标签:ace pycha 开始 安装 奇数 text 远程 绕过 图片下载
项目说明:
Python版本:3.7.2
模块:urllib.request,re,os,ssl
目标地址:http://小草.com/
第二个爬虫项目,设备转移到了Mac上,Mac上的Pycharm有坑, 环境变量必须要配置好,解释器要选对,不然模块加载不出来
项目实现:
#!/usr/bin/env python3 # -*- coding:utf-8 -*- #__author__ = ‘vic‘ ##导入模块 import urllib.request,re,os
小草图片下载时后有ssl证书验证,我们全局跳过验证
ssl._create_default_https_context = ssl._create_unverified_context
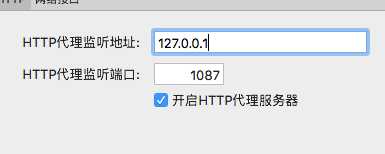
一、设置代理
小草服务器在海外,需要绕过GFW,代理软件选择的是ssX-NG,偏好设置查看监听地址
Path = ‘/Users/vic/Pictures/‘ ##设置代理,http和https都用的是http监听,也可以改为sock5 proxy = urllib.request.ProxyHandler({‘http‘:‘http://127.0.0.1:1087/‘,‘https‘:‘https://127.0.0.1:1087‘}) ##创建支持处理HTTP请求的opener对象 opener = urllib.request.build_opener(proxy) ##安装代理到全局环境 urllib.request.install_opener(opener) ##定义请求头,Upgrade-Insecure-Requests表示能够处理https header = {‘Upgrade-Insecure-Requests‘:‘1‘,"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15"}
二、获取源代码
def getcontent(url): req = urllib.request.Request(url,headers = header) ##同requests一样,request转为response res = urllib.request.urlopen(req) content = res.read() ##内存及时关闭 res.close() return content
三、获取列表链接
##链接最后为相应页码 url = ‘http://小草.com/thread0806.php?fid=16&search=&page=‘
分析文章链接,也就是http://小草.com/直接加上后缀即可,把所有颜色的链接全部扒下来

但是有个公告栏只在第一页有,所以我想到了在第一页把list切片
def geturl_list(url,i): ##列表链接+页码 article_url = url + str(i) ##转为字符串 content = str(getcontent(article_url)) ##创建正则模式对象,匹配全文链接 pattern = re.compile(r‘<a href="htm_data.{0,30}html" target="_blank" id="">.*?‘) ##取出所有匹配内容 com_list = pattern.findall(content) ##如果是第一页,把公告栏链接切片 if i == 1: com_list = com_list[7:] ##链接正则 pattern_url = re.compile(r‘a href="(.*?)"‘) ##取出所有链接后缀 url_list = pattern_url.findall(str(com_list)) return url_list
四、获取图集信息
先找标题

这个简单,re直接找title就好了
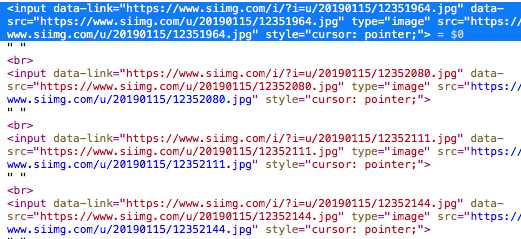
然后是图片地址,图片的后缀大多是JPG和少量的GIF,但是Python的格式好像太严格了?所以图片格式分别大小写 ,图床地址全是https协议的,最重要的是有大图片小图片链接,大图片下载是盗链,我解决不了,所以可以等差求奇数链接
def getTitle_Imgurl(url): content = getcontent(url) ##内容转gbk string = content.decode(‘gbk‘, ‘replace‘) #print(string) m = re.findall("<title>.*</title>", string) ##切片去掉标题两边的标签 title = m[0][7:-35] ##图片地址匹配正则,gif文件太大,我只要jpg格式的 pattern = re.compile(r‘(https:[^\s]*?(JPG|jpg))‘) ##取出图片地址,返回tuple添加到list里,tuple结构为(网址,格式类型) Imgurl_list = pattern.findall(str(content)) return title,Imgurl_list
五、下载函数
rllib.request.urlretrieve()
下载也有坑,这个远程下载在PC上好像可以直接使用,但是在mac上单文件链接可以下载,但是放进程序了死活下不下来,而且还慢,所以还是选择传统的
def downImg(url,path,count): try: req = urllib.request.Request(url, headers=header) res = urllib.request.urlopen(req) content = res.read() with open(path + ‘/‘ + str(count) + ‘.jpg‘, ‘wb‘) as file: file.write(content) file.close() except: print(‘ERROR‘)
六、主函数
def main(): ##1到20页列表 for i in range(1,20): ##第一页文章列表 url_list = geturl_list(url,i) ##文章地址拼接,list从0开始 for t in range(0,len(url_list) - 1): artical_url = ‘http://小草.com/‘ + url_list[t] print(artical_url) ##取标题,图片地址list title, Imgurl_list = getTitle_Imgurl(artical_url) ##创建文件夹 Img_Path = Path + title if not os.path.isdir(Img_Path): os.mkdir(Img_Path) ##循环图片地址,小图片和大图片通过取奇数解决,大图片下载会得到盗链 for num in range(1,len(Imgurl_list) - 1,2): Imgurl = Imgurl_list[num][0] downImg(Imgurl,Img_Path,num) else: print(‘已下载跳过‘)
七、全部代码
#!/usr/bin/env python3 # -*- coding:utf-8 -*- #__author__ = ‘vic‘ import urllib.request,re,os,ssl ssl._create_default_https_context = ssl._create_unverified_context url=‘http://小草.com/thread0806.php?fid=16&search=&page=‘ Path = ‘/Users/vic/Pictures/‘ proxy = urllib.request.ProxyHandler({‘http‘:‘http://127.0.0.1:1087/‘,‘https‘:‘https://127.0.0.1:1087‘}) opener = urllib.request.build_opener(proxy) urllib.request.install_opener(opener) header = {‘Upgrade-Insecure-Requests‘:‘1‘,"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15"} def getcontent(url): req = urllib.request.Request(url,headers = header) res = urllib.request.urlopen(req) content = res.read()#.decode(‘gbk‘,‘replace‘) res.close() return content def geturl_list(url,i): article_url = url + str(i) content = str(getcontent(article_url)) pattern = re.compile(r‘<a href="htm_data.{0,30}html" target="_blank" id="">.*?‘) com_list = pattern.findall(content) if i == 1: com_list = com_list[7:] pattern_url = re.compile(r‘a href="(.*?)"‘) url_list = pattern_url.findall(str(com_list)) return url_list def getTitle_Imgurl(url): content = getcontent(url) string = content.decode(‘gbk‘, ‘replace‘) m = re.findall("<title>.*</title>", string) title = m[0][7:-35] pattern = re.compile(r‘(https:[^\s]*?(JPG))‘) Imgurl_list = pattern.findall(str(content)) return title,Imgurl_list def downImg(url,path,count): try: req = urllib.request.Request(url, headers=header) res = urllib.request.urlopen(req) content = res.read() with open(path + ‘/‘ + str(count) + ‘.jpg‘, ‘wb‘) as file: file.write(content) file.close() except: print(‘ERROR‘) def main(): for i in range(1,20): url_list = geturl_list(url,i) for t in range(0,len(url_list) - 1): artical_url = ‘http://小草com/‘ + url_list[t] print(artical_url) title, Imgurl_list = getTitle_Imgurl(artical_url) Img_Path = Path + title if not os.path.isdir(Img_Path): os.mkdir(Img_Path) for num in range(1,len(Imgurl_list) - 1,2): Imgurl = Imgurl_list[num][0] downImg(Imgurl,Img_Path,num) else: print(‘已下载跳过‘) if __name__ == ‘__main__‘: if not os.path.isdir(Path): os.mkdir(Path) main()
八、项目成果
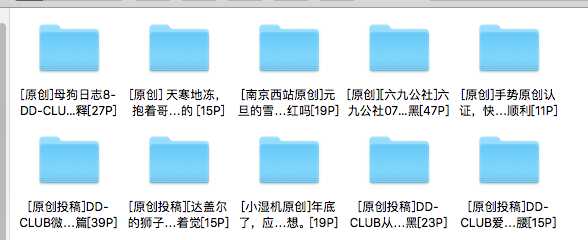
文件名也是成等差了,有点尴尬,就这样吧。
最后总的来说爬虫,BeautifulSoup要比正则好用的多,requests也要比urllib.request简单,搞了一晚上,等两天再爬其他的
Python爬小草1024图片,盖达尔的诱惑(urllib.request)
标签:ace pycha 开始 安装 奇数 text 远程 绕过 图片下载
原文地址:https://www.cnblogs.com/viczc/p/10274613.html