标签:内存分配 语言 多层 也会 时间 依次 getconf 实现 也有
内存是计算机的主存储器。内存为进程开辟出进程空间,让进程在其中保存数据。我将从内存的物理特性出发,深入到内存管理的细节,特别是了解虚拟内存和内存分页的概念。
简单地说,内存就是一个数据货架。内存有一个最小的存储单位,大多数都是一个字节。内存用内存地址(memory address)来为每个字节的数据顺序编号。因此,内存地址说明了数据在内存中的位置。内存地址从0开始,每次增加1。这种线性增加的存储器地址称为线性地址(linear address)。为了方便,我们用十六进制数来表示内存地址,比如0x00000003、0x1A010CB0。这里的“0x”用来表示十六进制。“0x”后面跟着的,就是作为内存地址的十六进制数。
内存地址的编号有上限。地址空间的范围和地址总线(address bus)的位数直接相关。CPU通过地址总线来向内存说明想要存取数据的地址。以英特尔32位的80386型CPU为例,这款CPU有32个针脚可以传输地址信息。每个针脚对应了一位。如果针脚上是高电压,那么这一位是1。如果是低电压,那么这一位是0。32位的电压高低信息通过地址总线传到内存的32个针脚,内存就能把电压高低信息转换成32位的二进制数,从而知道CPU想要的是哪个位置的数据。用十六进制表示,32位地址空间就是从0x00000000 到0xFFFFFFFF。
内存的存储单元采用了随机读取存储器(RAM, Random Access Memory)。所谓的“随机读取”,是指存储器的读取时间和数据所在位置无关。与之相对,很多存储器的读取时间和数据所在位置有关。就拿磁带来说,我们想听其中的一首歌,必须转动带子。如果那首歌是第一首,那么立即就可以播放。如果那首歌恰巧是最后一首,我们快进到可以播放的位置就需要花很长时间。我们已经知道,进程需要调用内存中不同位置的数据。如果数据读取时间和位置相关的话,计算机就很难把控进程的运行时间。因此,随机读取的特性是内存成为主存储器的关键因素。
内存提供的存储空间,除了能满足内核的运行需求,还通常能支持运行中的进程。即使进程所需空间超过内存空间,内存空间也可以通过少量拓展来弥补。换句话说,内存的存储能力,和计算机运行状态的数据总量相当。内存的缺点是不能持久地保存数据。一旦断电,内存中的数据就会消失。因此,计算机即使有了内存这样一个主存储器,还是需要硬盘这样的外部存储器来提供持久的储存空间。
内存的一项主要任务,就是存储进程的相关数据。我们之前已经看到过进程空间的程序段、全局数据、栈和堆,以及这些这些存储结构在进程运行中所起到的关键作用。有趣的是,尽管进程和内存的关系如此紧密,但进程并不能直接访问内存。在Linux下,进程不能直接读写内存中地址为0x1位置的数据。进程中能访问的地址,只能是虚拟内存地址(virtual memory address)。操作系统会把虚拟内存地址翻译成真实的内存地址。这种内存管理方式,称为虚拟内存(virtual memory)。
每个进程都有自己的一套虚拟内存地址,用来给自己的进程空间编号。进程空间的数据同样以字节为单位,依次增加。从功能上说,虚拟内存地址和物理内存地址类似,都是为数据提供位置索引。进程的虚拟内存地址相互独立。因此,两个进程空间可以有相同的虚拟内存地址,如0x10001000。虚拟内存地址和物理内存地址又有一定的对应关系,如图1所示。对进程某个虚拟内存地址的操作,会被CPU翻译成对某个具体内存地址的操作。
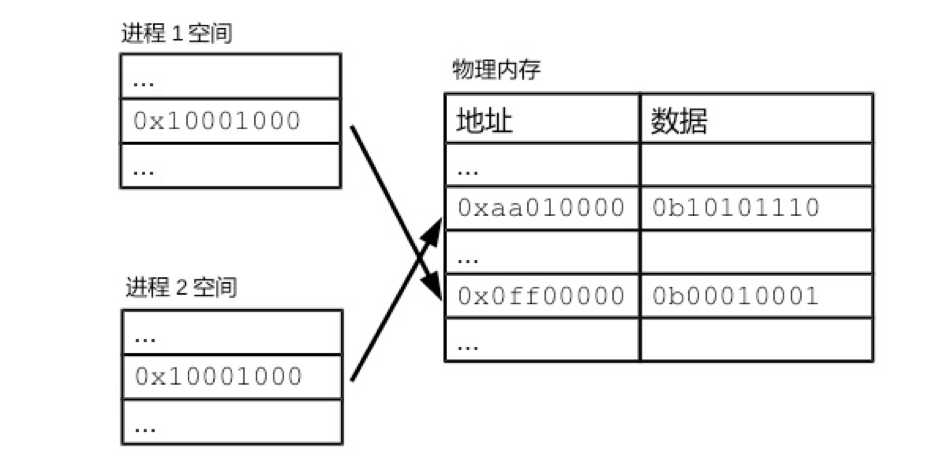
图1 虚拟内存地址和物理内存地址的对应
应用程序来说对物理内存地址一无所知。它只可能通过虚拟内存地址来进行数据读写。程序中表达的内存地址,也都是虚拟内存地址。进程对虚拟内存地址的操作,会被操作系统翻译成对某个物理内存地址的操作。由于翻译的过程由操作系统全权负责,所以应用程序可以在全过程中对物理内存地址一无所知。因此,C程序中表达的内存地址,都是虚拟内存地址。比如在C语言中,可以用下面指令来打印变量地址:
int v = 0;
printf("%p", (void*)&v);
本质上说,虚拟内存地址剥夺了应用程序自由访问物理内存地址的权利。进程对物理内存的访问,必须经过操作系统的审查。因此,掌握着内存对应关系的操作系统,也掌握了应用程序访问内存的闸门。借助虚拟内存地址,操作系统可以保障进程空间的独立性。只要操作系统把两个进程的进程空间对应到不同的内存区域,就让两个进程空间成为“老死不相往来”的两个小王国。两个进程就不可能相互篡改对方的数据,进程出错的可能性就大为减少。
另一方面,有了虚拟内存地址,内存共享也变得简单。操作系统可以把同一物理内存区域对应到多个进程空间。这样,不需要任何的数据复制,多个进程就可以看到相同的数据。内核和共享库的映射,就是通过这种方式进行的。每个进程空间中,最初一部分的虚拟内存地址,都对应到物理内存中预留给内核的空间。这样,所有的进程就可以共享同一套内核数据。共享库的情况也是类似。对于任何一个共享库,计算机只需要往物理内存中加载一次,就可以通过操纵对应关系,来让多个进程共同使用。IPO中的共享内存,也有赖于虚拟内存地址。
虚拟内存地址和物理内存地址的分离,给进程带来便利性和安全性。但虚拟内存地址和物理内存地址的翻译,又会额外耗费计算机资源。在多任务的现代计算机中,虚拟内存地址已经成为必备的设计。那么,操作系统必须要考虑清楚,如何能高效地翻译虚拟内存地址。
记录对应关系最简单的办法,就是把对应关系记录在一张表中。为了让翻译速度足够地快,这个表必须加载在内存中。不过,这种记录方式惊人地浪费。如果树莓派1GB物理内存的每个字节都有一个对应记录的话,那么光是对应关系就要远远超过内存的空间。由于对应关系的条目众多,搜索到一个对应关系所需的时间也很长。这样的话,会让树莓派陷入瘫痪。
因此,Linux采用了分页(paging)的方式来记录对应关系。所谓的分页,就是以更大尺寸的单位页(page)来管理内存。在Linux中,通常每页大小为4KB。如果想要获取当前树莓派的内存页大小,可以使用命令:
$getconf PAGE_SIZE
得到结果,即内存分页的字节数:
4096
返回的4096代表每个内存页可以存放4096个字节,即4KB。Linux把物理内存和进程空间都分割成页。
内存分页,可以极大地减少所要记录的内存对应关系。我们已经看到,以字节为单位的对应记录实在太多。如果把物理内存和进程空间的地址都分成页,内核只需要记录页的对应关系,相关的工作量就会大为减少。由于每页的大小是每个字节的4000倍。因此,内存中的总页数只是总字节数的四千分之一。对应关系也缩减为原始策略的四千分之一。分页让虚拟内存地址的设计有了实现的可能。
无论是虚拟页,还是物理页,一页之内的地址都是连续的。这样的话,一个虚拟页和一个物理页对应起来,页内的数据就可以按顺序一一对应。这意味着,虚拟内存地址和物理内存地址的末尾部分应该完全相同。大多数情况下,每一页有4096个字节。由于4096是2的12次方,所以地址最后12位的对应关系天然成立。我们把地址的这一部分称为偏移量(offset)。偏移量实际上表达了该字节在页内的位置。地址的前一部分则是页编号。操作系统只需要记录页编号的对应关系。
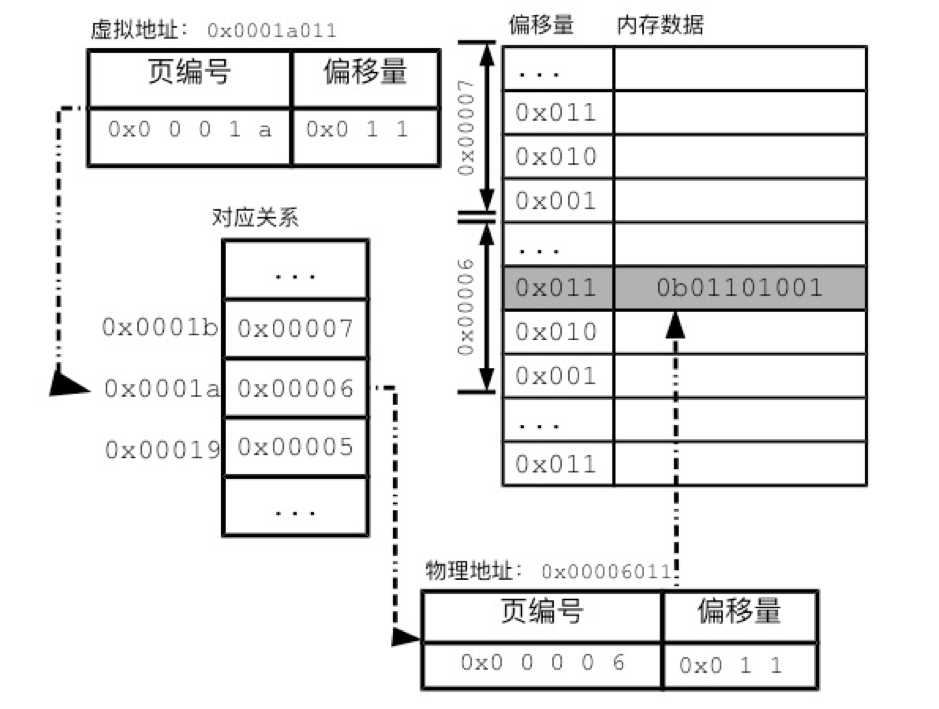
图2 地址翻译过程
内存分页制度的关键,在于管理进程空间页和物理页的对应关系。操作系统把对应关系记录在分页表(page table)中。这种对应关系让上层的抽象内存和下层的物理内存分离,从而让Linux能灵活地进行内存管理。由于每个进程会有一套虚拟内存地址,那么每个进程都会有一个分页表。为了保证查询速度,分页表也会保存在内存中。分页表有很多种实现方式,最简单的一种分页表就是把所有的对应关系记录到同一个线性列表中,即如图2中的“对应关系”部分所示。
这种单一的连续分页表,需要给每一个虚拟页预留一条记录的位置。但对于任何一个应用进程,其进程空间真正用到的地址都相当有限。我们还记得,进程空间会有栈和堆。进程空间为栈和堆的增长预留了地址,但栈和堆很少会占满进程空间。这意味着,如果使用连续分页表,很多条目都没有真正用到。因此,Linux中的分页表,采用了多层的数据结构。多层的分页表能够减少所需的空间。
我们来看一个简化的分页设计,用以说明Linux的多层分页表。我们把地址分为了页编号和偏移量两部分,用单层的分页表记录页编号部分的对应关系。对于多层分页表来说,会进一步分割页编号为两个或更多的部分,然后用两层或更多层的分页表来记录其对应关系,如图3所示。
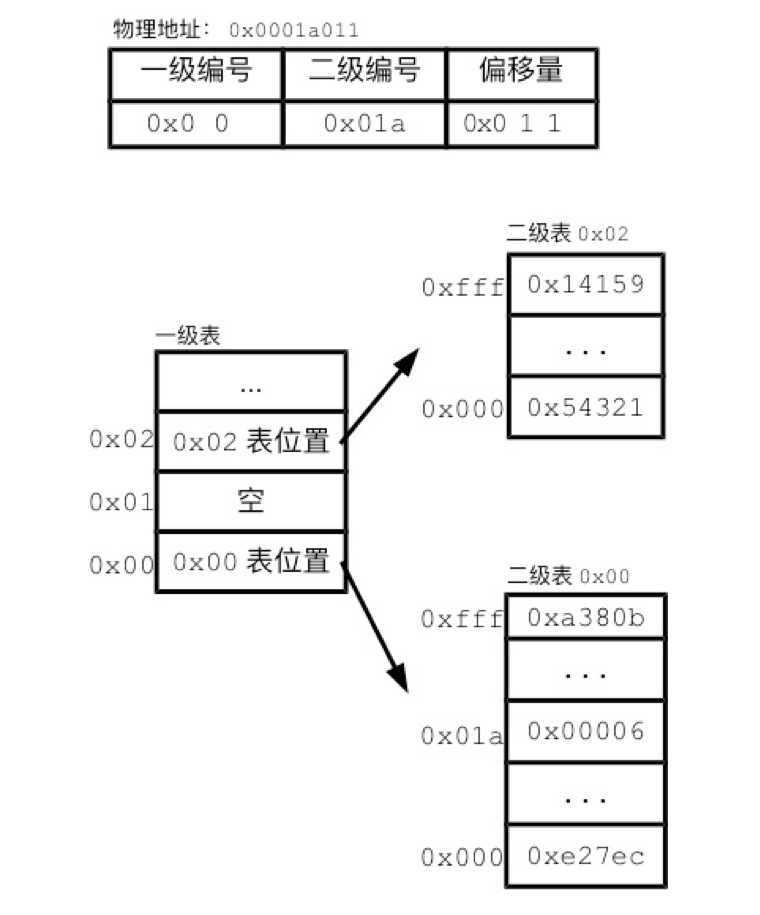
图3 多层分页表
在图3的例子中,页编号分成了两级。第一级对应了前8位页编号,用2个十六进制数字表示。第二级对应了后12位页编号,用3个十六进制编号。二级表记录有对应的物理页,即保存了真正的分页记录。二级表有很多张,每个二级表分页记录对应的虚拟地址前8位都相同。比如二级表0x00,里面记录的前8位都是0x00。翻译地址的过程要跨越两级。我们先取地址的前8位,在一级表中找到对应记录。该记录会告诉我们,目标二级表在内存中的位置。我们再在二级表中,通过虚拟地址的后12位,找到分页记录,从而最终找到物理地址。
多层分页表就好像把完整的电话号码分成区号。我们把同一地区的电话号码以及对应的人名记录同通一个小本子上。再用一个上级本子记录区号和各个小本子的对应关系。如果某个区号没有使用,那么我们只需要在上级本子上把该区号标记为空。同样,一级分页表中0x01记录为空,说明了以0x01开头的虚拟地址段没有使用,相应的二级表就不需要存在。正是通过这一手段,多层分页表占据的空间要比单层分页表少了很多。
多层分页表还有另一个优势。单层分页表必须存在于连续的内存空间。而多层分页表的二级表,可以散步于内存的不同位置。这样的话,操作系统就可以利用零碎空间来存储分页表。还需要注意的是,这里简化了多层分页表的很多细节。最新Linux系统中的分页表多达3层,管理的内存地址也比本章介绍的长很多。不过,多层分页表的基本原理都是相同。
综上,我们了解了内存以页为单位的管理方式。在分页的基础上,虚拟内存和物理内存实现了分离,从而让内核深度参与和监督内存分配。应用进程的安全性和稳定性因此大为提高。
标签:内存分配 语言 多层 也会 时间 依次 getconf 实现 也有
原文地址:https://www.cnblogs.com/qq_841161825/p/10288025.html