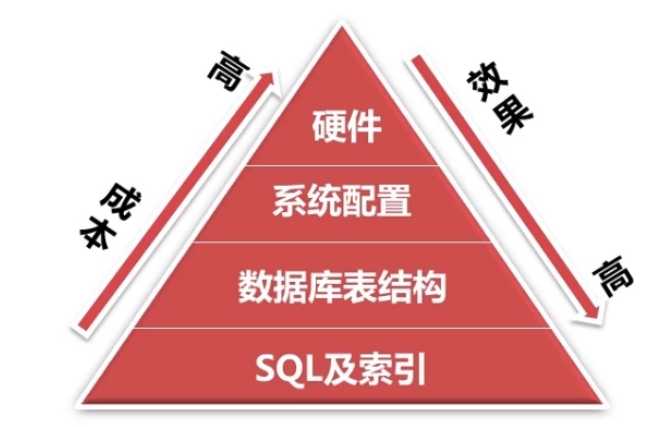
索引优化:
- 在where从句,group by从句,order by从句,on从句中出现的列
- 索引字段越小越好
- 离散度大的列放在联合索引的前面
eg:select count(distinct customer_id),count(distinct staff_id) from payment;
查询结果:customer_id 599 staff_id 2
由于customer_id的离散度更大,所以应该使用 index(customer_id,staff_id)
select
a.TABLE_SCHEMA AS ‘数据名‘,
a.TABLE_NAME AS ‘表名‘,
a.INDEX_NAME AS ‘索引1‘,
b.INDEX_NAME AS ‘索引2‘,
a.COLUMN_NAME as ‘重复列名‘
from STATISTICS a JOIN STATISTICS b ON
a.TABLE_SCHEMA = b.TABLE_SCHEMA
AND a.TABLE_NAME = b.TABLE_NAME
AND a.SEQ_IN_INDEX = b.SEQ_IN_INDEX
AND a.COLUMN_NAME = b.COLUMN_NAME;
数据库表结构
目前说到的范式化一般指第三设计范式,也就是要求数据表中不存在非关键字段对任意候选关键字段的传递函数依赖
反范式指为了提高查询效率适当增加一些冗余,是一种空间换时间的操作
就是把原来一个有很多列的表拆分成多个表,拆分原则:
- 把不常用的字段单独存放到一个表中
- 把大字段独立存放到一个表中
- 把经常用到的字段放到一起
表的水平拆分是为了解决单表的数据量过大的问题,水平拆分的表每一个表的结构都是完全一致的
拆分方式:
- 对 id 进行hash运算,如果要拆分成5个表,则使用摸底(id,5)取出0~4个值
- 针对不同的hashID把数据存到不同的表中
系统配置
网络方面的配置,要修改 /etc/sysctl.conf
#增加tcp支持的队列数
net.ipv4.tcp_max_syn_backlog=65535
#减少断开连接时,资源回收
net.ipv4.tcp_max_tw_buckets=8000
bet.ipv4.tcp_tw_reuse=1
net.ipv4.tcp_tw_recycle=1
net.ipv4.tcp_fin_timeout=10
#打开文件数的限制 /etc/security/limits.conf
* soft nofile 65535
* hard nofile 65535
关闭 iptables 等防火墙
Mysql 的配置
SELECT engine,ROUND(SUM(data_length+index_length)/1024/2014,1) AS "Total MB" FROM INFORMATION_SCHEMA.TABLES WHERE table_schema not in ("information_schema","performance_schema") GROUP BY ENGINE; #系统中每一种引擎表的大小
innodb_buffer_pool_size #重要,缓冲池的大小 推荐总内存量的75%,越大越好。
innodb_buffer_pool_instances #该参数可以控制缓冲池的个数,默认只有一个缓冲池,如果一个缓冲池中并发量过大,容易阻塞,此时可以分为多个缓冲池;
innodb_log_buffer_size #innodb log 缓冲大小,由缓冲区刷新到磁盘,由于日志最长每秒钟就会刷新所以一般不用太大
innodb_flush_log_at_trx_commit #关键,数据库多长时间把数据刷新到磁盘,默认值为1,可取0,1,2三个值,0表示每一秒钟把变更刷新到磁盘,1表示每一次提交会把变更刷新到磁盘,2表示每一次提交刷新到缓冲区然后每一秒从缓冲区刷新到磁盘,建议设置为2,如果数据安全性要求较高则使用默认值1
innodb_read_io_threads #Innodb读IO进程数,默认为4
innodb_write_io_threads #Innodb 写IO 进程数,默认为4
innodb_file_per_table #on表示每个表使用独立的表空间,默认为 off,也就是所有的表都会建立在共享表空间上,设为on可提高并发效率
innodb_stats_on_metadata # 决定Mysql在什么情况下会刷新innodb表的统计信息,一般关掉
硬件
如何选择CPU
一般选择单核更快的CPU,并且并不要求核数太多,32核,内存64G 足矣
磁盘IO 优化
常用RAID 级别简介
RAID0:也称条带,就是把多个磁盘链接成一个硬盘使用,这个级别IO最好
RAID1:也称镜像,要求至少有两个磁盘,每组磁盘存储的数据相同
RAID5:也是把多个(最少3个)硬盘合并成1个逻辑磁盘使用,数据读写时会建立奇偶校验信息,并把奇偶校验信息和相对应的数据分别存储于不同的磁盘上。当RAID5的一个磁盘数据发生损坏后,利用剩下的数据和相应的奇偶校验信息去恢复损坏的数据
RAID1+0:也就是RAID1和RAID0的结合。同时具有两个级别的优点。一般建议数据库使用这个级别