标签:lib 运行 call des self contains @class tree .com
1.环境及版本
python3.7.1+scrapy1.5.1
2.问题及错误代码详情
优先贴上问题代码,如下:
import scrapy from scrapy.linkextractors import LinkExtractor class MatExamplesSpider(scrapy.Spider): name = ‘mat_examples‘ # allowed_domains = [‘matplotlib.org‘] start_urls = [‘https://matplotlib.org/gallery/index.html‘] def parse(self, response): le = LinkExtractor(restrict_xpaths=‘//a[contains(@class, "reference internal")]/@href‘) links = le.extract_links(response) print(response.url) print(type(links)) print(links)
运行代码后报错如下:
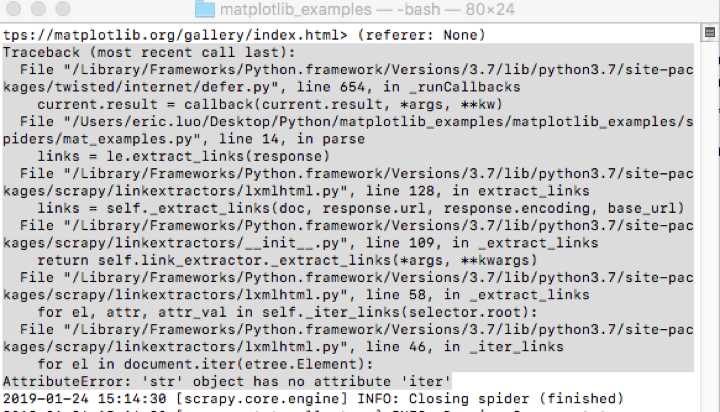
Traceback (most recent call last):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/twisted/internet/defer.py", line 654, in _runCallbacks
current.result = callback(current.result, *args, **kw)
File "/Users/eric.luo/Desktop/Python/matplotlib_examples/matplotlib_examples/spiders/mat_examples.py", line 14, in parse
links = le.extract_links(response)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 128, in extract_links
links = self._extract_links(doc, response.url, response.encoding, base_url)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/__init__.py", line 109, in _extract_links
return self.link_extractor._extract_links(*args, **kwargs)
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 58, in _extract_links
for el, attr, attr_val in self._iter_links(selector.root):
File "/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/site-packages/scrapy/linkextractors/lxmlhtml.py", line 46, in _iter_links
for el in document.iter(etree.Element):
AttributeError: ‘str‘ object has no attribute ‘iter‘
出现错误后自检代码并未发现问题,上网查找也未发现相关的问题;于是将代码改成(restrict_css)去抓取数据,发现是能正常获取到数据的,于是改回xpath;但这次先不使用linkextractor,采用scrapy自带的response.xpath()方法去获取对应链接所在标签的href属性值;发现这样是可以获取到正常的数据的:
即将:
le = LinkExtractor(restrict_xpaths=‘//a[contains(@class, "reference internal")]/@href‘) links = le.extract_links(response)
改成:
links = respon.xpath(‘//a[contains(@class, "reference internal")]/@href‘).extract()
然后又发现报错是: ‘str‘ object has no attribute ‘iter‘
而正常返回的links数据类型应该是list才对,不应该是str,所以猜测可能是由于规则写错了导致获取的数据不是list而变成了一个不知道的str;这样针对性的去修改restrict_xpaths中的规则,最后发现去掉/@href后能够获取我所需要的正常的数据;
即将:
le = LinkExtractor(restrict_xpaths=‘//a[contains(@class, "reference internal")]/@href‘)
改成:
le = LinkExtractor(restrict_xpaths=‘//a[contains(@class, "reference internal")]‘)
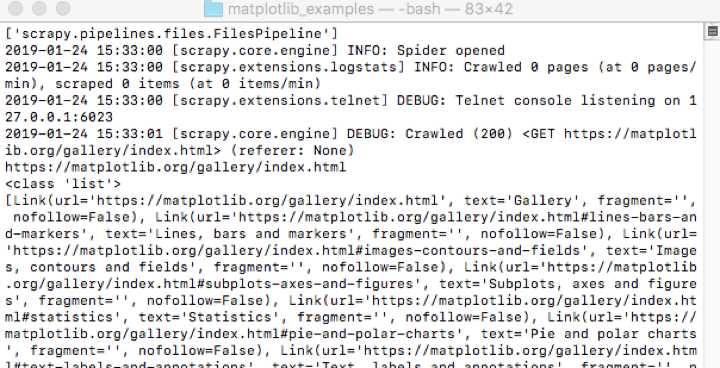
重新运行代码,发现成功获取数据,输出结果如下截图所示:
*****爬虫初学者,不喜勿喷*****
Python之scrapy linkextractors使用错误
标签:lib 运行 call des self contains @class tree .com
原文地址:https://www.cnblogs.com/dluo/p/10315305.html