标签:obj this 入口 nbsp 匹配 .com ted 定义排序 inf
一、自定义排序规则-封装类
import org.apache.spark.rdd.RDD import org.apache.spark.{SparkConf, SparkContext} /** * 实现自定义的排序 */ object MySort1 { def main(args: Array[String]): Unit = { //1.spark程序的入口 val conf: SparkConf = new SparkConf().setAppName("MySort1").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) //2.创建数组 val girl: Array[String] = Array("Mary,18,80","Jenny,22,100","Joe,30,80","Tom,18,78") //3.转换RDD val grdd1: RDD[String] = sc.parallelize(girl) //4.切分数据 val grdd2: RDD[Girl] = grdd1.map(line => { val fields: Array[String] = line.split(",") //拿到每个属性 val name = fields(0) val age = fields(1).toInt val weight = fields(2).toInt //元组输出 //(name, age, weight) new Girl(name, age, weight) }) // val sorted: RDD[(String, String, Int)] = grdd2.sortBy(t => t._2, false) // val r: Array[(String, String, Int)] = sorted.collect() // println(r.toBuffer) val sorted: RDD[Girl] = grdd2.sortBy(s => s) val r = sorted.collect() println(r.toBuffer) sc.stop() } } //自定义类 scala Ordered class Girl(val name: String, val age: Int, val weight: Int) extends Ordered[Girl] with Serializable { override def compare(that: Girl): Int = { //如果年龄相同 体重重的往前排 if(this.age == that.age){ //如果正数 正序 负数 倒序 -(this.weight - that.weight) }else{ //年龄小的往前排 this.age - that.age } } override def toString: String = s"名字:$name,年龄:$age,体重:$weight" }
结果:
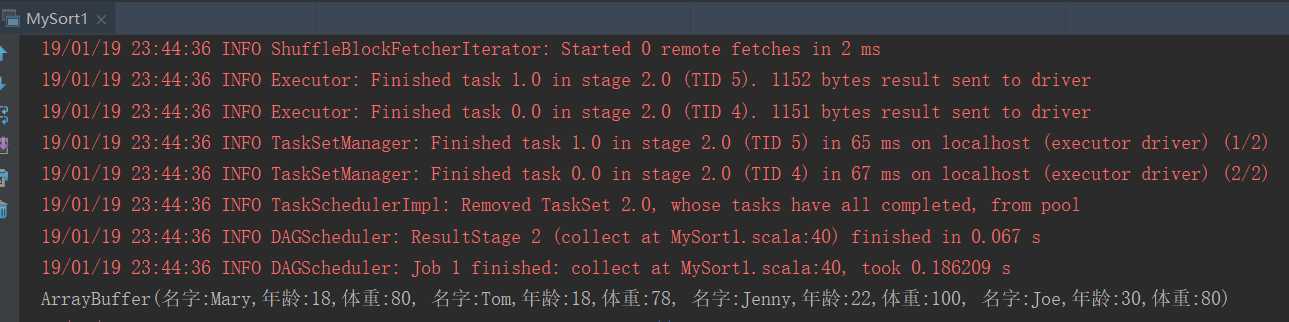 二、
二、
二、自定义排序规则-模式匹配
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD object MySort2 { def main(args: Array[String]): Unit = { //1.spark程序的入口 val conf: SparkConf = new SparkConf().setAppName("MySort2").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) //2.创建数组 val girl: Array[String] = Array("Mary,18,80","Jenny,22,100","Joe,30,80","Tom,18,78") //3.转换RDD val grdd1: RDD[String] = sc.parallelize(girl) //4.切分数据 val grdd2: RDD[(String, Int, Int)] = grdd1.map(line => { val fields: Array[String] = line.split(",") //拿到每个属性 val name = fields(0) val age = fields(1).toInt val weight = fields(2).toInt //元组输出 (name, age, weight) }) //5.模式匹配方式进行排序 val sorted = grdd2.sortBy(s => Girl2(s._1, s._2, s._3)) val r = sorted.collect() println(r.toBuffer) sc.stop() } } //自定义类 scala Ordered case class Girl2(val name: String, val age: Int, val weight: Int) extends Ordered[Girl2] { override def compare(that: Girl2): Int = { //如果年龄相同 体重重的往前排 if(this.age == that.age){ //如果正数 正序 负数 倒序 -(this.weight - that.weight) }else{ //年龄小的往前排 this.age - that.age } } override def toString: String = s"名字:$name,年龄:$age,体重:$weight" }
结果:
 三、
三、
三、自定义排序规则-隐式转换
import org.apache.spark.{SparkConf, SparkContext} import org.apache.spark.rdd.RDD //定义一个专门处理隐式的类 object ImplicitRules { //定义隐式规则 implicit object OrderingGirl extends Ordering[Girl1]{ override def compare(x: Girl1, y: Girl1): Int = { if(x.age == y.age){ //体重重的往前排 -(x.weight - y.weight) }else{ //年龄小的往前排 x.age - y.age } } } } object MySort3 { def main(args: Array[String]): Unit = { //1.spark程序的入口 val conf: SparkConf = new SparkConf().setAppName("MySort3").setMaster("local[2]") val sc: SparkContext = new SparkContext(conf) //2.创建数组 val girl: Array[String] = Array("Mary,18,80","Jenny,22,100","Joe,30,80","Tom,18,78") //3.转换RDD val grdd1: RDD[String] = sc.parallelize(girl) //4.切分数据 val grdd2 = grdd1.map(line => { val fields: Array[String] = line.split(",") //拿到每个属性 val name = fields(0) val age = fields(1).toInt val weight = fields(2).toInt //元组输出 (name, age, weight) }) import ImplicitRules.OrderingGirl val sorted = grdd2.sortBy(s => Girl1(s._1, s._2, s._3)) val r = sorted.collect() println(r.toBuffer) sc.stop() } } //自定义类 scala Ordered case class Girl1(val name: String, val age: Int, val weight: Int)
结果:

标签:obj this 入口 nbsp 匹配 .com ted 定义排序 inf
原文地址:https://www.cnblogs.com/areyouready/p/10293782.html