标签:uda stdio.h gettime 矩阵乘法 循环 方程组 sizeof 内存 evb
特别说明:要在我的随笔后写评论的小伙伴们请注意了,我的博客开启了 MathJax 数学公式支持,MathJax 使用
$标记数学公式的开始和结束。如果某条评论中出现了两个$,MathJax 会将两个$之间的内容按照数学公式进行排版,从而导致评论区格式混乱。如果大家的评论中用到了$,但是又不是为了使用数学公式,就请使用\$转义一下,谢谢。
想从头阅读该系列吗?下面是传送门:
科学计算碰到数据量很大的时候,往往非常消耗时间。使用多核进行并行计算是加快计算速度的主要方法,而显卡天生具有成百上千个计算核心,所以使用 GPU 进行计算也就越来越流行。得益于 Nvidia 提供的 CUDA,我们编写利用 GPU 进行计算的程序越来越方便。那么,在 Linux 系统下,使用 CUDA 究竟效果如何呢?这一篇将为你揭晓答案。
我测试的是两个 2000×2000 矩阵相乘所耗费的时间,测试环境是我的 Dell XPS 15,这是一款 2015 年的产品了,CPU 是 Intel 的 6700H,4 核 8 线程,显卡是 Nvidia 的 GTX 960M,和现在 2019 年的主流比起来,已经落后几代了。前段时间“核弹”厂的老黄又发布了新的甜点级的显卡,RTX 2060,流处理器又多了几倍,还支持光线追踪,害得我心里又长了草。
继续说回矩阵相乘,我先测试了一下自己用 C 语言写一个简单的利用三重循环计算矩阵相乘的程序,然后使用 gcc 编译,运行,进行计时。其次,我自己写一段 CUDA 代码,利用显卡计算两个矩阵相乘,使用 nvcc 编译运行,进行计时。最后,使用 Nvidia 提供的 cuBLAS 库中的函数直接计算两个矩阵相乘,并进行计时。其中我自己用 C 语言写的三重循环是完全没有优化的,所以计算时间肯定比较慢,如果进行充分优化,利用 CPU 的 SSE、AVX 等向量化指令,并优化内存访问以充分利用 CPU 的缓存,可以将性能提升大约 10 倍。在雷锋网上有一篇 OpenBLAS 项目创始人和主要维护者张先轶介绍的OpenBLAS项目与矩阵乘法优化,可以一看。我用 Python 的 NumPy 测试了一下,确实可提速 8 到 10 倍,因为 NumPy 的底层调用了 OpenBLAS 库。而且这还只是利用了 CPU 的一个核,如果要利用 CPU 进行并行计算,可以考虑 OpenMP 或 MPI。
完整的 C 语言代码我放在cublas_test.cu文件中,你们没看错,扩展名为.cu,因为 CUDA 的编译器 nvcc 要求这样,nvcc 对代码进行初步处理后,还是调用的 gcc 进行编译连接生成可执行文件。完整代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <memory.h>
#include <sys/time.h>
#include <cuda_runtime.h>
#include <cublas_v2.h>
#define M 2000
#define N 2000
#define K 2000
#define idx(i, j, m) ((j) * (m) + (i))
typedef struct _matrix {
size_t height;
size_t width;
float *elements;
} Matrix;
Matrix empty(size_t m, size_t n){
Matrix temp = {m, n, NULL};
temp.elements = (float*)malloc( m*n*sizeof(float) );
return temp;
}
Matrix zeros(size_t m, size_t n){
Matrix temp = empty(m, n);
memset(temp.elements, 0, sizeof( m*n*sizeof(float) ));
return temp;
}
Matrix rands(size_t m, size_t n){
Matrix temp = empty(m, n);
for(size_t i=0; i<m*n; i++){
temp.elements[i] = (float)rand()/RAND_MAX;
}
return temp;
}
void deleteMatrix(Matrix *mat){
mat->height = 0;
mat->width = 0;
free(mat->elements);
mat->elements = NULL;
}
void printRow(Matrix mat, size_t i){
size_t m = mat.height;
size_t n = mat.width;
if(n < 7){
for(size_t j=0; j<n; j++){
printf(" %7.4f ", mat.elements[idx(i, j, m)]);
}
}else{
for(size_t j=0; j<3; j++){
printf(" %7.4f ", mat.elements[idx(i, j, m)]);
}
printf(" ... ");
for(size_t j=n-3; j<n; j++){
printf(" %7.4f ", mat.elements[idx(i, j, m)]);
}
}
printf("\n");
}
void printMatrix(Matrix mat){
size_t m = mat.height;
if(m < 7){
for(size_t i=0; i<m; i++){
printRow(mat, i);
}
}else{
for(size_t i=0; i<3; i++){
printRow(mat, i);
}
printf(" ... \n");
for(size_t i=m-3; i<m; i++){
printRow(mat, i);
}
}
printf("\n");
}
Matrix matMul(Matrix A, Matrix B){
size_t m, n, k;
Matrix C = {0, 0, NULL};
if(A.width == B.height){
m = A.height;
n = B.width;
k = B.height;
C = zeros(m, n);
for(size_t i=0; i<m; i++){
for(size_t j=0; j<n; j++){
float sum = 0;
for(size_t p=0; p<k; p++){
sum += A.elements[idx(i, p, m)] * B.elements[idx(p, j, k)];
}
C.elements[idx(i, j, m)] = sum;
}
}
}else{
printf("Matrix shape error!\n");
}
return C;
}
long getTimer(struct timeval start, struct timeval end){
return (end.tv_sec - start.tv_sec)*1000000 + (end.tv_usec - start.tv_usec);
}
void printTimer(long timer){
printf("%ld,%ld,%ld us\n", timer/1000000, (timer/1000)%1000, timer%1000);
}
bool initCUBLAS(cublasHandle_t *handle){
int count;
cudaGetDeviceCount(&count);
if(count == 0){
printf("There is no device.\n");
return false;
}else{
printf("There is %d device.\n", count);
}
int i;
for(i=0; i<count; i++){
cudaDeviceProp prop;
if(cudaGetDeviceProperties(&prop, i) == cudaSuccess){
if(prop.major >= 1){
break;
}
}
}
if(i == count){
printf("There is no device supporting CUDA 1.x.\n");
return false;
}
cudaSetDevice(i);
cublasStatus_t stat;
stat = cublasCreate(handle);
if(stat!=CUBLAS_STATUS_SUCCESS){
printf("CUBLAS initialization failed\n");
return false;
}
printf("CUBLAS initialized.\n");
return true;
}
__global__ void cudaMatMul(Matrix devA, Matrix devB, Matrix devC){
size_t m = devA.height;
size_t k = devB.height;
size_t n = devB.width;
size_t j = blockIdx.y * blockDim.y + threadIdx.y;
size_t i = blockIdx.x * blockDim.x + threadIdx.x;
if(i<m && j<n){
float sum = 0.0;
for(size_t p=0; p<k; p++){
sum += devA.elements[idx(i, p, m)] * devB.elements[idx(p, j, k)];
}
devC.elements[idx(i, j, m)] = sum;
}
}
int main(int argc, char** argv){
struct timeval start;
struct timeval end;
//第一步,创建两个随机矩阵,使用 CPU 计算它们相乘,并计时
gettimeofday(&start, NULL);
Matrix A = rands(M, K);
printf("Matrix A, shape: %ldx%ld, address in memory:%ld\n", A.height, A.width, (size_t)A.elements);
printMatrix(A);
Matrix B = rands(K, N);
printf("Matrix B, shape: %ldx%ld, address in memory:%ld\n", B.height, B.width, (size_t)B.elements);
printMatrix(B);
Matrix C = matMul(A, B);
printf("Matrix C, shape: %ldx%ld, address in memory:%ld\n", C.height, C.width, (size_t)C.elements);
printMatrix(C);
gettimeofday(&end, NULL);
printf("CPU 计算矩阵相乘,用时:");
long timer1 = getTimer(start, end);
printTimer(timer1);
//第二步,将矩阵 A 和 B 拷贝到显卡中,利用显卡计算矩阵乘法,再将结果考回 C 中,并计时
cublasHandle_t handle;
if(!initCUBLAS(&handle)){
return EXIT_FAILURE;
}
gettimeofday(&start, NULL);
size_t m = A.height;
size_t n = B.width;
size_t k = B.height;
Matrix devA = {m, k, NULL};
Matrix devB = {k, n, NULL};
Matrix devC = {m, n, NULL};
cudaMalloc(&devA.elements, m*k*sizeof(float));
cudaMemcpy(devA.elements, A.elements, m*k*sizeof(float), cudaMemcpyHostToDevice);
cudaMalloc(&devB.elements, k*n*sizeof(float));
cudaMemcpy(devB.elements, B.elements, k*n*sizeof(float), cudaMemcpyHostToDevice);
cudaMalloc(&devC.elements, m*n*sizeof(float));
cudaMemset(devC.elements, 0, m*n*sizeof(float));
//调用 GPU 进行计算
size_t blockSize = 32;
size_t gridWidth = (n + blockSize -1)/blockSize;
size_t gridHeight = (m + blockSize -1)/blockSize;
cudaMatMul<<<dim3(gridHeight, gridWidth), dim3(blockSize, blockSize)>>>(devA, devB, devC);
//从 GPU 取回数据
deleteMatrix(&C);
C = zeros(m, n);
printf("从显卡取回数据之前的矩阵 C\n");
printf("Matrix C, shape: %ldx%ld, address in memory:%ld\n", C.height, C.width, (size_t)C.elements);
printMatrix(C);
cudaMemcpy(C.elements, devC.elements, m*n*sizeof(float), cudaMemcpyDeviceToHost);
printf("从显卡取回数据之后的矩阵 C\n");
printf("Matrix C, shape: %ldx%ld, address in memory:%ld\n", C.height, C.width, (size_t)C.elements);
printMatrix(C);
gettimeofday(&end, NULL);
printf("自己写 CUDA 代码,利用 GPU 计算矩阵相乘,用时:");
long timer2 = getTimer(start, end);
printTimer(timer2);
//第三步,直接利用 cublas 库计算矩阵乘法,并计时
gettimeofday(&start, NULL);
float scalar = 1.0;
Matrix devA2 = {m, k, NULL};
Matrix devB2 = {k, n, NULL};
Matrix devC2 = {m, n, NULL};
cudaMalloc(&devA2.elements, m*k*sizeof(float));
cudaMalloc(&devB2.elements, k*n*sizeof(float));
cudaMalloc(&devC2.elements, m*n*sizeof(float));
Matrix C2 = zeros(m, n);
cublasSetMatrix(m, k, sizeof(float), A.elements, m, devA2.elements, m);
cublasSetMatrix(k, n, sizeof(float), B.elements, k, devB2.elements, k);
cublasSetMatrix(m, n, sizeof(float), C2.elements, m, devC2.elements, m);
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, m, n, k, &scalar, devA2.elements, m, devB2.elements, k, &scalar, devC2.elements, m);
printf("从显卡取回数据之前的矩阵 C2\n");
printf("Matrix C2, shape: %ldx%ld, address in memory:%ld\n", C2.height, C2.width, (size_t)C2.elements);
printMatrix(C2);
cublasGetMatrix(m, n, sizeof(float), devC2.elements, m, C2.elements, m);
printf("从显卡取回数据之后的矩阵 C2\n");
printf("Matrix C2, shape: %ldx%ld, address in memory:%ld\n", C2.height, C2.width, (size_t)C2.elements);
printMatrix(C2);
gettimeofday(&end, NULL);
long timer3 = getTimer(start, end);
printf("直接使用 Nvidia 提供的 cuBlas 库进行矩阵乘法计算,用时:");
printTimer(timer3);
printf("\n");
printf("自己写 CUDA 代码利用 GPU 计算矩阵乘法,速度是 CPU 的 %f 倍,利用 cuBlass 库进行计算,速度是 CPU 的 %f 倍。\n",
(float)timer1/timer2, (float)timer1/timer3);
return 0;
}然后,使用nvcc cublas_test.cu -lcublas -o cublas_test编译,使用./cublas_test运行,就可以看到结果了,如下两图:
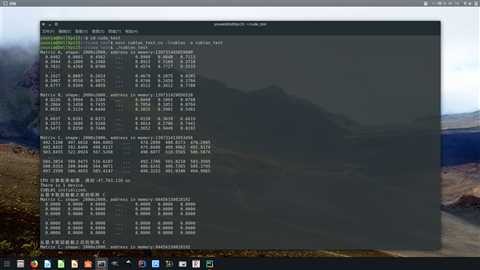
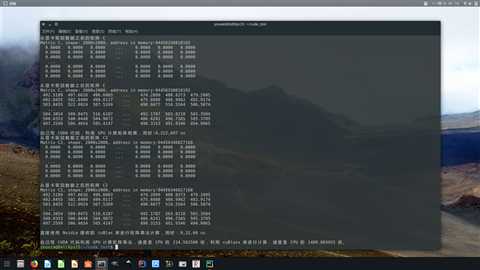
可以看到,C 语言的三重循环,用时 47.763 秒,而自己写 CUDA 代码用显卡进行计算,用时 222 毫秒,是 CPU 的 214 倍。当然,我自己写的 CUDA 代码肯定是没有优化的,如果调用 Nvidia 官方实现的 cuBLAS 库,则只用时 32 毫秒,是 CPU 的 1489 倍。这计算速度的提升,还是相当巨大的。
我使用 Python 的 NumPy 测试了一下 OpenBLAS 优化后的性能,如下图:
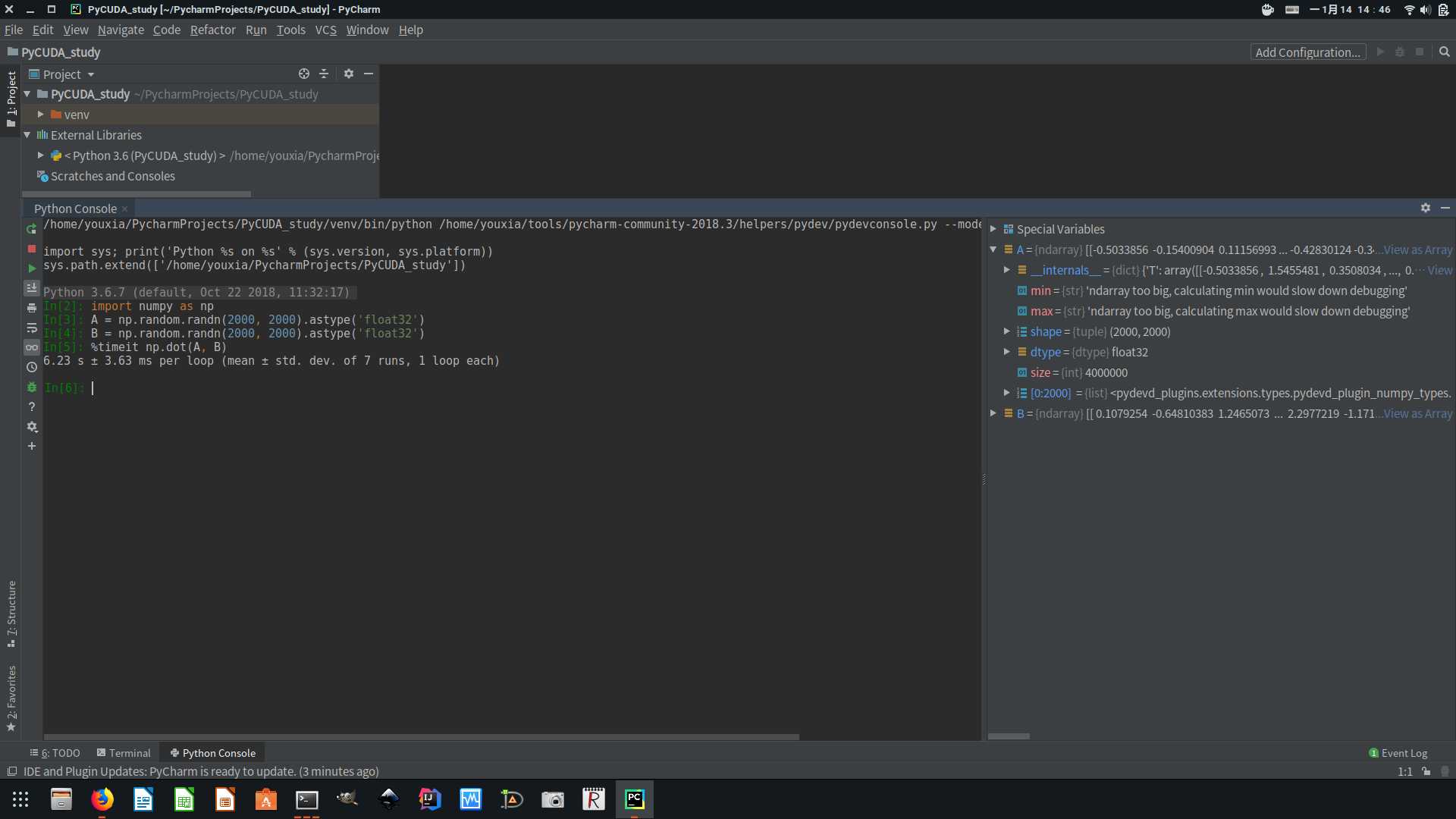
用时 6.23 秒,是 C 语言三重循环的 8 倍左右。 Python 的代码非常简单,只有四行,如下:
import numpy as np
A = np.random.randn(2000, 2000).astype('float32')
B = np.random.randn(2000, 2000).astype('float32')
%timeit np.dot(A, B)其中,%timeit是 IPython 或 Jupyter notebook 的魔术指令,专用于测性能。
上面直接给出了代码和测试结果,那么在 Linux 下写 CUDA 程序方便吗?安装开发环境容易吗?我的回答是:相当的方便,相当的容易。
首先,需要一台带 Nvidia 显卡的电脑。其次,需要安装好 Nvidia 的显卡驱动,在 Ubuntu 中,这就是一条sudo apt-get install nvidia-384或sudo apt-get install nvidia-390命令的事,我之前的随笔中有介绍。
最后,就是安装 CUDA 的开发环境了,也很简单,一条sudo apt-get install nvidia-cuda-toolkit命令就搞定。然后,就可以使用nvcc命令了,nvcc背后调用的是gcc。而 Python 环境,在 Ubuntu 中是天生的方便,前面随笔中有介绍,这里就不再罗嗦。
那用什么工具写代码和调试代码呢?由于这里用的是 C 语言,所以我首先推荐的是 JetBrains 全家桶中的 CLion,如下图:
只是有点小贵,一年 199 刀。我是不赞成使用破解版的,我只能在它提供的 30 天试用期内进行使用。土豪请随意。
而 Nvidia 也提供了一款基于 Eclipse 的工具 NSight。安装完nvidia-cuda-toolkit软件包后,该工具就有了,不需要另外下载。在命令行输入nsight命令就可以启动它,如下:
而我这里,就写一个文件而以,区区两百多行代码,要啥 IDE 啊,我用 Vim 足以,如下图:
关于 Vim 的配置,我前面的随笔也有介绍。
首先,我定义了一些辅助的结构和函数。Matrix用来定义一个矩阵,而矩阵的元素我没有使用二维数组,只是在内存中分配一块连续空间,以一维数组的形式进行访问,为了和 Fortran 兼容,使用列优先存储,所以定义了宏#define idx(i, j, m) ((j) * (m) + (i))用来根据矩阵的行i和列j定位矩阵的元素在一维数组中的下标。另外,定义的empty(m, n)、zeros(m, n)、rands(m, n)函数分别用来初始化一个空矩阵、零矩阵和随机矩阵,deleteMatrix()用来删除一个矩阵并释放内存。printMatrix()函数用来打印矩阵,便于查看结果。而矩阵相乘的函数matMul(),里面就是三重循环,不多解释。
对程序的计时,使用的是 Linux 中的gettimeofday()函数,需要包含<sys/time.h>头文件。该函数计时的精度可以到微秒级别,够用了。同时,定义printTimer()辅助函数用于输出时间数据。
重点在于对 CUDA 代码的解释。
首先,CUDA 把代码和数据都分为两部分,一部分代码是在 CPU 上执行的,叫 Runtime 函数,一部分代码是在 GPU 上执行的,叫 Kernel 函数,一部分数据存储在内存中,我们称之为 Host 上的数据,一部分数据储存在显存中,我们称之为 Device 数据。所以,我们编写 CUDA 的流程是这样的,先调用 Runtime 函数初始化 CUDA 环境,最重要的是检测系统中有没有 Nvidia 的显卡,并调用 setDevice()设置使用哪个显卡进行计算。好羡慕那些有好几个显卡的人啊。然后,在 Host 中分配空间、初始化数据、在 Device 中分配空间,将 Host 中的数据拷贝到 Device 中。这个过程需要用到malloc()、cudaMalloc()、cudaMemcpy()函数,从 Host 中向 Device 中复制数据,需要用到cudaMemcpyHostToDevice常量。
其次,就是设计 Kernel 函数和调用 Kernel 函数了。在这方面,nvcc对 C 语言进行了扩展,提供了__global__关键字,用于定义 Kernel 函数。每一个 Kernel 函数都在一个 GPU 流处理器上执行,而 GPU 往往有成百上千个流处理器,所以该 Kernel 函数相当于被成百上千个线程同时执行,进行并行计算。定义好 Kernel 函数后,就可以在 C 程序中调用,使用的是func_name<<<gridDim, blockDim>>>(args)这样的语法,而gridDim和blockDim可以指定 GPU 中的线程组织成什么形状。多个 thread 可以组织成一个 block,多个 block 可以组织成一个 grid。而 grid 和 block 可以是一维的、二维的、三维的,这样组织,非常方便我们设计程序。
最后,就是把显卡计算后的结果数据再从 Device 中拷贝到 Host 中,还是用的cudaMemcpy函数,只不过用的是cudaMemcpyDeviceToHost常数。
如果把 GPU 中的线程组织成二维的,就是这样:
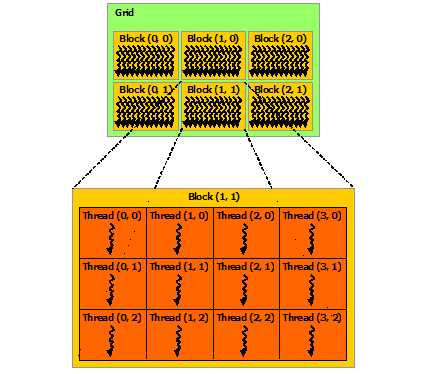
在本例中,我们需要计算一个 M×K 的矩阵和一个 K×N 的矩阵相乘,结果是一个 M×N 的矩阵,我们就可以启用 M×N 个线程,并把它组织成如上形状,每一个线程只计算结果矩阵中的一个元素,如下图:
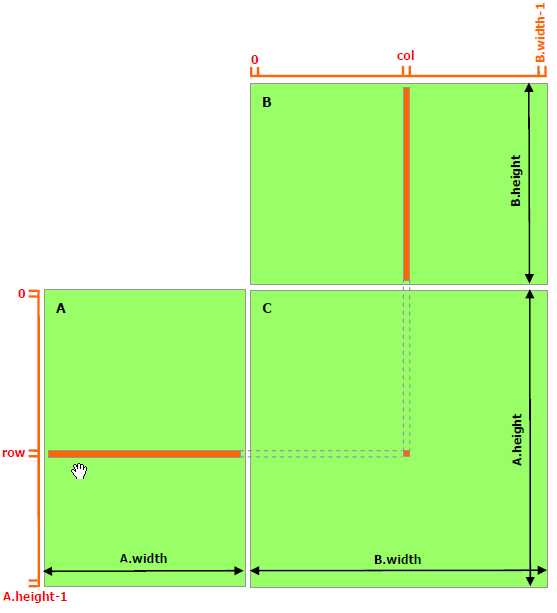
CUDA 中每个 block 中的 thread 数是有上限的,在我的电脑上,该上限是 1024。所以我定义blockSize = 32,然后 block 的形状就是(blockSize, blockSize),也就是 block 的大小为 32×32。然后再把 grid 的形状定义为((m + blockSize -1)/blockSize, (n + blockSize -1)/blockSize),这样,这个 grid 中的总线程数就是 M×N 了,而且线程排列的形状和结果矩阵的形状完全一样,所以每个线程计算结果矩阵中的一个元素,极其方便。
下面来看看完整的流程。
先在 Host 上建立矩阵 A、B、C,并初始化:
Matrix A = rands(M, K);
printf("Matrix A, shape: %ldx%ld, address in memory:%ld\n", A.height, A.width, (size_t)A.elements);
printMatrix(A);
Matrix B = rands(K, N);
printf("Matrix B, shape: %ldx%ld, address in memory:%ld\n", B.height, B.width, (size_t)B.elements);
printMatrix(B);
Matrix C = matMul(A, B);
printf("Matrix C, shape: %ldx%ld, address in memory:%ld\n", C.height, C.width, (size_t)C.elements);
printMatrix(C);然后创建三个变量用来保存在 Device 上的矩阵的形状和数据指针 devA、devB、devC,这三个变量刚开始其中的数据为空,如下:
size_t m = A.height;
size_t n = B.width;
size_t k = B.height;
Matrix devA = {m, k, NULL};
Matrix devB = {k, n, NULL};
Matrix devC = {m, n, NULL};然后在 Device 中分配空间,并把 Host 中的数据拷贝到 Device 中,这时,devA、devB、devC中的数据指针指向的是 Device 中的空间,如下:
cudaMalloc(&devA.elements, m*k*sizeof(float));
cudaMemcpy(devA.elements, A.elements, m*k*sizeof(float), cudaMemcpyHostToDevice);
cudaMalloc(&devB.elements, k*n*sizeof(float));
cudaMemcpy(devB.elements, B.elements, k*n*sizeof(float), cudaMemcpyHostToDevice);
cudaMalloc(&devC.elements, m*n*sizeof(float));
cudaMemset(devC.elements, 0, m*n*sizeof(float));再然后,调用 Kernel 函数cudaMatMul(),指定启用多少个线程,并指定 grid 和 block 的形状,并把 devA、devB、devC 传递给它做参数。如下:
size_t blockSize = 32;
size_t gridWidth = (n + blockSize -1)/blockSize;
size_t gridHeight = (m + blockSize -1)/blockSize;
cudaMatMul<<<dim3(gridHeight, gridWidth), dim3(blockSize, blockSize)>>>(devA, devB, devC);Kernel 函数cudaMatMul()是怎么定义的呢?如下:
__global__ void cudaMatMul(Matrix devA, Matrix devB, Matrix devC){
size_t m = devA.height;
size_t k = devB.height;
size_t n = devB.width;
size_t j = blockIdx.y * blockDim.y + threadIdx.y;
size_t i = blockIdx.x * blockDim.x + threadIdx.x;
if(i<m && j<n){
float sum = 0.0;
for(size_t p=0; p<k; p++){
sum += devA.elements[idx(i, p, m)] * devB.elements[idx(p, j, k)];
}
devC.elements[idx(i, j, m)] = sum;
}
}可以看到,定义 Kernel 函数时,用到了__global__关键字,并且使用了threadIdx.x、threadIdx.y、blockIdx.x、blockIdx.y、blockDim.x和blockDim.y这些内建变量,根据前面的介绍,我们非常容易猜到这些变量的意义。然后,非常容易算出当前线程计算的是结果矩阵的哪个元素 C[i, j],再然后,三重循环变成一重循环,计算起来不要太轻松,效率主要取决于访问内存的速度。
最后,将结果矩阵从 Device 拷贝到 Host 并显示,都是常规操作。如下:
deleteMatrix(&C);
C = zeros(m, n);
printf("从显卡取回数据之前的矩阵 C\n");
printf("Matrix C, shape: %ldx%ld, address in memory:%ld\n", C.height, C.width, (size_t)C.elements);
printMatrix(C);
cudaMemcpy(C.elements, devC.elements, m*n*sizeof(float), cudaMemcpyDeviceToHost);
printf("从显卡取回数据之后的矩阵 C\n");
printf("Matrix C, shape: %ldx%ld, address in memory:%ld\n", C.height, C.width, (size_t)C.elements);
printMatrix(C);如果不想自己写 CUDA 代码,可以使用 Nvidia 提供的 cuBLAS 库。除了 cuBLAS 库之外,还有 cuSPARSE 用来计算稀疏矩阵、cuFFT 用来进行傅立叶变化、cuSOLVER 用来解线性方程组、cuDNN 用来加速神经网络的计算等等。这些库优化得好,速度比我们自己写 CUDA 代码要快一些。另外,如果直接用 cuBLAS,则只需要用到 Runtime 函数,不需要自己定义 Kernel 函数,所以文件的扩展名可以不是.cu,编译器可以不用nvcc而直接用gcc,只需要包含正确的头文件和连接正确的库就可以了。当然,使用nvcc也可以。
cuBLAS 使用<cublas_v2.h>头文件,编译时使用-lcublas连接相应的库。为什么头文件中有个v2呢?这一因为这个新版本是线程安全的,所以每个 cuBLAS 函数都需要一个handle作为参数,这个handle可以使用cublasCreate()函数创建,不同的线程可以使用不同的handle。我把创建handle()的工作也放到 CUDA 初始化的代码里面了,在initCUDA()函数中。
分配内存和拷贝数据的过程是一样的,在 cuBLAS 中,一样使用cudaMalloc()和cudaMemcpy()函数,但是推荐使用cublasSetMatrix()和cublasGetMatrix()函数,因为这两个函数可以拷贝子矩阵的数据。
然后就是调用cublasSgemm()函数进行计算了,为什么这个函数名这么奇怪呢?这是因为 BLAS 库中的函数名本来就极度简化,比如mm就代表两个矩阵相乘,mv就代表一个矩阵和一个向量相乘。ge可能指的就是普通矩阵,除此之外,还有带状矩阵、对称矩阵等,分别用b、s指示。而中间的大写S,指的是数据类型,S是单精度浮点数,D是双精度浮点数,C为单精度复数,Z为双精度复数。
具体的函数,大家直接阅读 Nvidia 的官方文档吧。
使用显卡进行科学计算,得益于 GPU 大量的流处理器,计算速度可以得到成百上千倍的提升。在 Linux 环境下,安装 Nvidia 的显卡驱动和 CUDA toolkit,也是极其方便的事,而且 Nvidia 提供完善的文档和库,真的是我们的福音。
我对这次写的这个系列要求是非常高的:首先内容要有意义、够充实,信息量要足够丰富;其次是每一个知识点要讲透彻,不能模棱两可含糊不清;最后是包含丰富的截图,让那些不想装 Linux 系统的朋友们也可以领略到 Linux 桌面的风采。如果我的努力得到大家的认可,可以扫下面的二维码打赏一下:

该随笔由京山游侠在2019年01月14日发布于博客园,引用请注明出处,转载或出版请联系博主。QQ邮箱:1841079@qq.com
Linux 桌面玩家指南:16. 使用 CUDA 发挥显卡的计算性能
标签:uda stdio.h gettime 矩阵乘法 循环 方程组 sizeof 内存 evb
原文地址:https://www.cnblogs.com/youxia/p/LinuxDesktop016.html