标签:网络 关键字 就是 之间 相关度 二分法 自然语言 多个 sha
先整体上看一下Lucene的架构设计图(见下图),先看上层应用,首先是信息采集的过程,文件系统、数据库、万维网以及手工输入的文件都可以作为信息采集的对象,也是要搜索的文档的来源,采集万维网上的信息一般使用网络爬虫。完成信息采集之后到Lucene层面有两大任务:索引文档和搜索文档,索引文档的过程完成由原始文档到倒排索引的构建过程,搜索文档用以处理用户查询。应用层的第三部分就是用户接口,用户输入查询关键字,Lucen完成文档搜索任务,经过分词、匹配、评分、排序等一系列过程之后返回用户想要的文档。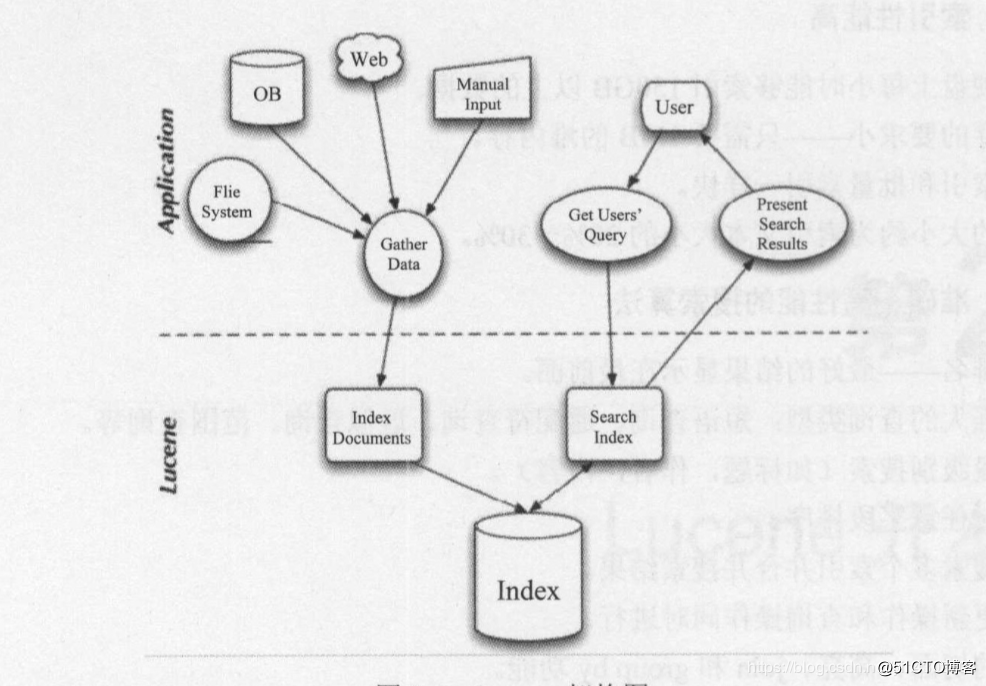
? ? ? ?一次完整的搜索从用户输入要查询的关键词开始到系统根据用户输入的关键字返回相关信息。一次检索大致可分为4步:
? ? ?第一步:查询分析
? ? ?正常情况下用户输入正确的查询,例如输入“python”这个关键词,用户输入正确完成一次搜索,但是搜索需求通常都是全开放的,任何的用户需求都是有可能的,很大一部分还是非常口语化和个性化的,有时候还会存在拼写错误,假如不小心把”python“达成“pythno”,这个时候就需要用自然语言处理技术来做拼写纠错等处理,以正确理解用户需求。
? ? ?第二步:分词技术
? ? 这一步利用自然语言处理技术将用户输入的查询语句进行分词,如标准分词会把“lucene,全文检索框架”分成lucene|全|文|检|索|框|架,空格分词会分成:lucene,|全文检索框架|,二分法会变成:lucene|全文|文检|检索|索框|框架|,还有简单分词等多种分词方法。
? ? ?第三步:关键字检索
? ? 提交关键词后在倒排索引库中进行匹配,倒排索引就是关键词和文档之间等对应关系,就像给文档贴上标签。比如文档集中含有lucene关键词的有文档1,文档6,文档9,含有全文检索的有文档1、文档6,那么做与运算,同时含有lucene和全文检索的文档的就是1和6,在实际的搜索中会有更复杂的文档匹配模型。
? ? ?第四步:搜索排序
? ? ?对多个相关文档进行相关度计算、排序,返回给用户检索结果。
? ? ?
标签:网络 关键字 就是 之间 相关度 二分法 自然语言 多个 sha
原文地址:http://blog.51cto.com/13971805/2344838