标签:src 实时监控 不同 temp 自己 app 自我 大型 不成功
至此,我们已实现服务发现、负载均衡,同时,使用Feign也实现了良好的远程调用——我们的代码是可读、可维护的。理论上,我们现在已经能构建一个不错的分布式应用了,但微服务之间是通过网络通信的,网络可能出问题;微服务本身也不可能100%可用。如何提升应用的可用性呢?这是我们必须考虑的问题——
举个例子:某大型系统中,服务A调用服务B,某个时刻,微服务B突然崩溃了。微服务A中,依然有大量请求在请求B,如果没有任何措施,微服务A很可能很快就会被拖死——因为在Java中,一次请求往往对应着一个线程,如果不做任何措施,那意味着微服务A请求B的线程要等Feign Client/RestTemplate超时才会释放(这个时间一般非常长,长达几十秒),于是就会有大量的线程被阻塞,而线程又对应着计算资源(CPU/内存),于是乎,大量的资源被浪费,并且越积越多,最终服务器终于没有资源给微服务A浪费了,微服务A也挂了。
因此,在大型应用中,微服务之间的容错必不可少,下面来讨论如何实现微服务的容错。
超时机制你懂的,配置一下超时时间,例如1秒——每次请求在1秒内必须返回,否则到点就把线程掐死,释放资源!
思路:一旦超时,就释放资源。由于释放资源速度较快,应用就不会那么容易被拖死。
有兴趣的可以先了解一下船舱构造——一般来说,现代的轮船都会分很多舱室,舱室之间用钢板焊死,彼此隔离。这样即使有某个/某些船舱进水,也不会影响其他舱室,浮力够,船不会沉。
软件世界里的仓壁模式可以这样理解:M类使用线程池1,N类使用线程池2,彼此的线程池不同,并且为每个类分配的线程池较小,例如coreSize=10。举个例子:M类调用B服务,N类调用C服务,如果M类和N类使用相同的线程池,那么如果B服务挂了,M类调用B服务的接口并发又很高,你又没有任何保护措施,你的服务就很可能被M类拖死。而如果M类有自己的线程池,N类也有自己的线程池,如果B服务挂了,M类顶多是将自己的线程池占满,不会影响N类的线程池——于是N类依然能正常工作,
思路:不把鸡蛋放在一个篮子里。你有你的线程池,我有我的线程池,你的线程池满了和我没关系,你挂了也和我没关系。
现实世界的断路器大家肯定都很了解,每个人家里都会有断路器。断路器实时监控电路的情况,如果发现电路电流异常,就会跳闸,从而防止电路被烧毁。
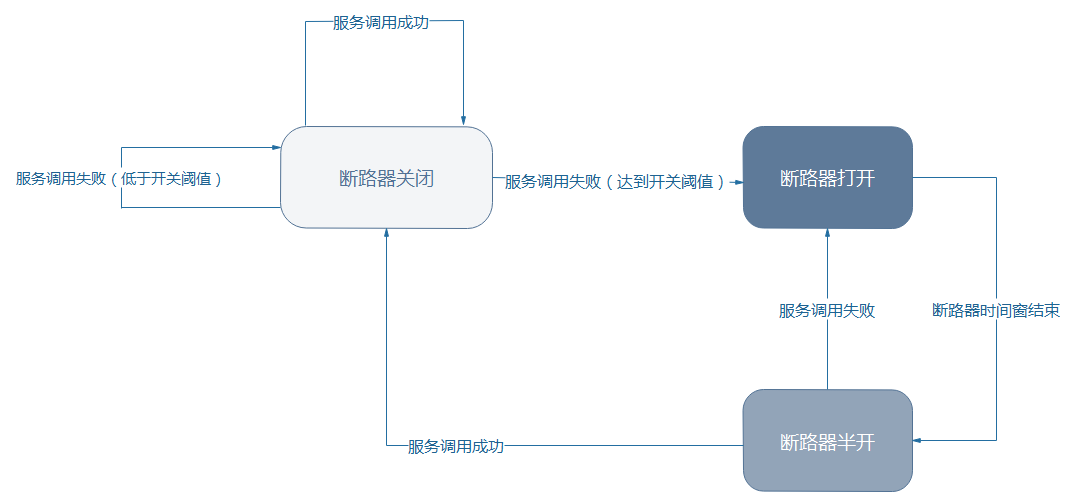
软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路器打开——此时,请求直接返回,而不去调用原本调用的逻辑。
跳闸一段时间后(例如15秒),断路器会进入半开状态,这是一个瞬间态,此时允许一次请求调用该调的逻辑,如果成功,则断路器关闭,应用正常调用;如果调用依然不成功,断路器继续回到打开状态,过段时间再进入半开状态尝试——通过”跳闸“,应用可以保护自己,而且避免浪费资源;而通过半开的设计,可实现应用的“自我修复“。
TIPS:
断路器的提出人也是Martin Fowler,”微服务“这个名词被广泛了解,也和他有密不可分的关系。Martin Fowler的博客:http://www.martinfowler.com 。
断路器状态转换可如下图所示:
本文较短,但相信已经用通俗的语言讲解了常见的几种容错机制——目前Spring Cloud生态中,支持的断路器有:Hystrix、Resilience4J、Alibaba Sentinel,虽然彼此实现有较大差异,但本质原理是相通的。
本节是断路器的基石,在理解原理后,你会发现用不同的实现只是使用的依赖和注解不大一样而已。
下一节,将着重讲解如何使用Hystrix实现微服务的容错。

跟我学Spring Cloud(Finchley版)-12-微服务容错三板斧
标签:src 实时监控 不同 temp 自己 app 自我 大型 不成功
原文地址:http://blog.51cto.com/10180481/2343992