标签:tab 无法 hash inf -- sum 自动 def 假设
在开始分析算法原理之前,简单说明下rsync的增量传输功能。
假设待传输文件为A,如果目标路径下没有文件A,则rsync会直接传输文件A,如果目标路径下已存在文件A,则发送端视情况决定是否要传输文件A。rsync默认使用"quick check"算法,它会比较源文件和目标文件(如果存在)的文件大小和修改时间mtime,如果两端文件的大小或mtime不同,则发送端会传输该文件,否则将忽略该文件。
如果"quick check"算法决定了要传输文件A,它不会传输整个文件A,而是只传源文件A和目标文件A所不同的部分,这才是真正的增量传输。
也就是说,rsync的增量传输体现在两个方面:文件级的增量传输和数据块级别的增量传输。文件级别的增量传输是指源主机上有,但目标主机上没有将直接传输该文件,数据块级别的增量传输是指只传输两文件所不同的那一部分数据。但从本质上来说,文件级别的增量传输是数据块级别增量传输的特殊情况。
假设执行的rsync命令是将A文件推到β主机上使得B文件和A文件保持同步,即主机α是源主机,是数据的发送端(sender),β是目标主机,是数据的接收端(receiver)。在保证B文件和A文件同步时,大致有以下6个过程:
(1).α主机告诉β主机文件A待传输。
(2).β主机收到信息后,将文件B划分为一系列大小固定的数据块(建议大小在500-1000字节之间),并以chunk号码对数据块进行编号,同时还会记录数据块的起始偏移地址以及数据块长度。显然最后一个数据块的大小可能更小。
对于文件B的内容"123abcdefg"来说,假设划分的数据块大小为3字节,则根据字符数划分成了以下几个数据块:
count=4 n=3 rem=1 这表示划分了4个数据块,数据块大小为3字节,剩余1字节给了最后一个数据块 chunk[0]:offset=0 len=3 该数据块对应的内容为123 chunk[1]:offset=3 len=3 该数据块对应的内容为abc chunk[2]:offset=6 len=3 该数据块对应的内容为def chunk[3]:offset=9 len=1 该数据块对应的内容为g
当然,实际信息中肯定是不会包括文件内容的。
(3).β主机对文件B的每个数据块根据其内容都计算两个校验码:32位的弱滚动校验码(rolling checksum)和128位的MD4强校验码(现在版本的rsync使用的已经是128位的MD5强校验码)。并将文件B计算出的所有rolling checksum和强校验码跟随在对应数据块chunk[N]后形成校验码集合,然后发送给主机α。
也就是说,校验码集合的内容大致如下:其中sum1为rolling checksum,sum2为强校验码。
chunk[0] sum1=3ef2c827 sum2=3efa923f8f2e7 chunk[1] sum1=57ac2aaf sum2=aef2dedba2314 chunk[2] sum1=92d7edb4 sum2=a6sd6a9d67a12 chunk[3] sum1=afe74939 sum2=90a12dfe7485c
需要注意,不同内容的数据块计算出的rolling checksum是有可能相同的,但是概率非常小。
(4).当α主机接收到文件B的校验码集合后,α主机将对此校验码集合中的每个rolling checksum计算16位长度的hash值,并将每216个hash值按照hash顺序放入一个hash table中,hash表中的每一个hash条目都指向校验码集合中它所对应的rolling checksum的chunk号码,然后对校验码集合根据hash值进行排序,这样排序后的校验码集合中的顺序就能和hash表中的顺序对应起来。
所以,hash表和排序后的校验码集合对应关系大致如下:假设hash表中的hash值是根据首个字符按照[0-9a-f]的顺序进行排序的。
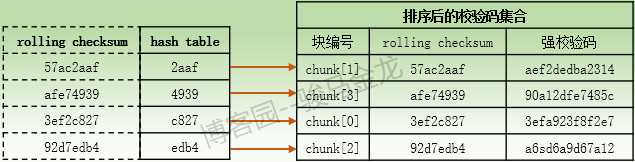
同样需要注意,不同rolling checksum计算出的hash值也是有可能会相同的,概率也比较小,但比rolling checksum出现重复的概率要大一些。
(5).随后主机α将对文件A进行处理。处理的过程是从第1个字节开始取相同大小的数据块,并计算它的校验码和校验码集合中的校验码进行匹配。如果能匹配上校验码集合中的某个数据块条目,则表示该数据块和文件B中数据块相同,它不需要传输,于是主机α直接跳转到该数据块的结尾偏移地址,从此偏移处继续取数据块进行匹配。如果不能匹配校验码集合中的数据块条目,则表示该数据块是非匹配数据块,它需要传输给主机β,于是主机α将跳转到下一个字节,从此字节处继续取数据块进行匹配。注意,匹配成功时跳过的是整个匹配数据块,匹配不成功时跳过的仅是一个字节。可以结合下一小节的示例来理解。
上面说的数据块匹配只是一种描述,具体的匹配行为需要进行细化。rsync算法将数据块匹配过程分为3个层次的搜索匹配过程。
首先,主机α会对取得的数据块根据它的内容计算出它的rolling checksum,再根据此rolling checksum计算出hash值。
然后,将此hash值去和hash表中的hash条目进行匹配,这是第一层次的搜索匹配过程,它比较的是hash值。如果在hash表中能找到匹配项,则表示该数据块存在潜在相同的可能性,于是进入第二层次的搜索匹配。
第二层次的搜索匹配是比较rolling checksum。由于第一层次的hash值匹配到了结果,所以将搜索校验码集合中与此hash值对应的rolling checksum。由于校验码集合是按照hash值排序过的,所以它的顺序和hash表中的顺序一致,也就是说只需从此hash值对应的rolling chcksum开始向下扫描即可。扫描过程中,如果A文件数据块的rolling checksum能匹配某项,则表示该数据块存在潜在相同的可能性,于是停止扫描,并进入第三层次的搜索匹配以作最终的确定。或者如果没有扫描到匹配项,则说明该数据块是非匹配块,也将停止扫描,这说明rolling checksum不同,但根据它计算的hash值却发生了小概率重复事件。
第三层次的搜索匹配是比较强校验码。此时将对A文件的数据块新计算一个强校验码(在第三层次之前,只对A文件的数据块计算了rolling checksum和它的hash值),并将此强校验码与校验码集合中对应强校验码匹配,如果能匹配则说明数据块是完全相同的,不能匹配则说明数据块是不同的,然后开始取下一个数据块进行处理。
之所以要额外计算hash值并放入hash表,是因为比较rolling checksum的性能不及hash值比较,且通过hash搜索的算法性能非常高。由于hash值重复的概率足够小,所以对绝大多数内容不同的数据块都能直接通过第一层次搜索的hash值比较出来,即使发生了小概率hash值重复事件,还能迅速定位并比较更小概率重复的rolling checksum。即使不同内容计算的rolling checksum也可能出现重复,但它的重复概率比hash值重复概率更小,所以通过这两个层次的搜索就能比较出几乎所有不同的数据块。假设不同内容的数据块的rolling checksum还是出现了小概率重复,它将进行第三层次的强校验码比较,它采用的是MD4(现在是MD5),这种算法具有"雪崩效应",只要一点点不同,结果都是天翻地覆的不同,所以在现实使用过程中,完全可以假设它能做最终的比较。
数据块大小会影响rsync算法的性能。如果数据块大小太小,则数据块的数量就太多,需要计算和匹配的数据块校验码就太多,性能就差,而且出现hash值重复、rolling checksum重复的可能性也增大;如果数据块大小太大,则可能会出现很多数据块都无法匹配的情况,导致这些数据块都被传输,降低了增量传输的优势。所以划分合适的数据块大小是非常重要的,默认情况下,rsync会根据文件大小自动判断数据块大小,但rsync命令的"-B"(或"--block-size")选项支持手动指定大小,如果手动指定,官方建议大小在500-1000字节之间。
(6).当α主机发现是匹配数据块时,将只发送这个匹配块的附加信息给β主机。同时,如果两个匹配数据块之间有非匹配数据,则还会发送这些非匹配数据。当β主机陆陆续续收到这些数据后,会创建一个临时文件,并通过这些数据重组这个临时文件,使其内容和A文件相同。临时文件重组完成后,修改该临时文件的属性信息(如权限、所有者、mtime等),然后重命名该临时文件替换掉B文件,这样B文件就和A文件保持了同步。
(1).rsync两端耗费计算机的什么资源比较严重?
从前文中已经知道,rsync的sender端因为要多次计算、多次比较各种校验码而对cpu的消耗很高,receiver端因为要从basis file中复制数据而对io的消耗很高。但这只是rsync增量传输时的情况,如果是全量传输(如第一次同步,或显式使用了全量传输选项"--whole-file"),那么sender端不用计算、比较校验码,receiver端不用copy basis file,这和scp消耗的资源是一样的。
(2).rsync不适合对数据库文件进行实时同步。
像数据库文件这样的大文件,且是频繁访问的文件,如果使用rsync实时同步,sender端要计算、比较的数据块校验码非常多,cpu会长期居高不下,从而影响数据库提供服务的性能。另一方面,receiver端每次都要从巨大的basis file(一般提供服务的数据库文件至少都几十G)中复制大部分相同的数据块重组新文件,这几乎相当于直接cp了一个文件,它一定无法扛住巨大的io压力,再好的机器也扛不住。
所以,对频繁改变的单个大文件只适合用rsync偶尔同步一次,也就是备份的功能,它不适合实时同步。像数据库文件,要实时同步应该使用数据库自带的replication功能。
(3).可以使用rsync对大量小文件进行实时同步。
由于rsync是增量同步,所以对于receiver端已经存在的和sender端相同的文件,sender端是不会发送的,这样就使得sender端和receiver端都只需要处理少量的文件,由于文件小,所以无论是sender端的cpu还是receiver端的io都不是问题。
但是,rsync的实时同步功能是借助工具来实现的,如inotify+rsync,sersync,所以这些工具要设置合理,否则实时同步一样效率低下,不过这不是rsync导致的效率低,而是这些工具配置的问题。
标签:tab 无法 hash inf -- sum 自动 def 假设
原文地址:https://www.cnblogs.com/zywu-king/p/10265202.html