import GraphvizOutput
def task():
graphviz = GraphvizOutput()
graphviz.output_file = ‘urlopen.png‘
with PyCallGraph(output=graphviz):
try:
req = urllib2.urlopen(‘http://www.baidu.com/‘, timeout=3)
#text = req.read()
#req.fp._sock.recv = None
#req.close()
except urllib2.HTTPError, e:
print e.code
except urllib2.URLError, e:
print e.reason
else:
print("urlopen success")
if __name__ == ‘__main__‘:
task()
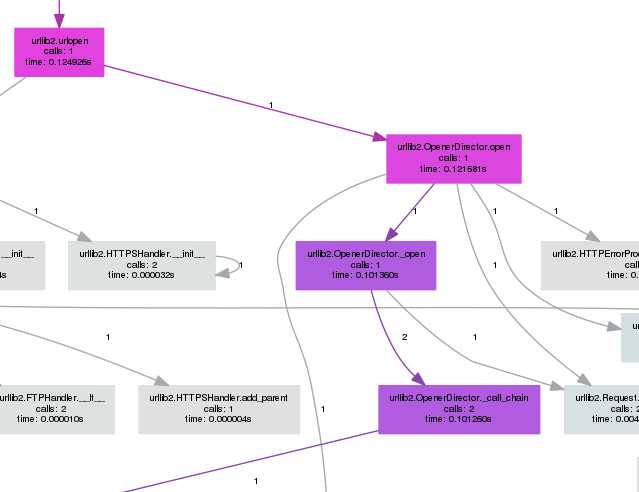
截取部分生成的调用流程图:
在HTTPHandler类中的do_open方法中有这一行代码:
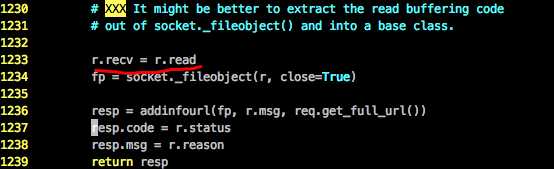
这个r指的是HTTPResopnse类,它只有read方法而没有recv方法,这个引用在urlopen调用结束后并没有释放。解决内存泄漏问题就需要消除改引用。
1)上述示例当中调用task()之后使用gc.collect()进行手动内存回收。
2)http连接close之前手动解决r.recv这个引用。
req = urllib2.urlopen(‘http://www.baidu.com/‘, timeout=3) text = req.read() #对于调用urlopen正常返回的情况手动解除r.recv = r.read这个引用 req.fp._sock.recv = None req.close()
注:当返回错误状态码urllib2.HTTPError时无法生效,需要修改urllib2.py源码为
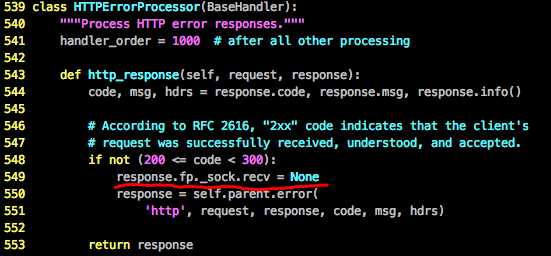
3)改用更底层的socket,httplib库。
参考资料:
1)http://python.jobbole.com/88827/
2)https://bugs.python.org/issue1208304
3)https://stackoverflow.com/questions/4214224/how-to-solve-python-memory-leak-when-using-urrlib2#
标签:fun 打印 from none 使用 bin https 转化 pycha
原文地址:https://www.cnblogs.com/anjike/p/10230302.html