标签:bytes 图片 des active nod decode 内置函数 解析 www
一、XPath
全称 XML Path Language 是一门在XML文档中 查找信息的语言 最初是用来搜寻XML文档的 但是它同样适用于HTML文档的搜索
XPath 的选择功能十分强大,它提供了非常简洁的路径选择表达式,另外还提供了超过100个内置函数,用于字符串,数值,时间的匹配
以及节点和序列的处理
XPath 于1999年11月16日成为W3C标准 被设计为供XSLT、XPointer、以及其它XML解析软件使用
1 <<< 2 常用规则 3 4 表达式 描述 5 6 nodename 选取此节点的所有子节点 7 / 从当前节点选取直接子节点 8 // 从当前节点选取子孙节点 9 . 选取当前节点 10 .. 选取当前节点的父节点 11 @ 选取属性 12 >>> 13 14 示例: //title[@lang=‘eng‘] 15 16 选取所有名称为title 同时属性为lang的值为eng的节点 通过Python的lxml库 利用XPath进行HTML解析
安装 lxml 1. pip install lxml 2. wheel方式安装 https://www.lfd.uci.edu/~gohlke/pythonlibs/
验证 python命令行下 import lxml 无报错信息 表示安装成功
实例:
from lxml import etree #导入lxml的etree模块 text=‘‘‘ <div> <ul> <li class="item-0"><a href="link1.html">first item</a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> ‘‘‘ html = etree.HTML(text)#调用HTML类 初始化 构造一个XPath解析对象 result = etree.tostring(html)#输出 HTML代码 print(result.decode(‘utf-8‘))#结果为bytes类型 用decode方法转化为str类型
也可以直接读取文本文件 例如:
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = etree.tostring(html) print(result.decode(‘utf-8‘))
一样可以打印结果
1.1所有节点
一般会用//开头的XPath规则来选取所有符合要求的节点
例如:
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//*‘) print(result)
*代表匹配所有节点 返回一个列表 每个元素是Element类型 其后是节点名
1.2指定节点
例如:
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li‘) print(result) print(result[0])#取出其中一个对象 利用索引值
1.3子节点
通过/或者// 查找元素子节点或子孙节点
例如: 查找li节点的所有直接子节点
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li/a‘) print(result)
ul获取所有子孙a节点
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//ul//a‘) print(result)
想象一下换成 //ul/a 结果会怎样
1.4父节点
例如: 获取href属性为link4.html的a节点 获取其父节点 在获取其class属性
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//a[@href="link4.html"]/../@class‘) print(result)
也可以通过parent:: 获取其父节点
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//a[@href="link4.html"]/parent::*/@class‘) print(result)
1.5属性过滤
选取class为item-0 的li节点
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li[@class="item-0"]‘) print(result)
1.6文本获取
用xpath中text()方法获取节点中的文本
例如 获取li节点中的文本
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li[@class="item-0"]/text()‘) #此处的含义是直接获取子节点 print(result)#返回结果为 换行符
两种方式 1.先选取a节点 在获取文本 2.使用//
1.
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li[@class="item-0"]/a/text()‘) print(result)#返回预期结果
2.
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li[@class="item-0"]//text()‘) print(result)#返回三个结果
1.7属性获取
示例 获取li节点下所有a节点的href属性
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li/a/@href‘) print(result)#注意 之前学的属性过滤是限制某个属性 class=“xxxx” 这里是获取某个节点某个属性的属性值 返回形式是列表
1.8属性多值匹配
示例 有时候某个节点的某个属性有多个值
from lxml import etree text=‘‘‘ <li class="li li-first"><a href="link.html">first item</a></li> ‘‘‘ html = etree.HTML(text) result = html.xpath(‘//li[@class="li"]/a/text()‘) print(result)#返回结果是[]
需要 contains()函数
from lxml import etree text=‘‘‘ <li class="li li-first"><a href="link.html">first item</a></li> ‘‘‘ html = etree.HTML(text) result = html.xpath(‘//li[contains(@class,"li")]/a/text()‘) print(result)#第一个参数传入属性名称 第二个参数传入属性值
1.9多属性匹配
示例 根据多个属性确定一个节点 通常需要同时匹配多个属性 可以使用and来连接
from lxml import etree text=‘‘‘ <li class="li li-first" name="item"><a href="link.html">first item</a></li> <li class="li li-first" name="item_s"><a href="link.html">second item</a></li> ‘‘‘ html = etree.HTML(text) result = html.xpath(‘//li[contains(@class,"li") and @name="item"]/a/text()‘) print(result)
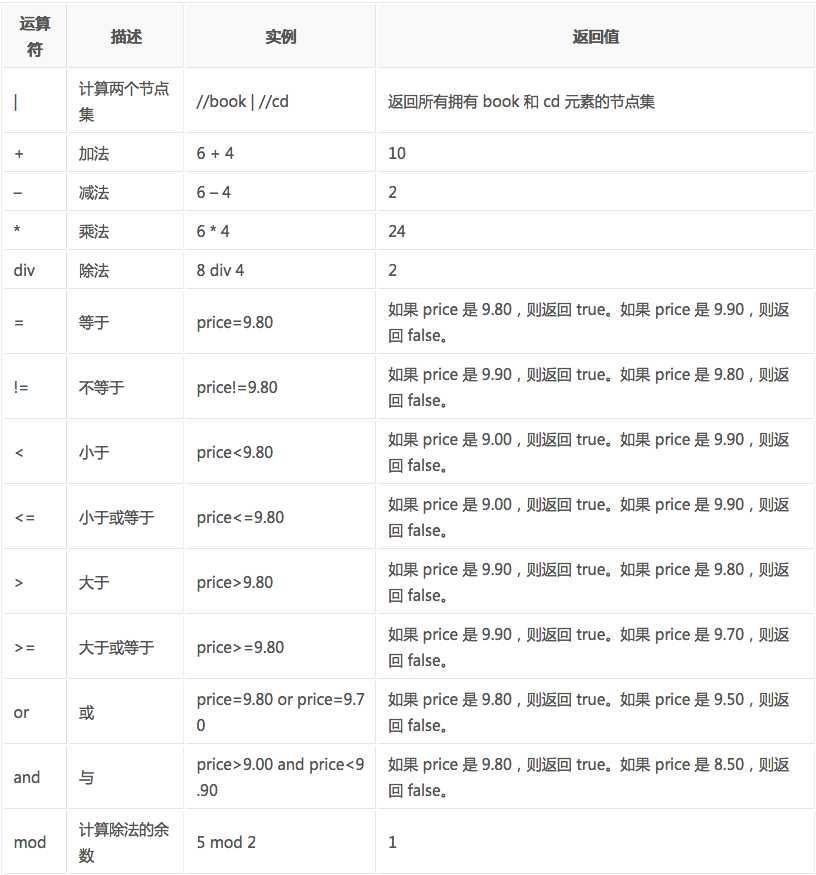
#还有很多运算符 详见xpath.png
1.10 按序选择
有时候选择某些属性 可能同时匹配了多个节点 但是想要其中某个节点
如 第一个节点或者最后一个节点
可以利用中括号传索引的方法
from lxml import etree html = etree.parse(‘./test.html‘,etree.HTMLParser()) result = html.xpath(‘//li[1]/a/text()‘) print(result)#返回第一个节点 注意这里序号是从1开始的 result = html.xpath(‘//li[last()]/a/text()‘) print(result)#返回最后一个节点 result = html.xpath(‘//li[position()<3]/a/text()‘) print(result)#返回前两个 result = html.xpath(‘//li[last()-2]/a/text()‘) print(result)#返回倒数第三个
xpath提供了100多个函数 包括存取 数值 字符串 逻辑 节点 序列等 参考资料 http://www.w3school.com.cn/xpath/xpath_functions.asp
1.11 节点轴选择
xpath提供了很多节点轴选择方法 包括子元素,兄弟元素,父元素,祖先元素等
实例:
from lxml import etree text=‘‘‘ <div> <ul> <li class="item-0"><a href="link1.html"><span>first item</span></a></li> <li class="item-1"><a href="link2.html">second item</a></li> <li class="item-inactive"><a href="link3.html">third item</a></li> <li class="item-1"><a href="link4.html">fourth item</a></li> <li class="item-0"><a href="link5.html">fifth item</a> </ul> </div> ‘‘‘ html = etree.HTML(text) result = html.xpath(‘//li[1]/ancestor::*‘) print(result)# 获取第一个li所有祖先节点 包括html body div ul result = html.xpath(‘//li[1]/ancestor::div‘) print(result)#限定条件 div result = html.xpath(‘//li[1]/attribute::*‘) print(result)#获取所有属性值 返回li节点所有属性值 result = html.xpath(‘//li[1]/child::a[@href="link1.html"]‘) print(result)#获取所有直接子节点 限定条件href = link1.html result = html.xpath(‘//li[1]/descendant::span‘) print(result)# 获取所有子孙节点 限定span节点 不包含a节点 result = html.xpath(‘//li[1]/following::*[2]‘) print(result)#获取当前节点之后的所有节点 虽然加了* 但又加了索引选择 只获取带第二个后续节点 result = html.xpath(‘//li[1]/following-sibling::*‘) print(result)#获取当前节点之后的所有同级节点
更多用法 参考 http://www.w3school.com.cn/xpath/xpath_axes.asp
标签:bytes 图片 des active nod decode 内置函数 解析 www
原文地址:https://www.cnblogs.com/liuxiaosong/p/10281513.html