标签:python版本 www. 进程池 job ext gb2312 [1] connect price
在上网查阅一些python爬虫文章时,看见有人分享了爬取股票的交易数据,不过实现得比较简单。这里就做个小练习,从百度股票批量爬取各股票的交易信息。
文章出处为:Python 爬虫实战(2):股票数据定向爬虫。
爬取数据:每个股票的日度交易数据
爬取来源:百度股市通
python版本:3.6.6
时间:20190115
以中化国际的日K数据为例,通过分析网页,我们可以发现,日度交易数据是通过接口的形式获取的。
获取的url为:https://gupiao.baidu.com/api/stocks/stockdaybar?from=pc&os_ver=1&cuid=xxx&vv=100&format=json&stock_code=sh600500&step=3&start=&count=160&fq_type=no×tamp=1547534373604
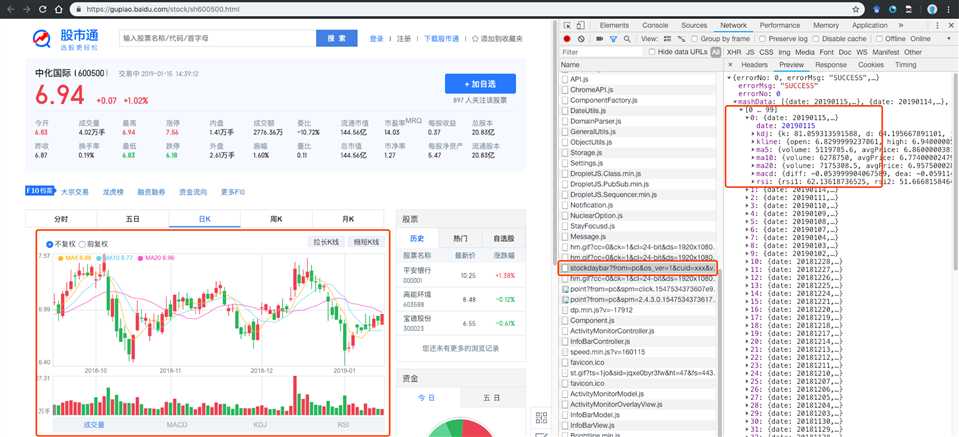
这个页面是通过get进行请求的,url中包含的参数如下:
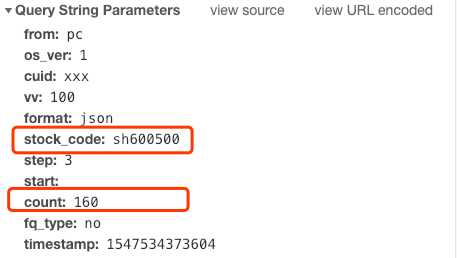
其中stock_code是请求的股票代码,因为中化国际是在上交所交易的,所以股票代码前加上了sh。如果请求时没有加上对应的sh/sz就无法查询到信息。
count是当前返回的数据量,因为是日度数据,160就是返回最近160天的日度数据。
测试后发现,fq_type和timestamp参数可以不填。
所以我们就得到了获取日度交易数据的URL; https://gupiao.baidu.com/api/stocks/stockdaybar?from=pc&os_ver=1&cuid=xxx&vv=100&format=json&stock_code=sh600500&step=3&start=&count=160
对stock_code进行替换就可以获得不同股票对应的日度数据。
既然我们找到了根据股票代码获取其对应日度数据的地址,接下来就要去找一下如何获取每个股票的股票代码。
没有在股市通中找到哪个页面有陈列所有股票的=对应的股票代码,这里借鉴上面提到的文章,从东方财富网抓取每个股票对应的代码:http://quote.eastmoney.com/stocklist.html
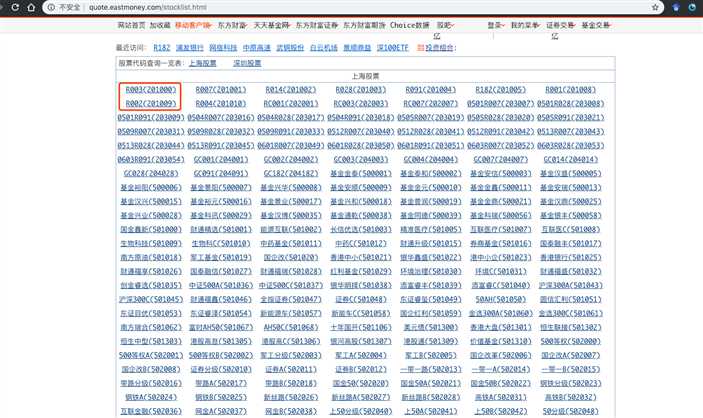
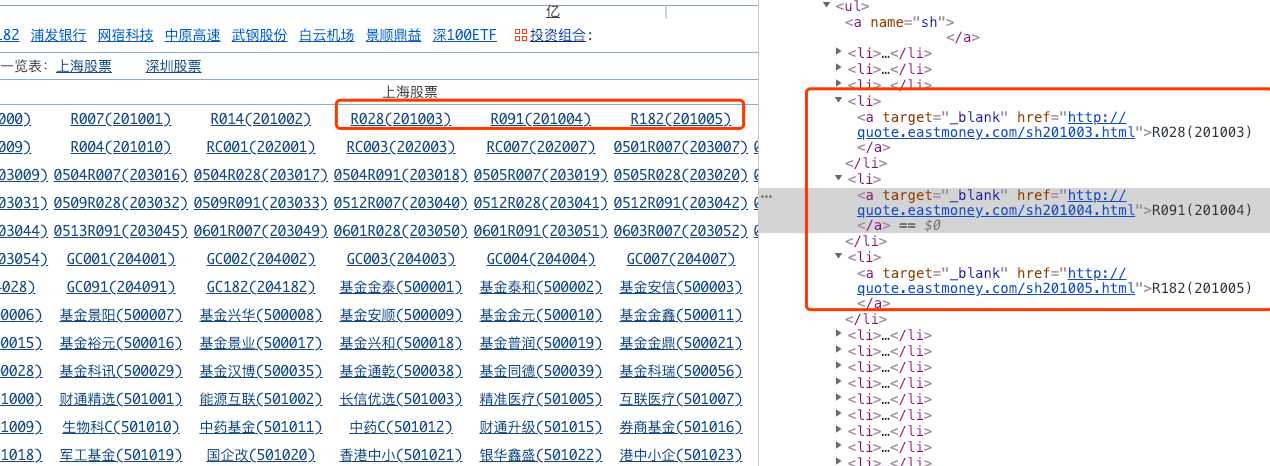
这个页面中每个股票对应的代码是直接写在HTML代码里,所以我们只需要使用BeautifulSoup或其他库解析网页即可。
import pymysql from multiprocessing import Pool
import time # 从东方财富网获取各股票代码 def get_stock_info(list_url): stock_info = [] # 各股票信息存入stock_info try: r = requests.get(list_url) r.encoding = ‘gb2312‘ # 网页编码为gb2312 soup = BeautifulSoup(r.text, ‘html.parser‘) stock_city = ‘sh‘ # 默认为sh,先爬取上交所交易的股票,再爬取深交所的股票 for each_city in soup.find(‘div‘, class_=‘quotebody‘)(‘ul‘): for each_stock in each_city.findAll(‘li‘): stock_info.append( {‘stock_name‘: each_stock.get_text().split(‘(‘)[0], # 股票名称 ‘stock_code‘: each_stock.get_text().split(‘(‘)[1].replace(‘)‘, ‘‘), # 股票代码 ‘stock_url‘: each_stock.find(‘a‘)[‘href‘], # 股票对应的url ‘stock_city‘: stock_city # sh/sz } ) stock_city = ‘sz‘ # 上交所的读取完后切换为深交所 print(‘获取股票代码成功,共‘, len(stock_info), ‘只股票‘) except: print(‘获取股票代码失败‘) return stock_info # 根据股票代码进行访问,每次获取一只股票的过去250天交易数据,并一次性插入数据库 def get_stock_data(each_stock): header = { ‘Host‘: ‘gupiao.baidu.com‘, ‘User-Agent‘: ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36‘ } db = pymysql.connect(host=‘localhost‘, user=‘root‘, password=‘mysqlkey‘, db=‘test_db‘, port=3306) cursor = db.cursor() # 创建游标对象cursor stock_url = ‘https://gupiao.baidu.com/api/stocks/stockdaybar?from=pc&os_ver=1&cuid=xxx&vv=100&format=json&stock_code={}&start=&count=250‘.format( each_stock[‘stock_city‘]+str(each_stock[‘stock_code‘])) try: stock_r = requests.get(stock_url, headers=header).json()
time.sleep(0.2)
if stock_r[‘errorMsg‘]==‘SUCCESS‘: stock_json = stock_r[‘mashData‘] insert_data = [] # 保存单个股票的250天的交易数据 for each_day in stock_json: # 每一天的数据 data = {‘stock_name‘: str(each_stock[‘stock_name‘]), ‘stock_code‘: str(each_stock[‘stock_code‘]), ‘date‘: each_day[‘date‘], ‘open‘: each_day[‘kline‘][‘open‘], ‘high‘: each_day[‘kline‘][‘high‘], ‘low‘: each_day[‘kline‘][‘low‘], ‘close‘: each_day[‘kline‘][‘close‘], ‘volume‘: each_day[‘kline‘][‘volume‘], ‘amount‘: each_day[‘kline‘][‘amount‘], ‘pre_close‘: each_day[‘kline‘][‘preClose‘], ‘net_change_ratio‘: each_day[‘kline‘][‘netChangeRatio‘], ‘ma5_volume‘: each_day[‘ma5‘][‘volume‘], ‘ma5_avg_prive‘: each_day[‘ma5‘][‘avgPrice‘], ‘ma10_volume‘: each_day[‘ma10‘][‘volume‘], ‘ma10_avg_price‘: each_day[‘ma10‘][‘avgPrice‘], ‘ma20_volume‘: each_day[‘ma20‘][‘volume‘], ‘ma20_avg_price‘: each_day[‘ma20‘][‘avgPrice‘], ‘macd_diff‘: each_day[‘macd‘][‘diff‘], ‘macd_dea‘: each_day[‘macd‘][‘dea‘], ‘macd‘: each_day[‘macd‘][‘macd‘], ‘kdj_k‘: each_day[‘kdj‘][‘k‘], ‘kdj_d‘: each_day[‘kdj‘][‘d‘], ‘kdj_j‘: each_day[‘kdj‘][‘j‘], ‘rsi_1‘: each_day[‘rsi‘][‘rsi1‘], ‘rsi_2‘: each_day[‘rsi‘][‘rsi2‘], ‘rsi_3‘: each_day[‘rsi‘][‘rsi3‘] } # 本只股票的250日数据,为包含tuple的list,用于MySQL的executemany批量插入 insert_data.append(tuple((str(values) for key,values in data.items()))) # 插入MySQL,每只股票只执行一次插入操作 insert_into_mysql(db=db, cursor=cursor, data=insert_data, stock_code=str(each_stock[‘stock_code‘])) print(each_stock[‘stock_code‘], ‘insert done‘) except: print(each_stock[‘stock_code‘], ‘not done‘) finally: cursor.close() db.close() # 创建MySQL表 def create_table(): db = pymysql.connect(host=‘localhost‘, user=‘root‘, password=‘mysqlkey‘, db=‘test_db‘, port=3306) cursor = db.cursor() # 创建游标对象cursor cursor.execute(‘DROP TABLE IF EXISTS stock‘) # 执行SQL,如果stock表存在就删除 # 创建表 # 因为对MySQL各种数据类型还没有做详细了解,这里暂时都设置为CHAR类型 create_table_sql = """ CREATE TABLE stock( stock_name CHAR(50), stock_code CHAR(50), date CHAR(50) COMMENT ‘日期‘, open CHAR(50) COMMENT ‘开盘价‘, high CHAR(50) COMMENT ‘最高价‘, low CHAR(50) COMMENT ‘最低价‘, close CHAR(50) COMMENT ‘收盘价‘, volume CHAR(50) COMMENT ‘成交量‘, amount CHAR(50), pre_close CHAR(50) COMMENT ‘前一天收盘价‘, net_change_ratio CHAR(50) COMMENT ‘净换手率‘, ma5_volume CHAR(50) COMMENT ‘5日均线交易量‘, ma5_avg_prive CHAR(50) COMMENT ‘5日均价‘, ma10_volume CHAR(50) COMMENT ‘5日均价‘, ma10_avg_price CHAR(50) COMMENT ‘5日均价‘, ma20_volume CHAR(50) COMMENT ‘5日均价‘, ma20_avg_price CHAR(50) COMMENT ‘5日均价‘, macd_diff CHAR(50) COMMENT ‘5日均价‘, macd_dea CHAR(50) COMMENT ‘5日均价‘, macd CHAR(50) COMMENT ‘5日均价‘, kdj_k CHAR(50) COMMENT ‘5日均价‘, kdj_d CHAR(50) COMMENT ‘5日均价‘, kdj_j CHAR(50) COMMENT ‘5日均价‘, rsi_1 CHAR(50) COMMENT ‘5日均价‘, rsi_2 CHAR(50) COMMENT ‘5日均价‘, rsi_3 CHAR(50) COMMENT ‘5日均价‘ )""" try: cursor.execute(create_table_sql) db.commit() print(‘create table stock done‘) except: db.rollback() print(‘create table stock not done‘) finally: cursor.close() db.close() # 插入MySQL def insert_into_mysql(db, cursor, data, stock_code): insert_sql = """ INSERT INTO stock( stock_name, stock_code, date, open, high, low, close, volume, amount, pre_close, net_change_ratio, ma5_volume, ma5_avg_prive, ma10_volume, ma10_avg_price, ma20_volume, ma20_avg_price, macd_diff, macd_dea, macd, kdj_k, kdj_d, kdj_j, rsi_1, rsi_2, rsi_3) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s, %s) """ try: cursor.executemany(insert_sql, data) # executemany批量插入数据 db.commit() except: db.rollback() stock_info = get_stock_info(‘http://quote.eastmoney.com/stocklist.html‘) # 获取东方财富网的所有股票代码 create_table() # 创建stock表 pool = Pool(4) # 4个进程的进程池 pool.map(get_stock_data, stock_info) pool.close() # 进程池停止写入 pool.join() # 进程池阻塞 print(‘all done‘)
效果如下:
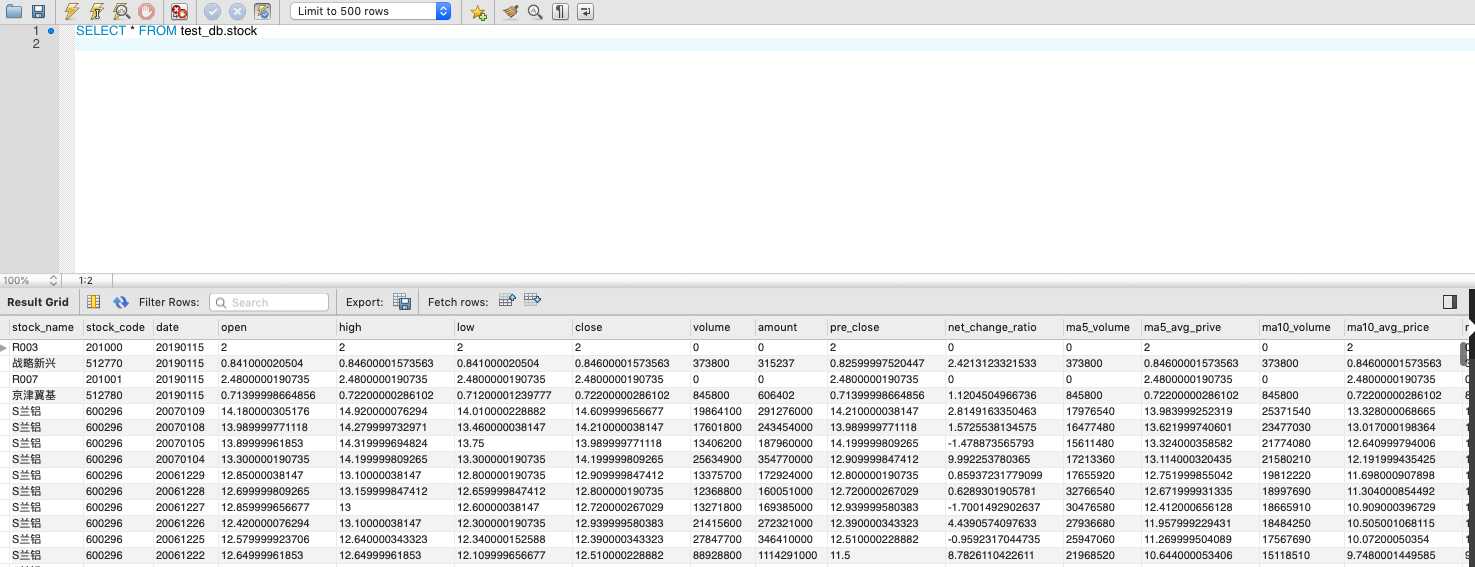
开始想的是在创建stock表的时候就同MySQL建立连接,之后每个进程的每次插入都使用这个连接。
参考Python多线程运行带多个参数的函数,使用partial函数为get_stock_info()传递connect和cursor。但是显示cannot serialize _io.BufferedReader object错误。
搜寻信息后发现报错原因是讲一个不可序列化的对象传递给对象导致的问题,这里的理解是,MySQL的connect和cursoe不可序列化,无法被实例传递给子进程因而出现了错误。
从这里:数据库并行读取和写入(Python实现) 找到一个解决方案:应该为每个进程分配不同的connect和cursor,否则数据库会报错。

既然在1中我们已经能够拿到每只股票对应的详情页面,为什么不直接从这个详情页面进行抓取呢?
原因是:东方财富网确实有每只股票的详情页面,包含这只股票的各种数据。但是在之前分析页面的时候,居然发现股票的数据都是以图片形式传输的,不是格式化的数据...
现在忘了当时查看的是哪只股票了,就没有办法重现。现在重新查看,发现这里的股票数据应该也是通过接口形式传输的,这个就等之后有兴趣再尝试了。
标签:python版本 www. 进程池 job ext gb2312 [1] connect price
原文地址:https://www.cnblogs.com/xingyucn/p/10273566.html