标签:gen 包含 time 简单 分析 源代码 过程 取数 .ajax
有时候在抓取页面的时候,我们得到的结果和浏览器中看到的的结果是不一样的。在浏览器中可以正常看到的界面,使用requests不能够正确的得到。这是因为requests得到的是原始的html文档,而浏览器的页面则是经过JavaScript处理后生成的数据,这些数据的来源很多,其中有一种是使用Ajax技术加载的。还有另外两种是经过JavaScript和特定算法生成的。以及包含在html文档中的。
对于Ajax方式的数据加载方式,它是一种异步加载的方式,原始页面最初的时候不会包含某些数据。而是在加载完成后,向接口请求新的数据,然后呈现在网页上面。
从发展趋势来看,AJax加载的页面现在是越来越多,因为这样做可以做到前后端分离,减轻服务器的压力。我们直接抓取原始页面是不能得到我们想要的结果的。
1.什么是Ajax
Ajax,全称是异步的JavaScript和xml,不是一门专门的编程语言,而是利用JavaScript在保证页面不被整体刷新的情况下与服务器交换数据并且更新部分网页显示的技术。例如在逛淘宝的时候,我们可以发现在网页下滑时可以看到最新的内容,这个加载的过程就是Ajax加载的过程。发送Ajax请求到网页更新的过程中,简单来说可以分为3步:发送请求,解析内容、渲染页面。
2.Ajax解析方法
2.1查看Ajax请求
要查看请求,需要借助浏览器的开发者工具。例如在360浏览其中打开头条网(https://www.toutiao.com/),按下F12进入开发者模式。如下图所示。
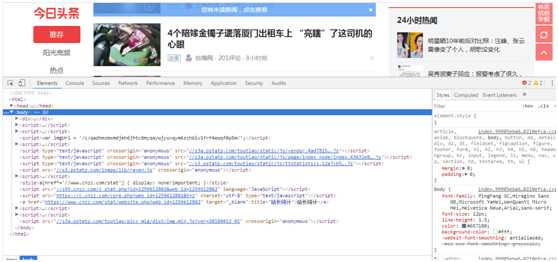
此时的Elements选项中出现的就是网页的源代码,不过这不是我们需要的内容。切换到Network选项,重新刷新网页,可以发现出现了非常多的请求,如下图所示。
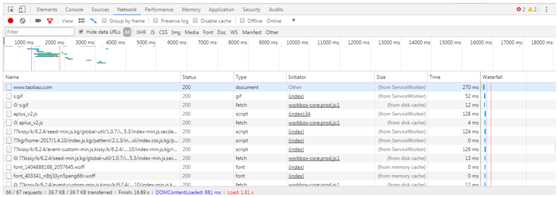
2.2过滤Ajax请求
在这个页面中,Ajax拥有特殊的请求类型,叫做XHR。在此页面中选择过滤条件为XHR,此时在页面中显示的都是Ajax请求了。然后在头条的界面中不断滑动页面,在开发者工具中也会实时刷新一条条Ajax请求。
随便点开一条记录,都可以清楚的看到它自身的request 、Headers信息和response信息,此时如果想要模拟Ajax请求,只需要清楚url中各参数的含义就可以了。如下图所示,下图为Ajax请求某一页的信息。
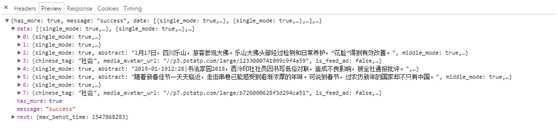
3.Ajax结果提取
3.1 分析请求
打开Ajax的XHR过滤器,然后一直滑动页面加载新的内容,看到开发者工具中不断出现新的请求,选定其中一个请求,查看并且分析它的参数信息,如下图所示。
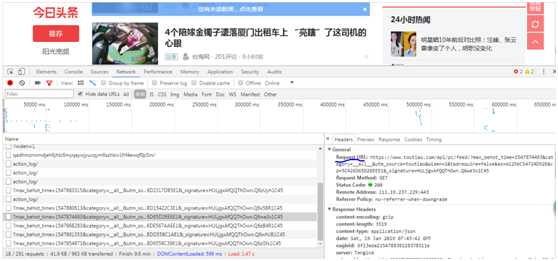
可以看到,这是一个get类型的请求,请求的真实url为:https://www.toutiao.com/api/pc/feed/?max_behot_time=1547874493&category=__all__&utm_source=toutiao&widen=1&tadrequire=false&as=A1256C54724D52E&cp=5C426D65D26EEE1&_signature=HULjgxAfQQThOwn.Q6we3x1C45。查看其他ajax请求的的真实url,找到这些url之间的规律,就可以批量的获取Ajax请求的数据了。查找规律的事情等以后更新的时候再说。
3.2使用Python爬取数据
import requests,json url = ‘https://www.toutiao.com/api/pc/feed/?max_behot_time=1547854873&category=__all__&utm_source=toutiao&widen=1&tadrequire=true&as=A1E58C14928D583&cp=5C428D6558C39E1&_signature=HULjgxAfQQThOwn.Q6zGfx1C45‘ header = {‘user-agent‘:‘Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36‘, ‘referer: https‘: ‘// www.toutiao.com /‘, } r = requests.get(url,headers = header) print(r.json()) ‘‘‘ 解析代码略 ‘‘‘
标签:gen 包含 time 简单 分析 源代码 过程 取数 .ajax
原文地址:https://www.cnblogs.com/wl443587/p/10292150.html