标签:stat tle fda str lxml dac 成功 write route
用python爬取知乎的热榜,获取标题和链接。
环境和方法:ubantu16.04、python3、requests、xpath
1.用浏览器打开知乎,并登录
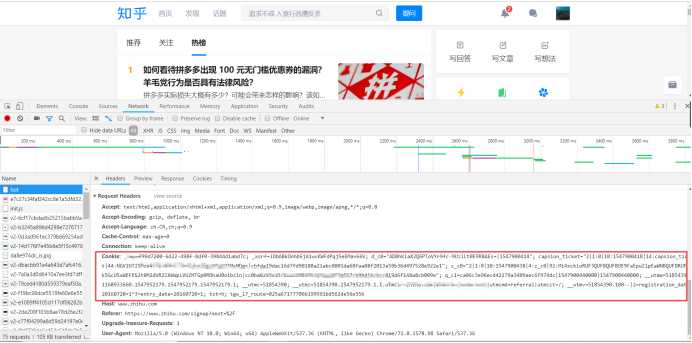
2.获取cookie和User—Agent
3.上代码
1 import requests 2 from lxml import etree 3 4 def get_html(url): 5 headers={ 6 ‘Cookie‘:‘‘, 7 #‘Host‘:‘www.zhihu.com‘, 8 ‘User-Agent‘:‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36‘ 9 } 10 11 r=requests.get(url,headers=headers) 12 13 if r.status_code==200: 14 deal_content(r.text) 15 16 def deal_content(r): 17 html = etree.HTML(r) 18 title_list = html.xpath(‘//*[@id="TopstoryContent"]/div/section/div[2]/a/h2‘) 19 link_list = html.xpath(‘//*[@id="TopstoryContent"]/div/section/div[2]/a/@href‘) 20 for i in range(0,len(title_list)): 21 print(title_list[i].text) 22 print(link_list[i]) 23 with open("zhihu.txt",‘a‘) as f: 24 f.write(title_list[i].text+‘\n‘) 25 f.write(‘\t链接为:‘+link_list[i]+‘\n‘) 26 f.write(‘*‘*50+‘\n‘) 27 28 def main(): 29 url=‘https://www.zhihu.com/hot‘ 30 get_html(url) 31 32 main() 33 34 import requests #用requests方式获取 35 from lxml import etree 36 37 def get_html(url): 38 ‘‘‘get_html获取源代码 39 ‘‘‘url:为知乎的网址 40 headers={ 41 ‘Cookie‘:‘tgw_l7_route=73af20938a97f63d9b695ad561c4c10c; _zap=f99d7200-6422-498f-8df0-39844d1abd7c; _xsrf=iDbABkOnhb6jA1wvKWFdPqjSeEMav66V; d_c0="ADBhKiaX2Q6PToVYr9fc-9UzlLt0E9RBAEs=|1547900414"; capsion_ticket="2|1:0|10:1547900418|14:capsion_ticket|44:NGVlNTI5Mzk4YTEzNDhlZTk4ZjkxZDg1YTg1OTMxMDg=|cbfda19dac16d7fd90188a21abc0001da68faa88f2013a59b36d497528e922e1"; z_c0="2|1:0|10:1547900438|4:z_c0|92:Mi4xckloRUF3QUFBQUFBOE9FaEpwZlpEaWNBQUFDRUFsVk5GcU5xWEFES2t0M2dVR2lXbWpLVUZHTGp0RDhaU0o1bzln|cc0ba8245e1572aac608d462e9aaabf1b817cb9bd16cbcc819d6f148a8cb009e"; tst=r; q_c1=ca06c3e96ec442179a3409aec6f974dc|1547900440000|1547900440000‘, 42 #‘Host‘:‘www.zhihu.com‘, 43 ‘User-Agent‘:‘Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/50.0.2661.102 Safari/537.36‘ 44 } 45 46 r=requests.get(url,headers=headers) #获取网页源码 47 48 if r.status_code==200: #判断状态码是否为200,即判断是否成功获取原网页 49 deal_content(r.text) #调用函数处理网页内容 50 51 def deal_content(r): 52 ‘‘‘ 53 deal_content()处理网页内容,并写入txt文件中 54 r为传入参数,是网页内容 55 相关内容写入zhihu.txt中 56 ‘‘‘ 57 html = etree.HTML(r) #将网页内容转换为lxml格式 58 title_list = html.xpath(‘//*[@id="TopstoryContent"]/div/section/div[2]/a/h2‘) #获取标题 59 link_list = html.xpath(‘//*[@id="TopstoryContent"]/div/section/div[2]/a/@href‘) #获取连接 60 for i in range(0,len(title_list)): 61 #print(title_list[i].text) 62 #print(link_list[i]) 63 with open("zhihu.txt",‘a‘) as f: 64 f.write(title_list[i].text+‘\n‘) 65 f.write(‘\t链接为:‘+link_list[i]+‘\n‘) 66 f.write(‘*‘*50+‘\n‘) 67 68 def main(): 69 url=‘https://www.zhihu.com/hot‘ 70 get_html(url) 71 72 main()
4.爬取结果
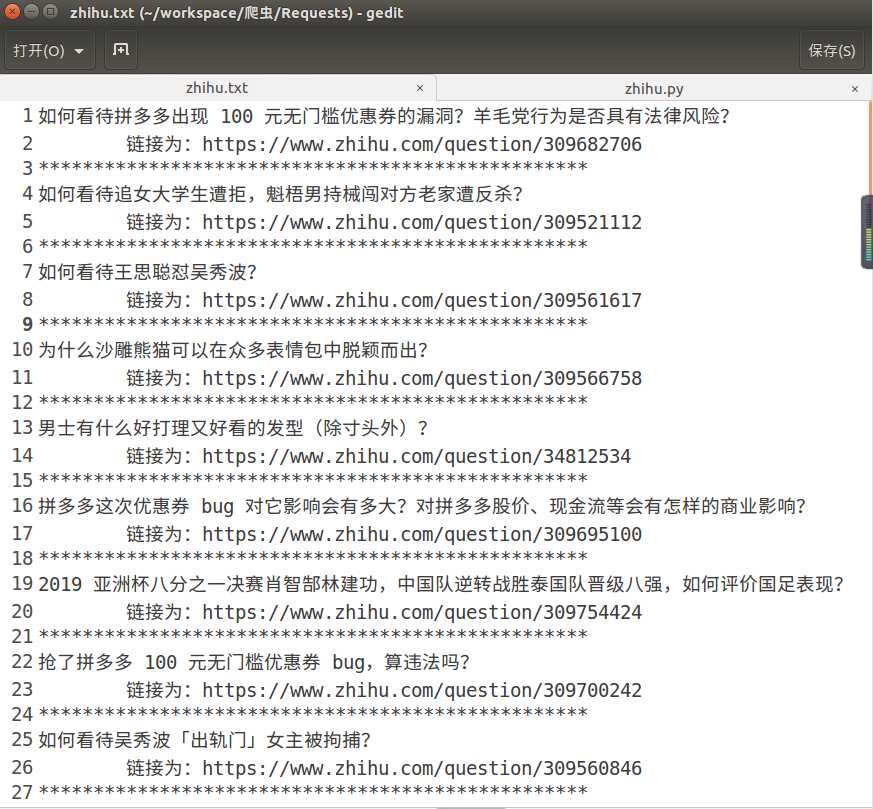
爬取知乎热榜标题和连接 (python,requests,xpath)
标签:stat tle fda str lxml dac 成功 write route
原文地址:https://www.cnblogs.com/emmm/p/10297824.html