标签:word2vec enc self element tensor evel seq war iar
最近一直在做多标签分类任务,学习了一种层次注意力模型,基本结构如下:
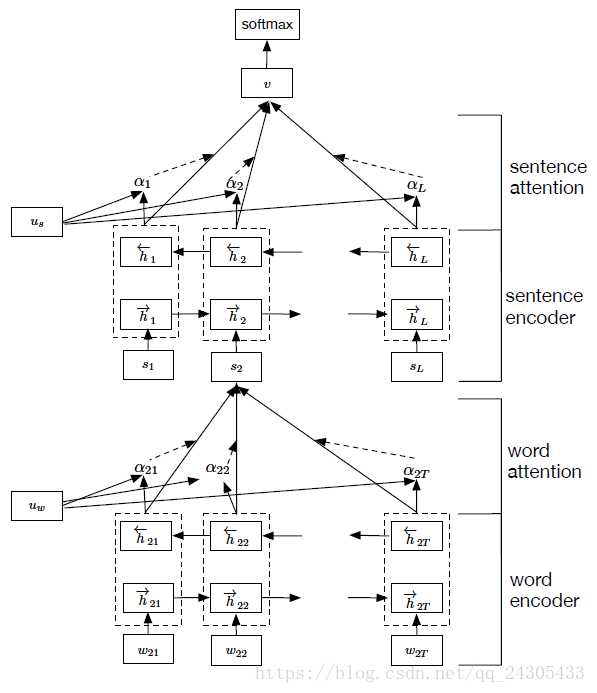
简单说,就是两层attention机制,一层基于词,一层基于句。
首先是词层面:
输入采用word2vec形成基本语料向量后,采用双向GRU抽特征:
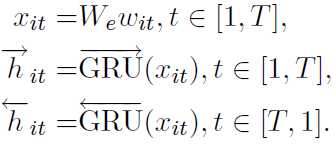
一句话中的词对于当前分类的重要性不同,采用attention机制实现如下:
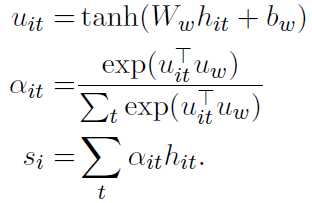
tensorflow代码实现如下:
···
def attention_word_level(self, hidden_state):
"""
input1:self.hidden_state: hidden_state:list,len:sentence_length,element:[batch_size*num_sentences,hidden_size*2]
input2:sentence level context vector:[batch_size*num_sentences,hidden_size*2]
:return:representation.shape:[batch_size*num_sentences,hidden_size*2]
"""
hidden_state_ = tf.stack(hidden_state, axis=1) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
# 0) one layer of feed forward network
hidden_state_2 = tf.reshape(hidden_state_, shape=[-1,
self.hidden_size * 2]) # shape:[batch_size*num_sentences*sequence_length,hidden_size*2]
# hidden_state_:[batch_size*num_sentences*sequence_length,hidden_size*2];W_w_attention_sentence:[,hidden_size*2,,hidden_size*2]
hidden_representation = tf.nn.tanh(tf.matmul(hidden_state_2,
self.W_w_attention_word) + self.W_b_attention_word) # shape:[batch_size*num_sentences*sequence_length,hidden_size*2]
hidden_representation = tf.reshape(hidden_representation, shape=[-1, self.sequence_length,
self.hidden_size * 2]) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
# attention process:1.get logits for each word in the sentence. 2.get possibility distribution for each word in the sentence. 3.get weighted sum for the sentence as sentence representation.
# 1) get logits for each word in the sentence.
hidden_state_context_similiarity = tf.multiply(hidden_representation,
self.context_vecotor_word) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
attention_logits = tf.reduce_sum(hidden_state_context_similiarity,
axis=2) # shape:[batch_size*num_sentences,sequence_length]
# subtract max for numerical stability (softmax is shift invariant). tf.reduce_max:Computes the maximum of elements across dimensions of a tensor.
attention_logits_max = tf.reduce_max(attention_logits, axis=1,
keep_dims=True) # shape:[batch_size*num_sentences,1]
# 2) get possibility distribution for each word in the sentence.
p_attention = tf.nn.softmax(
attention_logits - attention_logits_max) # shape:[batch_size*num_sentences,sequence_length]
# 3) get weighted hidden state by attention vector
p_attention_expanded = tf.expand_dims(p_attention, axis=2) # shape:[batch_size*num_sentences,sequence_length,1]
# below sentence_representation‘shape:[batch_size*num_sentences,sequence_length,hidden_size*2]<----p_attention_expanded:[batch_size*num_sentences,sequence_length,1];hidden_state_:[batch_size*num_sentences,sequence_length,hidden_size*2]
sentence_representation = tf.multiply(p_attention_expanded,
hidden_state_) # shape:[batch_size*num_sentences,sequence_length,hidden_size*2]
sentence_representation = tf.reduce_sum(sentence_representation,
axis=1) # shape:[batch_size*num_sentences,hidden_size*2]
return sentence_representation # shape:[batch_size*num_sentences,hidden_size*2]···
句子层面和词层面基本相同
双向GRU输入,softmax计算attention
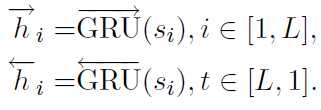
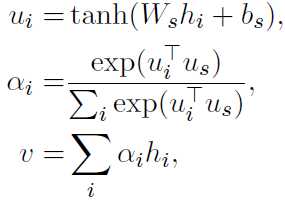
最后基于句子层面的输出,计算分类
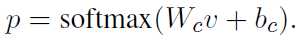
指数损失
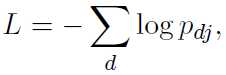
github源代码:https://github.com/zhaowei555/multi_label_classify/tree/master/han
NLP文本多标签分类---HierarchicalAttentionNetwork
标签:word2vec enc self element tensor evel seq war iar
原文地址:https://www.cnblogs.com/zhaoweiblog/p/10268884.html