标签:编辑 基于 自动 操作 软件 虚拟机启动 管理员 用户名 网关
【目的】:学习大数据
在此记录搭建大数据的过程。
【系统环境】
宿主机操作系统:Win7 64位
虚拟机软件:Vmware workstation 12
虚拟机:Ubuntu 16 64位桌面版
【搭建过程】
一、准备
1、安装文件准备
Hadoop软件:
JDK:
Ubuntu 16的安装软件
2、虚拟机准备
测试计划使用三台虚拟机
在Win7里启动Vmware workstation,安装一台操作系统为Ubuntu 16的空的虚拟机,从这台虚拟机另外再克隆出来两台
3、机器名称:hadoop.master、hadoop.slave1、hadoop.slave2
通过修改/etc/hostname来设置虚拟机的主机名称
#vi /etc/hostname

4、查看和确定网关,我这测试环境的网关是:192.168.152.2
5、规划三台虚拟机的IP:192.168.152.21、192,168.152.22、192.168.152.153
6、修改/etc/hosts,修改hosts文件目的是为了这三台虚拟机可以通过机器名称互相访问
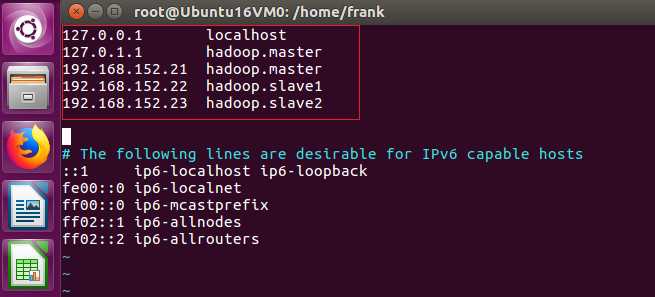
7、为虚拟机设置静态IP
只所以设置为静态IP,是因为虚拟机启动后,有时会自动变更IP,而在搭建的大数据环境里,会配置IP地址,动态变化后,会出现IP地址不匹配。
8、增加user,这个用户专用于操作hadoop
1)、这里用户名设为:hadoop
#useradd hadoop
2)、为增加的账号设置口令
#passwd hadoop
3)、把新增的这个用户设为管理员,编辑/etc/sudoers
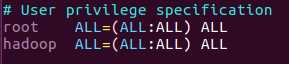
注意:Tab键的使用
9、
二、设置免密登录
三、安装和配置Java环境
四、安装和配置Hadoop
标签:编辑 基于 自动 操作 软件 虚拟机启动 管理员 用户名 网关
原文地址:https://www.cnblogs.com/SH170706/p/10281842.html