一、mysql(mariadb)基础
1、基础命令(centos7操作系统下)

1.启动mysql systemctl start mariadb 2.linux客户端连接自己 mysql -uroot -p -h 127.0.0.1 -u 用户 -p 密码验证 -h 连接的主机地址 3.远程链接mysql服务端 mysql -uroot -p -h 192.168.3.115 4.修改mysql密码 # 修改当前用户的密码 set password = PASSWORD(‘mariadb123‘); # 修改其他用户的密码 set password for ‘username‘@‘host‘ = PASSWORD(‘newpassword‘) 5.创建mysql用户 create user xiaoming@‘%‘ identified by ‘xm666‘; 6.查询mysql库中的用户信息 use mysql; # mysql是默认存在的库,储存着用户的信息,密码之类的 select host,user,password from user; 7.授权语句 给小明这个用户,授予创建数据库的权限 mysql中使用grant命令对账户进行授权,grant命令常见格式如下 grant 权限 on 数据库.表名 to 账户@主机名 对特定数据库中的特定表授权 grant 权限 on 数据库.* to 账户@主机名 对特定数据库中的所有表给与授权 grant 权限1,权限2,权限3 on *.* to 账户@主机名 对所有库中的所有表给与多个授权 grant all privileges on *.* to 账户@主机名 对所有库和所有表授权所有权限 # 授予小明创建的权限,对于所有的库表生效 grant create on *.* to xiaoming@"%"; # 创建用户并授予用户只有创建test数据库的权限 grant create on test.* to xiaoming2@"%" identified by ‘xm2666‘; # 授予用户最大的权限,所有的权限 grant all privileges on *.* to username@‘%‘ identified by ‘password‘; # 刷新权限 flush privileges; # 刷新使授权立即生效 # 查看用户权限 show grants for ‘xiaoming‘@‘%‘; 8.移除权限 revoke all privileges on *.* from xiaoming@"%";
2、数据库的备份与恢复
# 备份 mysqldump -u root -p --all-databases > /tmp/db.sql # 数据导入,方式有几种 第一种 source /tmp/db.sql; 第二种 mysql -uroot -p < /tmp/db.sql 第三种 使用navicat工具 第四种,如果你数据量特别大的话 使用第三方工具 xtrabackup
二、mysql主从复制
1、mysql主从复制背景
1.如果你是单点数据库,数据库挂了,你整个项目就挂了
2.如果你是主备数据库,挂了一台主库,我可能还有千千万万个备用的数据库
3.原理
MySQL数据库的主从复制是其自带的功能,主从复制并不是复制磁盘上的数据库文件,而是通过主库的binlog日志复制到需要同步的从服务器上。
在复制的过程中,一台服务器充当主服务器(Master),接收来自用户的内容更新,而一个或多个其他的服务器充当从服务器(slave),接收来自Master上binlog文件的日志内容,解析出SQL,重新更新到Slave,使得主从服务器数据达到一致。
主从复制的逻辑有以下几种
一主一从,单向主从同步模式,只能在Master端写入数据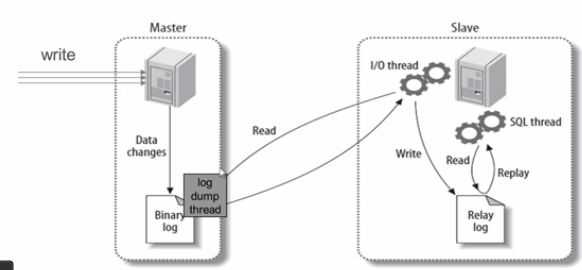
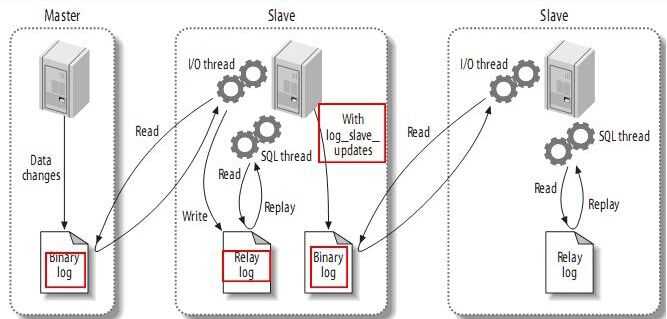
一主多从
双主主复制逻辑架构,此架构可以在Master1或Master2进行数据写入,或者两端同时写入(特殊设置)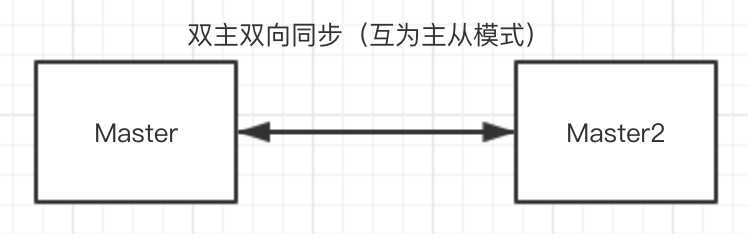
4.应用场景
利用复制功能当Master服务器出现问题时,我们可以人工的切换到从服务器继续提供服务,此时服务器的数据和宕机时的数据几乎完全一致。
复制功能也可用作数据备份,但是如果人为的执行drop,delete等语句删除,那么从库的备份功能也就失效了
2、mysql主从复制主库的配置步骤
1.在matser(192.168.3.115)主库上的操作,开启主库功能 # 先把主数据库停了 systemctl stop mariadb # 编辑数据库的配置文件 /etc/my.cnf ,写入如下信息 [mysqld] server-id=6 # 这个server-id只要与你从库的server-id不一样即可 log-bin=master-logbin # 生成二进制日志,记录数据的变化 # 重启数据库 systemctl start mariadb 2.在主库创建用户,用于同步数据 create user xiaoming@‘%‘ identified by ‘xm666‘; 授予用户,slave从库的身份 grant replication slave on *.* to ‘xiaoming‘@‘%‘; 3.锁定数据库的库表,禁止写入 这个命令是全局读锁定,执行了命令之后所有库所有表都被锁定只读。一般都是用在数据库联机备份,这个时候数据库的写操作将被阻塞,读操作顺利进行。 解锁语句是:UNLOCK TABLES; flush table with read lock; 记录下主库的状态,记录下,日志文件的名字,和位置 show master status; 4.导出主库的数据 mysqldump -u root -p --all-databases > /tmp/db.sql
5.确保数据导出后,没有数据插入,完毕再查看主库状态
show master status;
6.远程传输主库的数据,给从库,进行导入 scp /tmp/db.sql root@192.168.3.27:/tmp/ 7.解锁主库的锁,写入数据,查看从库是否同步 unlock tables;
3、从库slave(192.168.3.27)机器的配置步骤
1.在从库的 /etc/my.cnf中添加参数,添加只读参数 [mysqld] server-id=3 read-only=true 2.重启数据库 systemctl restart mariadb 在从库中导入主库的数据 mysql -uroot -p < /tmp/db.sql 3.一条语句,开启主从之间的复制关系 用root用户,进入mysql数据库,输入命令: change master to master_host=‘192.168.3.115‘, # 主数据库的ip master_user=‘xiaoming‘, # 普通用户的用户名 master_password=‘xm666‘, # 普通用户的密码 master_log_file=‘master-logbin.000002‘, # 主库show master status;日志文件的名字 master_log_pos=492; # 主库show master status;记录的位置 4.开启slave同步功能 start slave; 5.检查slave机器的主从是否正确 show slave status\G 查看主从同步是否正确 确保如下两条参数,是yes,即主从复制正确 Relay_Master_Log_File: master-logbin.000002 Slave_IO_Running: Yes Slave_SQL_Running: Yes 6.此时mariadb数据库,请退出root用户,使用普通用户配置,因为root身份权限太大,无法达到read-only效果 6.此时mariadb数据库,请退出root用户,使用普通用户配置,因为root身份权限太大,无法达到read-only效果 6.此时mariadb数据库,请退出root用户,使用普通用户配置,因为root身份权限太大,无法达到read-only效果 7.登录一个普通用户
mysql -u xiaoming -p 8.此时在主库写入数据,查看从库是否正确同步 9.从库无法写入数据,即为正常 10.完成主从同步,读写分离实验
三、redis基础
redis是一种高级的key:value存储系统,其中value支持五种数据类型
String: 字符串
Hash: 散列
List: 列表
Set: 集合
Sorted Set: 有序集合
1、strings类型
操作
set 设置key get 获取key append 追加string mset 设置多个键值对 mget 获取多个键值对 del 删除key incr 递增+1 decr 递减-1
示例
127.0.0.1:6379> set name ‘dog‘ # 设置key OK 127.0.0.1:6379> get name # 获取value "dog" 127.0.0.1:6379> set name ‘BigDog‘ # 覆盖key OK 127.0.0.1:6379> get name # 获取value "BigDog" 127.0.0.1:6379> append name ‘ is you‘ # 向name这个key追加 (integer) 13 127.0.0.1:6379> get name # 获取value "BigDog is you" 127.0.0.1:6379> mset age 18 hight 180 long 18.8 # 一次性设置多个键值对 OK 127.0.0.1:6379> mget age hight long # 一次性获取多个键的值 1) "18" 2) "180" 3) "18.8" 127.0.0.1:6379> get age # 获取value "18" 127.0.0.1:6379> keys * # 找到所有key 1) "long" 2) "hight" 3) "age" 4) "name" 127.0.0.1:6379> del name # 删除key (integer) 1 127.0.0.1:6379> get name # 获取不存在的value,为nil (nil) 127.0.0.1:6379> set num 10 OK 127.0.0.1:6379> get num "10" 127.0.0.1:6379> incr num # 递增+1 (integer) 11 127.0.0.1:6379> get num "11" 127.0.0.1:6379> decr num # 递减-1 (integer) 10 127.0.0.1:6379> get num "10"
2、list类型
操作
lpush 从列表左边插
rpush 从列表右边插
lrange 获取一定长度的元素 lrange key start stop(相当于获取切片的内容)
ltrim 截取一定长度列表
lpop 删除最左边一个元素
rpop 删除最右边一个元素
lpushx/rpushx key存在则添加值,不存在不处理
示例
127.0.0.1:6379> lpush list1 ‘a‘ ‘b‘ ‘c‘ ‘d‘ # 新建一个list1,从左边放入四个元素 (integer) 4 127.0.0.1:6379> llen list1 # 查看list1的长度 (integer) 4 127.0.0.1:6379> lrange list1 0 -1 # 查看list所有元素 1) "d" 2) "c" 3) "b" 4) "a" 127.0.0.1:6379> rpush list1 ‘haha‘ # 从右边插入haha (integer) 5 127.0.0.1:6379> lrange list1 0 -1 1) "d" 2) "c" 3) "b" 4) "a" 5) "haha" 127.0.0.1:6379> lpushx list3 ‘xixi‘ # list3存在则添加元素,不存在则不作处理 (integer) 0 127.0.0.1:6379> ltrim list1 0 3 # 截取队列的值,从索引0取到3,删除其余的元素 OK 127.0.0.1:6379> lrange list1 0 -1 1) "d" 2) "c" 3) "b" 4) "a" 127.0.0.1:6379> lpop list1 # 删除左边的第一个 "d" 127.0.0.1:6379> lrange list1 0 -1 1) "c" 2) "b" 3) "a" 127.0.0.1:6379> rpop list1 # 删除右边的第一个 "a" 127.0.0.1:6379> lrange list1 0 -1 1) "c" 2) "b"
3、set集合类型
redis的集合,是一种无序的集合,集合中的元素没有先后顺序,且集合成员是唯一的。
操作
sadd/srem 添加/删除 元素
sismember 判断是否为set的一个元素
smembers 返回集合所有的成员
sdiff 返回一个集合和其他集合的差异
sinter 返回几个集合的交集
sunion 返回几个集合的并集
示例
127.0.0.1:6379> sadd school class1 class2 # 添加一个名叫school的集合,有2个元素,不加引号就当做字符串处理 (integer) 2 127.0.0.1:6379> smembers school # 查看集合school成员 1) "class1" 2) "class2" 127.0.0.1:6379> srem school class1 # 删除school的class1成员 (integer) 1 127.0.0.1:6379> smembers school 1) "class2" 127.0.0.1:6379> sismember school class1 # 是否是school的成员,不是返回0,是返回1 (integer) 0 127.0.0.1:6379> sadd school class3 # 给school添加一个新成员 (integer) 1 127.0.0.1:6379> smembers school 1) "class3" 2) "class2" 127.0.0.1:6379> sadd school2 class3 class4 # 添加一个名叫school2的集合,有2个元素 (integer) 1 127.0.0.1:6379> smembers school2 1) "class3" 2) "class4" 127.0.0.1:6379> sdiff school school2 # 找出集合school中有的,而school2中没有的元素 1) "class2" 127.0.0.1:6379> sdiff school2 school # 找出集合school2中有的,而school中没有的元素 1) "class4" 127.0.0.1:6379> sinter school school2 # 找出school和school2的交集 1) "class3" 127.0.0.1:6379> sunion school school2 # 找出school和school2的并集(自动去重) 1) "class3" 2) "class4" 3) "class2"
4、哈希数据结构
hashes即哈希。哈希是从redis-2.0.0版本之后才有的数据结构。
hashes存的是字符串和字符串值之间的映射,比如一个用户要存储其全名、姓氏、年龄等等,就很适合使用哈希。
操作
hset 设置散列值
hget 获取散列值
hmset 设置多对散列值
hmget 获取多对散列值
hsetnx 如果散列已经存在,则不设置(防止覆盖key)
hkeys 返回所有keys
hvals 返回所有values
hlen 返回散列包含域(field)的数量
hdel 删除散列指定的域(field)
hexists 判断是否存在
注意
Hash不支持多次嵌套,即 "key": {‘field‘: ‘不能再对应字典‘} "key": {‘field‘: {...}} --> 错误 若想嵌套字典,可以json.dumps后存入,取出数据的时候可以json.loads
语法
hset key field value 结构如下 key: { field1: value1, field2: value2, }
示例
127.0.0.1:6379> hset school name ‘ChinaSchool‘ # 创建一个key为school的哈希数据 (integer) 1 127.0.0.1:6379> hget school name # 获取school的name的值 "ChinaSchool" 127.0.0.1:6379> hmset school age 100 area 2000 # 给school批量设置键值对 OK 127.0.0.1:6379> hmget school name age area # 批量获取school的键对应的值 1) "ChinaSchool" 2) "100" 3) "2000" 127.0.0.1:6379> hkeys school # 获取school的所有key 1) "name" 2) "age" 3) "area" 127.0.0.1:6379> hvals school # 获取school的所有值 1) "ChinaSchool" 2) "100" 3) "2000" 127.0.0.1:6379> hlen school # 获取school的长度 (integer) 3 127.0.0.1:6379> hexists school name # 判断school中是否有name这个键,有就返回1,没有就返回0 (integer) 1 127.0.0.1:6379> hdel shcool area # 删除school中的area键值对 (integer) 1
5、额外的危险操作(慎用)
获取redis数据库中所有的键(这个不危险) keys * 删除所有Key,可以使用Redis的flushdb和flushall命令(危险慎用) # 删除当前数据库中的所有Key flushdb # 删除所有数据库中的key flushall
四、redis发布者订阅者
发布者: PUBLISH channel msg 将信息 message 发送到指定的频道 channel 频道 channel 自定义频道的名字 订阅者: SUBSCRIBE channel [channel ...] 订阅频道,可以同时订阅多个频道 UNSUBSCRIBE [channel ...] 取消订阅指定的频道, 如果不指定频道,则会取消订阅所有频道 PSUBSCRIBE pattern [pattern ...] 订阅一个或多个符合给定模式的频道(正则匹配),每个模式以 * 作为匹配符, 比如 it* 匹配所有以 it 开头的频道( it.news 、 it.blog 、 it.tweets 等等), news.* 匹配所有以 news. 开头的频道( news.it 、 news.global.today 等等),诸如此类 PUNSUBSCRIBE [pattern [pattern ...]] 退订指定的规则, 如果没有参数则会退订所有规则 PUBSUB subcommand [argument [argument ...]] 查看订阅与发布系统状态 注意:使用发布订阅模式实现的消息队列,当有客户端订阅channel后只能收到后续发布到该频道的消息,之前发送的不会缓存,必须Provider和Consumer同时在线
五、redis数据持久化
redis的缺点:
redis数据放在内存中
重启服务器丢失数据
重启redis服务丢失数据
断电丢失数据
为了防止redis数据丢失,进行持久化,将数据,写入到一个文件中
1、redis持久化之RDB
redis提供了RDB持久化的功能,这个功能可以将redis在内存中的的状态保存到硬盘中,它可以手动执行。
也可以再redis.conf中配置,定期执行。
RDB持久化产生的RDB文件是一个经过压缩的二进制文件,这个文件被保存在硬盘中,redis可以通过这个文件还原数据库当时的状态。
RDB的原理是
基于内存的数据快照
定期执行数据快照
手动触发数据快照
Redis会将数据集的快照dump到dump.rdb文件中
可以通过配置文件来修改Redis服务器dump快照的频率
RDB优点:
速度快,适合做备份,主从复制就是基于RDB持久化功能实现
rdb通过在redis中使用save命令触发 rdb
1. 配置rdb数据持久化
1.在配置文件中,添加rdb持久化参数 vim redis-6379.conf 写入如下配置 port 6379 daemonize yes pidfile /data/6379/redis.pid loglevel notice logfile "/data/6379/redis.log" protected-mode yes dir /data/6379 # 定义持久化文件存储位置(rdb和aof) dbfilename dbmp.rdb # rdb持久化文件 save 900 1 # rdb机制 每900秒 如果至少有1个key发生变化,则dump内存快照(相当于手动save触发rdb持久化文件) save 300 10 # 在300秒(5分钟)之后,如果至少有10个key发生变化,则dump内存快照。 save 60 10000 # 在60秒(1分钟)之后,如果至少有10000个key发生变化,则dump内存快照。 2.触发rdb持久化,可以手动save命令,生成 dump.rdb持久化文件 3.重启redis,数据不再丢失 4. 测试 进入redis客户端 redis-cli 127.0.0.1:6379> set age 18 OK 127.0.0.1:6379> save OK 5.进入/data/6379查看是否生成了 dbmp.rdb 持久化文件 注意:rdb数据文件是二进制文件,人为的看不懂 6.kill掉redis进程,再重启,进入redis keys * 查看数据是否还在
2、redis持久化之aof
AOF(append-only log file)
记录服务器执行的所有变更操作命令(例如set del等),并在服务器启动时,通过重新执行这些命令来还原数据集
AOF 文件中的命令全部以redis协议的格式保存,新命令追加到文件末尾。
优点:最大程序保证数据不丢
缺点:日志记录非常大
1. 配置方式
1,在配置文件中,添加aof参数 参数解释: appendonly yes # 开启aof功能 # appendfsync选择一个策略写入配置文件即可,这里使用每分钟 appendfsync everysec # 每秒钟同步一次,该策略为AOF的缺省策略。 appendfsync always # 每次有数据修改发生时都会写入AOF文件。 appendfsync no # 从不同步。高效但是数据不会被持久化 配置如下: port 6379 daemonize yes pidfile /data/6379/redis.pid loglevel notice logfile "/data/6379/redis.log" protected-mode yes dir /data/6379 dbfilename dbmp.rdb save 900 1 save 300 10 save 60 10000 appendonly yes appendfsync everysec 2,重启redis数据库,加载aof功能 会在/data/6379目录下生成 appendonly.aof 文件 3,appendonly.aof 文件是人可以看懂的记录了sql操作的文件 4,测试 进入redis客户端 redis-cli 127.0.0.1:6379> set long 18 OK 5,进入/data/6379查看appendonly.aof 文件的内容 6,kill掉redis进程,再重启,进入redis keys * 查看数据是否还在
3、在不重启redis的情况下,切换rdb数据到aof数据中
1.配置redis支持rdb持久化 2.启动redis客户端,通过命令,临时切换到aof模式 127.0.0.1:6379> CONFIG set appendonly yes # 开启AOF功能 OK 127.0.0.1:6379> CONFIG SET save "" # 关闭RDB功能 OK 3.检查此时的数据持久化方式是rdb,还是aof,检查appendonly.aof文件,数据变动 tail -f appendonly.aof 4.此时aof还未永久生效,写入参数到配置文件 编辑redis-6379.conf 添加如下参数 appendonly yes appendfsync everysec
4、redis持久化方式有什么区别
rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能
aof:以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全,类似于mysql的binlog
六、redis主从同步实现
原理:
1. 从服务器向主服务器发送 SYNC 命令。
2. 接到 SYNC 命令的主服务器会调用BGSAVE 命令,创建一个 RDB 文件,并使用缓冲区记录接下来执行的所有写命令。
3. 当主服务器执行完 BGSAVE 命令时,它会向从服务器发送 RDB 文件,而从服务器则会接收并载入这个文件。
4. 主服务器将缓冲区储存的所有写命令发送给从服务器执行。
小知识:
1. 在开启主从复制的时候,使用的是RDB方式的,同步主从数据的
2. 同步开始之后,通过主库命令传播的方式,主动的复制方式实现
3. 2.8以后实现PSYNC的机制,实现断线重连
1、使用配置文件进行redis主从同步配置
准备三个redis数据库,redis支持多实例
三个配置文件,仅仅是端口的不同
在三个配置文件中,添加主从同步的参数,
三个配置文件参数是一样的,唯一不同的是,
在从库中需要指定它的主库是谁即可,
例如6380的配置
slaveof 127.0.0.1 6379 代表这个redis库是6379的从库
1. 三个配置文件参信息如下 # redis-6379.conf(主redis) port 6379 daemonize yes pidfile /data/6379/redis.pid loglevel notice logfile "/data/6379/redis.log" dir /data/6379 protected-mode yes dbfilename dbmp.rdb save 900 1 save 300 10 save 60 10000 # redis-6380.conf(从redis) port 6380 daemonize yes pidfile /data/6380/redis.pid loglevel notice logfile "/data/6380/redis.log" dir /data/6380 protected-mode yes dbfilename dbmp.rdb save 900 1 save 300 10 save 60 10000 slaveof 127.0.0.1 6379 # redis-6381.conf(从redis) port 6381 daemonize yes pidfile /data/6381/redis.pid loglevel notice logfile "/data/6381/redis.log" dir /data/6381 protected-mode yes dbfilename dbmp.rdb save 900 1 save 300 10 save 60 10000 slaveof 127.0.0.1 6379 2.启动三个redis实例 redis-server redis-6379.conf redis-server redis-6380.conf redis-server redis-6381.conf 3.查看主从同步身份 1,redis-cli -p 6379 info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6380,state=online,offset=28,lag=1 slave1:ip=127.0.0.1,port=6381,state=online,offset=28,lag=1 2,redis-cli -p 6380 info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 3,redis-cli -p 6381 info replication # Replication role:slave master_host:127.0.0.1 master_port:6379 4.测试 # 在6379主库 redis-cli -p 6379 127.0.0.1:6379> set uzi good OK # 在6380从库 redis-cli -p 6380 127.0.0.1:6380> get uzi "good" # 在6381从库 redis-cli -p 6381 127.0.0.1:6381> get uzi "good"
2、使用命令行进行redis主从同步配置
1. 6380/6381命令行 redis-cli -p 6380 127.0.0.1:6380> SLAVEOF 127.0.0.1 6379 #指明主库的地址 redis-cli -p 6381 127.0.0.1:6381> SLAVEOF 127.0.0.1 6379 #指明主库的地址 2. 检查主从状态 主库: 127.0.0.1:6379> info replication 从库: 127.0.0.1:6380> info replication 127.0.0.1:6381> info replication
3、如果我主库挂了怎么办
解决方案:手动切换主从身份,选举一个新的主库 1.干掉6379主库 redis-cli -p 6379 shutdown 2.在6380上关闭自己的slave身份 127.0.0.1:6380> slaveof no one 3.在6381上给与新的主人身份 127.0.0.1:6381> salveof 127.0.0.1 6380 4.修改完毕,还得修改配置文件,永久生效