标签:env 特征 ddb hadoop com header 多数据源 ogg 保存
1. flume的基础介绍 - Chukwa(Apache)
- Scribe(Facebook)
- Fluentd:Fluentd 使用 C/Ruby 开发,使用 JSON 文件来统一日 志数据。
- Logstash(著名的开源数据栈 ELK(ElasticSearch,Logstash,Kibana)中的那个 L)
- Flume(Apache):开源,高可靠,高扩展,容易管理,支持客户扩展的数据采集系统。
首先看一下hadoop业务的整体开发流程: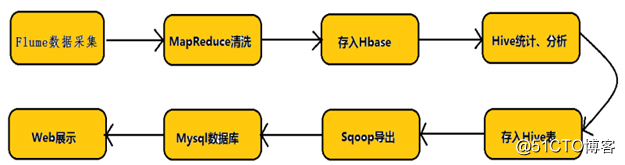
数据采集---数据清洗etl(数据抽取,转换,装载)---数据存储---数据计算分析---数据展现
其中数据采集是所有数据系统必不可少的,没有数据一切都是空谈。
那数据采集系统的特征又是什么呢?
- 构建应用系统和分析系统的桥梁,并将他们之间进行解耦(web---hadoop) 支持实时的在线分析系统和类似于hadoop之类的离线分析系统
- 具有高可扩展性,即:当数据增加时,可以通过增加节点进行水平扩展。
- Apache Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。和sqooq同属于数据采集系统组件,但是sqoop用来采集关系型数据库数据。而flume用来采集流动性数据。
- Flume 名字来源于原始的近乎实时的日志数据采集工具,现在被广泛用于任何流事件数 据的采集,它支持从很多数据源聚合数据到 HDFS。
- 一般的采集需求,通过对 flume 的简单配置即可实现。Flume 针对特殊场景也具备良好 的自定义扩展能力,因此,flume 可以适用于大部分的日常数据采集场景
- Flume 的优势:可横向扩展、延展性、可靠性
接下来以一个很简单的场景为例,将weserver的日志收集到hdfs中。
NG架构: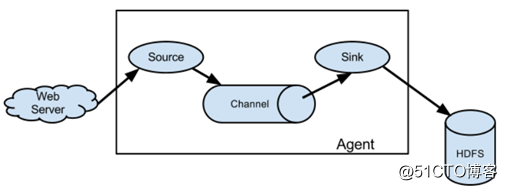
应用系统(web server)---flume的日志收集(source、channel、sink)----hdfs(数据存储)
其中:
source:数据源(读原始日志文件进行读取)
channel:数据通道(缓冲,缓解读写数据速度不一致问题)
sink:数据的目的地(收集到的数据写出到最终的目的地)
OG架构:(0.9以前)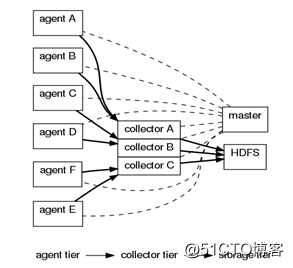
代理节点(agent) ----- 收集节点(collector)-----(master)主节点
Agent从各个数据源收集日志数据,将收集到的数据集中到collector,然后由收集节点汇总存入hdfs。Master负责管理agent和collector的活动。
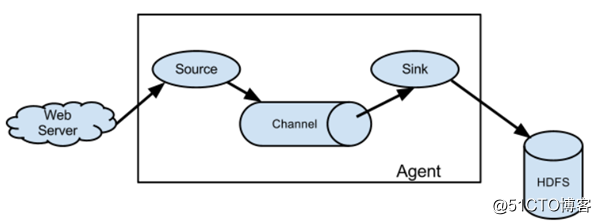
Flume的数据由事件(event)贯穿始终,事件是flume的基本数据单位,它携带日志数据(字节数组形式),并且携带有头信息,这些event由agent外部的source生成,当source捕获的事件后会进行特定的格式化,然后source会把事件推入(单个或多个)channel中。可以把 Channel 看作是一个缓冲区,它将保存事件直到 Sink 处理完该事件。Sink 负责持久化日志或 者把事件推向另一个 Source。
Flume以agent为最小的独立运行单位,一个agent就是一个jvm,单个agent由source、sink和channel三大组件构成。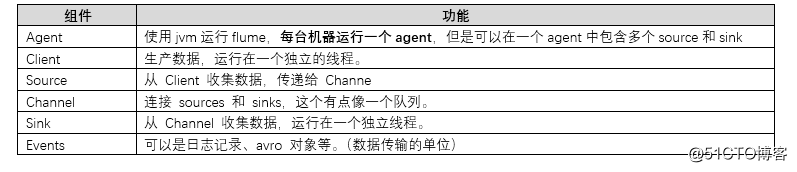
Event
Event是flume数据传输的基本单位。Flume以事件的形式将数据从源头,传送到最终的目的地。Event由可选的header和载有数据的一个byte array构成。Header 是容纳了 key-value 字符串对的无序集合,key 在集合内是唯一的。
agent
agent 是 flume 流的基础部分,一个 Agent 包含 source,channel,sink 和其他组件;利用这些组件将 events 从一个节点传输到另一个节点或最终目的地。
Source
Source负责接收event或者通过特殊机制产生event,并将events批量的放到一个或者多个channel中。
channel
Channel 位于 Source 和 Sink 之间,用于缓存进来的 event。当sink成功的将event发送到下一个的channel或者最终目的,event从channel删除。
Sink
Sink负责将event传输到下一个或者最终目的地,成功后将event从channel移除。
flume的搭建极为简单,基本上就是解压即可,但是由于我们经常将flume和大数据平台联系,所以需要我们将hadoop和jdk的环境搭建成功。
安装
- 上传安装包
- 解压安装包
- 配置环境变量
- 修改配置文件:
[hadoop @hadoop01 ~]cd /application/flume/conf
[hadoop @hadoop01 ~]mv flume-env.sh.template flume-env.sh
[hadoop @hadoop01 ~]vim flume-env.sh
export JAVA_HOME=/application/jdk1.8 (修改这一个就行) -测试是否安装成功
[hadoop @hadoop01 ~]flume-ng version
看见以上的结果表示安装成功!!!!
注意:一般的需要在哪台机器中采集数据,就在哪台机器中安装flume
flume的一切操作都是基于配置文件,所以,必须写配置文件。(必须是以.conf或者.properties结尾)。
更多 Sources:http://flume.apache.org/FlumeUserGuide.html#flume-sources
更多 Channels:http://flume.apache.org/FlumeUserGuide.html#flume-channels
更多 Sinks:http://flume.apache.org/FlumeUserGuide.html#flume-sinks
这里我们以一个非常简单的案例,介绍flume如何使用: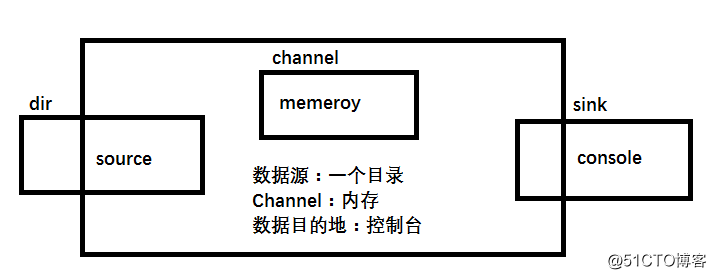
配置文件:
#example.conf
#这里的a1指的是agent的名字,可以自定义,但注意:同一个节点下的agent的名字不能相同
#定义的是sources、sinks、channels的别名
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#指定source的类型和相关的参数
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /home/hadoop/flumedata #监听一个文件夹
#设定channel
a1.channels.c1.type = memory
#设定sink
a1.sinks.k1.type = logger
#Bind the source and sink to the channel
#设置sources的通道
a1.sources.r1.channels = c1
#设置sink的通道
a1.sinks.k1.channel = c1准备测试环境:
创建一个目录:a1.sources.r1.spoolDir = /home/hadoop/flumedata
启动命令:
flume-ng agent --conf conf --conf-file /home/hadoop/example.conf --name a1 -Dflume.root.logger=INFO,console然后移动一个有内容的文件到flume监听的文件夹下(/home/hadoop/flumedata):
查看 此时窗口的状态:
内容成功收集!!
标签:env 特征 ddb hadoop com header 多数据源 ogg 保存
原文地址:http://blog.51cto.com/14048416/2343709