标签:join 返回 daemon col %s 进程资源 list 系统 弊端
一.什么是线程

#指的是一条流水线的工作过程,关键的一句话:一个进程内最少自带一个线程,其实进程根本不能执行,进程不是执行单位,是资源的单位,分配资源的单位 #线程才是执行单位 #进程:做手机屏幕的工作过程,刚才讲的 #我们的py文件在执行的时候,如果你站在资源单位的角度来看,我们称为一个主进程,如果站在代码执行的角度来看,它叫做主线程,只是一种形象的说法,其实整个代码的执行过程成为线程,也就是干这个活儿的本身称为线程,但是我们后面学习的时候,我们就称为线程去执行某个任务,其实那某个任务的执行过程称为一个线程,一条流水线的执行过程为线程 #进程vs线程 #1 同一个进程内的多个线程是共享该进程的资源的,不同进程内的线程资源肯定是隔离的 #2 创建线程的开销比创建进程的开销要小的多 #并发三个任务:1启动三个进程:因为每个进程中有一个线程,但是我一个进程中开启三个线程就够了 #同一个程序中的三个任务需要执行,你是用三个进程好 ,还是三个线程好? #例子: # pycharm 三个任务:键盘输入 屏幕输出 自动保存到硬盘 #如果三个任务是同步的话,你键盘输入的时候,屏幕看不到 #咱们的pycharm是不是一边输入你边看啊,就是将串行变为了三个并发的任务 #解决方案:三个进程或者三个线程,哪个方案可行。如果是三个进程,进程的资源是不是隔离的并且开销大,最致命的就是资源隔离,但是用户输入的数据还要给另外一个进程发送过去,进程之间能直接给数据吗?你是不是copy一份给他或者通信啊,但是数据是同一份,我们有必要搞多个进程吗,线程是不是共享资源的,我们是不是可以使用多线程来搞,你线程1输入的数据,线程2能不能看到,你以后的场景还是应用多线程多,而且起线程我们说是不是很快啊,占用资源也小,还能共享同一个进程的资源,不需要将数据来回的copy!
进程有很多优点,它提供了多道编程,让我们感觉我们每个人都拥有自己的CPU和其他资源,可以提高计算机的利用率。很多人就不理解了,既然进程这么优秀,为什么还要线程呢?其实,仔细观察就会发现进程还是有很多缺陷的,主要体现在两点上:
进程只能在一个时间干一件事,如果想同时干两件事或多件事,进程就无能为力了。
进程在执行的过程中如果阻塞,例如等待输入,整个进程就会挂起,即使进程中有些工作不依赖于输入的数据,也将无法执行。
如果这两个缺点理解比较困难的话,举个现实的例子也许你就清楚了:如果把我们上课的过程看成一个进程的话,那么我们要做的是耳朵听老师讲课,手上还要记笔记,脑子还要思考问题,这样才能高效的完成听课的任务。而如果只提供进程这个机制的话,上面这三件事将不能同时执行,同一时间只能做一件事,听的时候就不能记笔记,也不能用脑子思考,这是其一;如果老师在黑板上写演算过程,我们开始记笔记,而老师突然有一步推不下去了,阻塞住了,他在那边思考着,而我们呢,也不能干其他事,即使你想趁此时思考一下刚才没听懂的一个问题都不行,这是其二。
现在你应该明白了进程的缺陷了,而解决的办法很简单,我们完全可以让听、写、思三个独立的过程,并行起来,这样很明显可以提高听课的效率。而实际的操作系统中,也同样引入了这种类似的机制——线程。
二.线程的出现
60年代,在OS中能拥有资源和独立运行的基本单位是进程,然而随着计算机技术的发展,进程出现了很多弊端,一是由于进程是资源拥有者,创建、撤消与切换存在较大的时空开销,因此需要引入轻型进程;二是由于对称多处理机(SMP)出现,可以满足多个运行单位,而多个进程并行开销过大。
在传统操作系统中,每个进程有一个地址空间,而且默认就有一个控制线程
线程顾名思义,就是一条流水线工作的过程,一条流水线必须属于一个车间,一个车间的工作过程是一个进程
车间负责把资源整合到一起,是一个资源单位,而一个车间内至少有一个流水线
流水线的工作需要电源,电源就相当于cpu
所以,进程只是用来把资源集中到一起(进程只是一个资源单位,或者说资源集合),而线程才是cpu上的执行单位。
多线程(即多个控制线程)的概念是,在一个进程中存在多个控制线程,多个控制线程共享该进程的地址空间,相当于一个车间内有多条流水线,都共用一个车间的资源。
例如,北京地铁与上海地铁是不同的进程,而北京地铁里的13号线是一个线程,北京地铁所有的线路共享北京地铁所有的资源,比如所有的乘客可以被所有线路拉。
三.线程与进程的关系
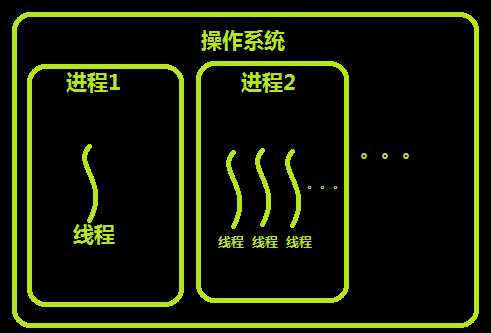
线程与进程的区别可以归纳为以下4点:
TCB包括以下信息: (1)线程状态。 (2)当线程不运行时,被保存的现场资源。 (3)一组执行堆栈。 (4)存放每个线程的局部变量主存区。 (5)访问同一个进程中的主存和其它资源。 用于指示被执行指令序列的程序计数器、保留局部变量、少数状态参数和返回地址等的一组寄存器和堆栈。
2)独立调度和分派的基本单位。
1 from threading import Thread 2 # def f1(n): 3 # print(‘xx%s‘%n) 4 # 5 # 6 # def f2(n): 7 # print(‘ss%s‘%n) 8 # 9 # 10 # if __name__ == ‘__main__‘: 11 # t = Thread(target=f1,args=(1,)) 12 # t1 = Thread(target=f2,args=(2,)) 13 # t.start() 14 # t1.start() 15 16 # 第二种创建方式 17 class Mythread(Thread): 18 19 20 def run(self): 21 print(‘哈哈哈‘) 22 23 24 if __name__ == ‘__main__‘: 25 t = Mythread() 26 t.start()
六.多进程和多线程的效率对比
1 import time 2 from threading import Thread 3 from multiprocessing import Process 4 5 def f1(): 6 # time.sleep(1) # io密集型 有阻塞 7 # 计算型: 无阻塞 8 n = 10 9 for i in range(10000000): 10 n = n + i 11 12 if __name__ == ‘__main__‘: 13 # 查看一下20个线程执行20个任务的执行时间 14 t_s_time = time.time() 15 t_list = [] 16 for i in range(20): 17 t =Thread(target=f1,) 18 t.start() 19 t_list.append(t) 20 21 [tt.join() for tt in t_list] 22 23 t_e_time = time.time() 24 25 t_dif_time = t_e_time - t_s_time 26 # 查看一下20个进程执行同样的任务的执行时间 27 p_s_time = time.time() 28 p_list = [] 29 for i in range(20): 30 p = Process(target=f1,) 31 p.start() 32 p_list.append(p) 33 34 [pp.join() for pp in p_list] 35 36 p_e_time = time.time() 37 38 p_dif_time = p_e_time - p_s_time 39 40 print(‘多线程时间:‘,t_dif_time) 41 print(‘多进程时间:‘,p_dif_time) 42 43 44 # 计算型 多线程比多进程费时间 45 # io密集型 多线程比多进程省时间
七.线程锁
1.锁
1 import time 2 from threading import Lock,Thread 3 4 num = 100 5 def f1(loc): 6 loc.acquire() 7 global num 8 tmp = num 9 tmp -= 1 10 time.sleep(0.00001) 11 num = tmp 12 loc.release() 13 14 if __name__ == ‘__main__‘: 15 t_loc = Lock() 16 t_list = [] 17 for i in range(10): 18 t = Thread(target=f1,args=(t_loc,)) 19 t.start() 20 t_list.append(t) 21 [tt.join() for tt in t_list] 22 print(‘主线成的num:‘,num)
2.死锁
进程也有死锁与递归锁,在进程那里忘记说了,放到这里一切说了额,进程的死锁和线程的是一样的,而且一般情况下进程之间是数据不共享的,不需要加锁,由于线程是对全局的数据共享的,所以对于全局的数据进行操作的时候,要加锁。
所谓死锁: 是指两个或两个以上的进程或线程在执行过程中,因争夺资源而造成的一种互相等待的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程,如下就是死锁
import time from threading import Thread,Lock def f1(locA,locB): locA.acquire() print(‘f1>>>1号抢到了A锁‘) time.sleep(1) locB.acquire() print(‘f1>>>1号抢到了B锁‘) locB.release() locA.release() def f2(locA,locB): locB.acquire() print(‘f2>>>2号抢到了A锁‘) time.sleep(1) locA.acquire() print(‘f2>>>2号抢到了B锁‘) locA.release() locB.release() if __name__ == ‘__main__‘: locA = locB = Lock() t1 = Thread(target=f1,args=(locA,locB)) t2 = Thread(target=f2,args=(locA,locB)) t1.start() t2.start()
解决方案使用递归锁
1 import time 2 from threading import Thread,RLock 3 4 def f1(locA,locB): 5 locA.acquire() 6 print(‘f1>>>1号抢到了A锁‘) 7 time.sleep(1) 8 locB.acquire() 9 print(‘f1>>>1号抢到了B锁‘) 10 locB.release() 11 locA.release() 12 def f2(locA,locB): 13 locB.acquire() 14 print(‘f2>>>2号抢到了A锁‘) 15 time.sleep(1) 16 locA.acquire() 17 # time.sleep(1) 18 print(‘f2>>>2号抢到了B锁‘) 19 locA.release() 20 locB.release() 21 22 if __name__ == ‘__main__‘: 23 locA = locB = RLock() 24 25 #locA = locB = RLock() # 递归锁,维护一个计数器,acquire一次就加1,release就减1 26 t1 = Thread(target=f1,args=(locA,locB)) 27 t2 = Thread(target=f2,args=(locA,locB)) 28 t1.start() 29 t2.start()
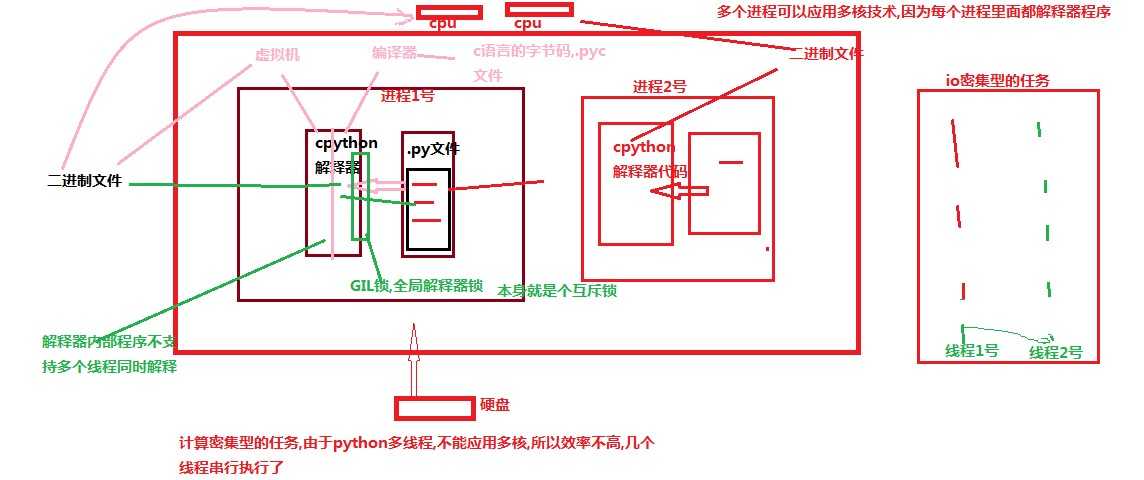
3.GIL锁
八.守护线程
1 import time 2 from threading import Thread 3 4 def f1(): 5 time.sleep(2) 6 print(‘1号线程‘) 7 8 def f2(): 9 time.sleep(3) 10 print(‘2号线程‘) 11 12 13 if __name__ == ‘__main__‘: 14 t1 = Thread(target=f1,) 15 t2 = Thread(target=f2,) 16 t1.daemon = True 17 # t2.daemon = True 18 t1.start() 19 t2.start() 20 print(‘主线程结束‘)
守护线程or守护进程区别
1 import time 2 from threading import Thread 3 from multiprocessing import Process 4 5 # 守护进程: 主进程代码执行运行结束,守护进程随之结束 6 7 # 守护线程:守护线程会等待所有非守护线程运行结束才结束 8 9 def f1(s): 10 time.sleep(2) 11 print(‘1号%s‘%s) 12 13 def f2(s): 14 time.sleep(3) 15 print(‘2号%s‘%s) 16 17 if __name__ == ‘__main__‘: 18 # 多线程 19 # t1 = Thread(target=f1,args=(‘线程‘,)) 20 # t2 = Thread(target=f2,args=(‘线程‘,)) 21 # t1.daemon = True # 守护线程 22 # # t2.daemon = True # 守护线程 23 # t1.start() 24 # t2.start() 25 # print(‘主线程结束‘) 26 27 # 多进程 28 t1 = Process(target=f1,args=(‘进程‘,)) 29 t2 = Process(target=f2,args=(‘进程‘,)) 30 # t1.daemon = True 31 t2.daemon = True 32 t1.start() 33 t2.start() 34 print(‘主进程结束‘)
守护线程:等待所有非守护线程的结束才结束
守护进程:主进程代码运行结束,守护进程就随之结束
标签:join 返回 daemon col %s 进程资源 list 系统 弊端
原文地址:https://www.cnblogs.com/beargod/p/10268270.html
